
Memory consolidation is the leading theory for why humans dream. While you sleep, your hippocampus replays the day, decides what matters, and weaves it into everything you already know.
Nightmares serve a purpose too, stress-testing the brain’s model of the world and surfacing conflicts before they matter. Omni Aura did not set out to build an artificial hippocampus when designing long-term memory for Ditto (Subnet 118), but they arrived at the same problem the brain solves during sleep.
The system they built, called the dreaming pipeline, treats merge conflicts and fragmented nodes not as bugs but as the signal the system uses to get smarter.
What Happens After a Conversation Ends

About thirty seconds after a conversation closes, the pipeline executes a tight sequence:
a. Re-reads the conversation and asks an LLM to extract durable topics.
b. Embeds those topics and searches for near-duplicates across everything the user has discussed.
c. Stitches the new memory into a graph that can be searched and queried.
Three of the seven retrieval signals in Ditto’s Composite MLP v2 ranker read directly from this graph.
A Graph Shaped Like an Index, Not a Textbook
Most knowledge graphs connect subjects to other subjects with weighted edges, forcing designers to decide at write time which subjects are related and how strongly.
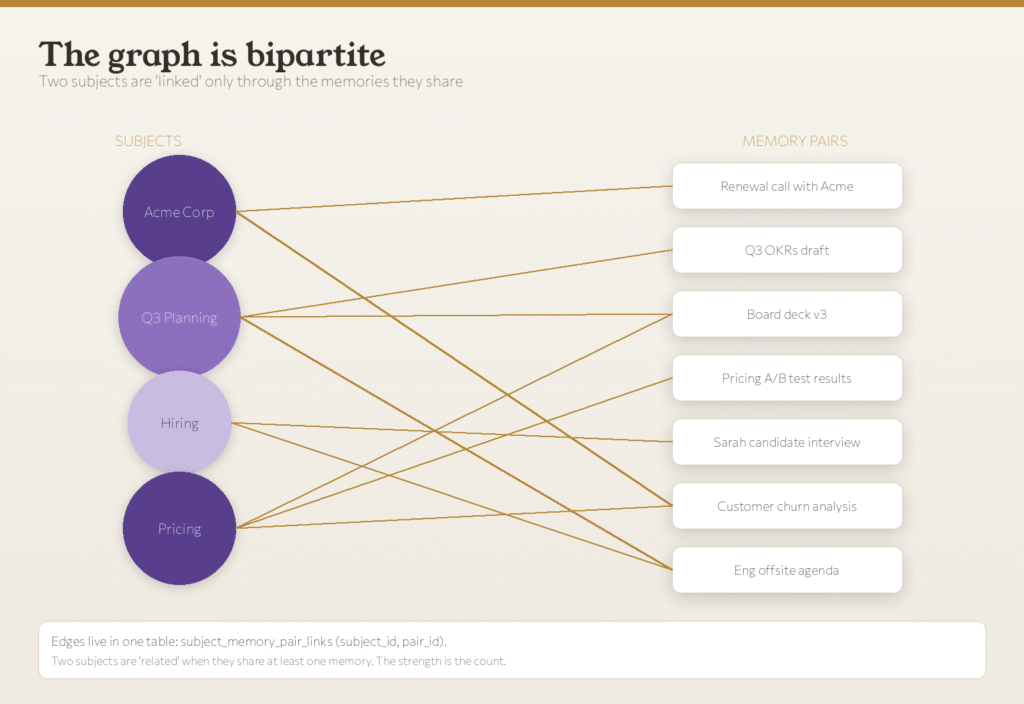
Ditto’s graph is bipartite instead: two kinds of nodes (subjects and memory pairs) and one kind of edge between them. Two subjects are “related” when they show up in the same memory, and the strength is just the count of shared memories.
The tradeoffs this design produces:
a. One Source of Truth: Every “is X related to Y” question is a single SQL join.
b. Cheap Updates: Adding a memory means inserting one row per subject, never updating an edge.
c. Honest about Uncertainty: The graph never claims percentages, it just says “you’ve talked about both in eight memories.”
The entire knowledge graph lives in one Postgres junction table.
The Only Interesting Decision Is When to Merge
When the LLM extracts “Q3 OKR review,” the system decides whether to create a new node or attach it to last month’s “Q3 Planning.”
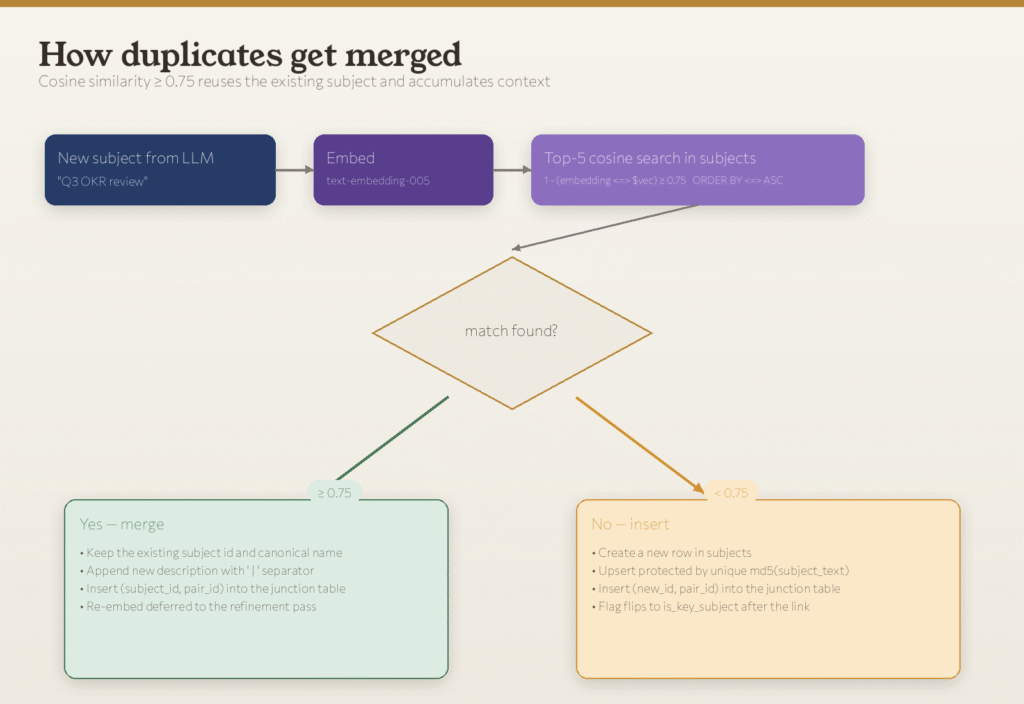
The call runs on cosine similarity with a single threshold at 0.75:
a. Above 0.85, the graph fragments. Related Q3 subjects become separate nodes when they should be one.
b. Below 0.65, the graph collapses. Distinct concepts merge into generic blobs and the structure stops being useful.
When merges happen, the canonical name stays and the new description gets appended with “|” separator after which the refinement pass can be found later.
Why the Nightmares Are the Point
Every wrong merge is a nightmare, and Ditto resolves them in two ways:
a. The Acute Nightmare: The team once shipped a bug where they sorted by cosine distance but compared against a similarity threshold. Backwards, every user’s graph collapsed into a single mega-node containing every subject they had ever discussed. They caught it, rebuilt every graph from scratch, and locked the threshold at 0.75.
b. The Everyday Nightmares: Even with the threshold right, merge conflicts happen constantly. These small nightmares are exactly what triggers the refinement pass. Without them, refinement would have nothing to do.
The nightmares are the input, and the dreams are the output.
How the Graph Refines Itself
After a few weeks of use, some subjects accumulate junk-drawer descriptions full of pipe-separated fragments. Every sync run, the pipeline queries for those subjects, batches them in groups of fifty, and runs fifteen LLM workers in parallel to synthesize a concise name and a rolling narrative summary.
The cleaned output replaces the canonical name and description, and the system re-embeds the result so the next memory dedupes against the consolidated vector rather than the fragmented one.
The graph grows by dreaming through its conflicts until they resolve into something cleaner.
How Retrieval Uses the Graph

