

Jon Durbin, a core contributor and backend developer at Chutes (SN64), has published one of the company’s most substantive operational updates since launch.

The piece covers where the platform stands today, the shifts in the GPU market that have changed the playbook, and a new decentralized training method the team has been developing.
The headline thesis is that Chutes has shifted from optimizing for raw throughput to closing the gap between revenue and miner emissions, and that the work happening on the training side may end up being the more consequential bet.
Where Chutes Stands
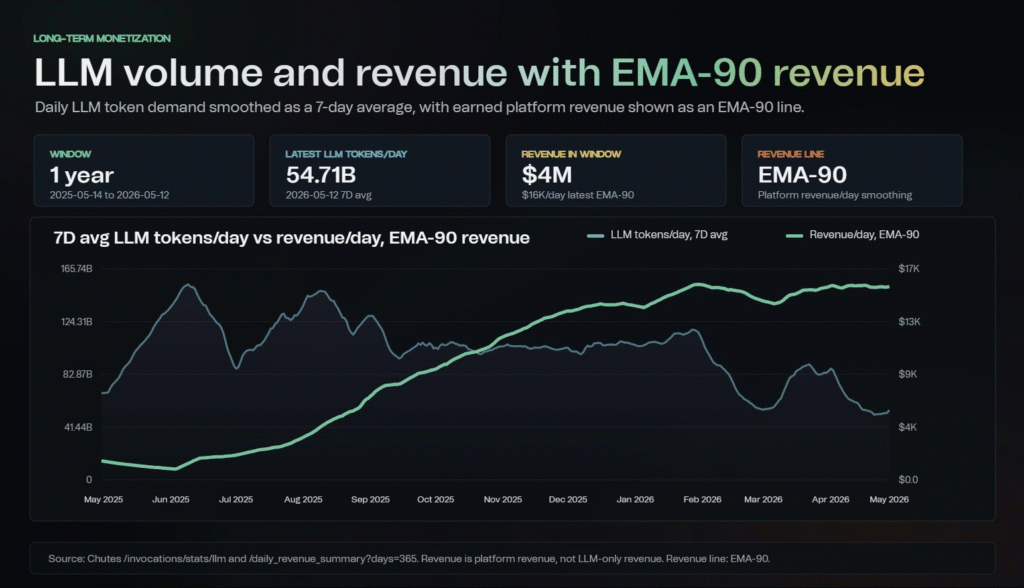
Chutes proved its scale by hitting roughly 160 billion tokens served in a single day on permissionless compute, at a time when H200 nodes were accessible at around $0.77 per hour through miner emissions.
That market has largely disappeared, with Hopper and Blackwell GPUs now scarce, prices materially higher, and longer commitment windows becoming standard. Inventory has been cut by roughly two-thirds since December, but revenue has held stable and grown in recent months.
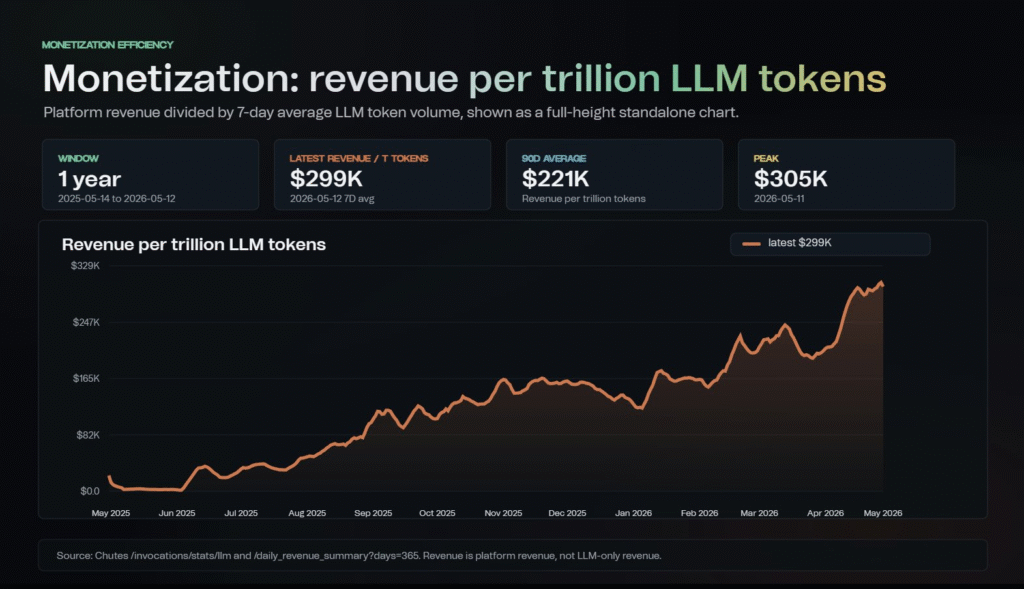
Token volume is down, but dollar-per-token revenue, which is the metric that actually matters, is trending up.