When a user asks Ditto a question, the ranker pulls about fifty candidate memories from pgvector and scores each on seven signals. Three come straight from the junction table:
a. Topic Prevalence: Memories tied to heavily-discussed subjects rank higher when the query is vague.
b. Topic Semantic Match: Let a long memory with one buried phrase still surface, because that phrase became a subject.
c. Topic Clustering: When eight of fifty candidates share a subject, that is almost certainly what the user is asking about.
Those three signals were the biggest contributor to the recall jump from v1 to v2 of the ranker.
Why It Is Called Dreaming
The first version ran inline during chat save. It was slow, it blocked responses, and it made retrieval suspiciously good only for the messages just sent, since older history had not been re-evaluated.
Moving it off the hot path into a background consolidation process was the fix. The hippocampus replays during sleep. Ditto’s pipeline replays between conversations. Neither requires attention, and both make the next retrieval better.
The Bigger Picture
Ditto built a system that treats imperfection as fuel rather than failure. The merge conflicts, fragmented descriptions, and mega-node disaster all became part of how the graph learned to organize itself.
Most knowledge graph architectures try to eliminate ambiguity at write time. Ditto’s preserve it, lets it accumulate, and uses the resulting friction to push the system toward something sharper.
The agent’s nightmares are not bugs to debug, they are the signal that something worth resolving is happening, and the dreams that follow are what make the next conversation better than the last.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Enjoyed this article?
Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox — every morning before markets open.



Be the first to comment