The Revenue Levers
The plan for closing the supply-demand gap runs across five fronts:
a. New compute providers being onboarded to expand network capacity.
b. A mining pool feature in development to stabilize collective compute capacity.
c. Price increases to align with prevailing GPU market rates.
d. Model purging to remove the long tail of unprofitable models and consolidate supply around what users actually demand.
e. Private Chutes with hourly rather than per-token pricing, offering a more predictable revenue path for consistent workloads.
Parallax
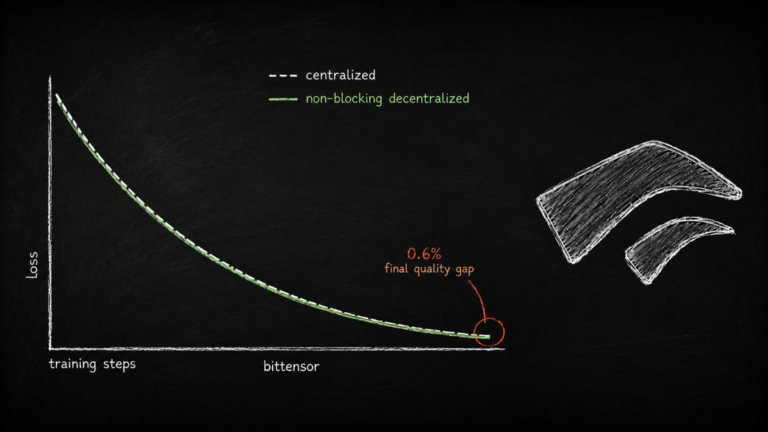
Jon has been personally developing Parallax, a new decentralized training method built specifically for Mixture-of-Experts models.
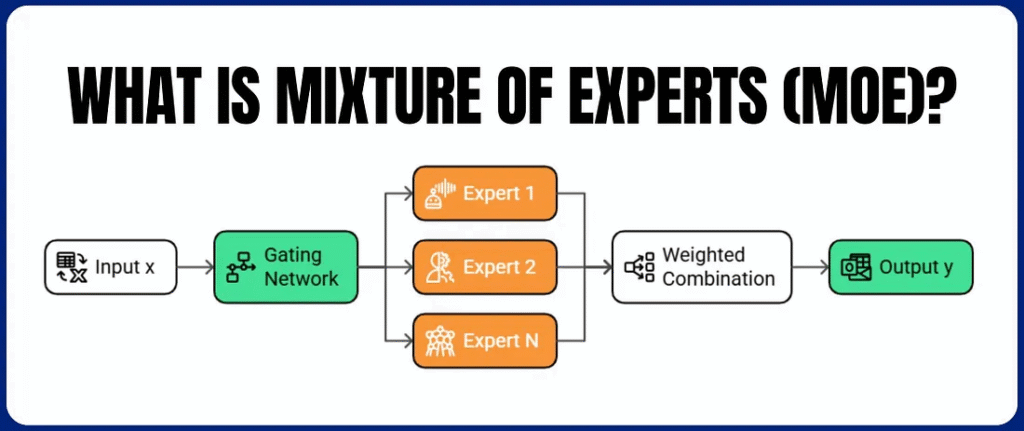
The intent is not for Chutes to pivot into training, but to produce efficient models that reduce global compute pressure rather than add to it. Early experimental results are notable:
a. A 20 billion parameter run over the public internet using single GPUs per composer hit a roughly 1.5% performance gap against traditional end-to-end training, expected to close with additional training steps.
b. The algorithm cuts per-token FLOPS per island by 3.4x or more while maintaining over 99% forward accuracy.
c. An extreme mode allows routed experts to run on commodity GPUs or even consumer hardware in exchange for moderate bandwidth.
The end goal is matching the quality of frontier MoE models like GLM-5.1 or Kimi-K2.6 on a single H200. A whitepaper and preliminary results are expected to follow in the coming weeks.
Inference and the TEE (Trusted Execution Environment) Migration
In parallel, Chutes is pushing on inference performance through secure prefix cache optimizations, a near-complete research collaboration with Professor Juncheng Yang at Harvard on cache hit rates and routing methodologies, and continuous SGLang and vLLM engine updates.
Underneath the optimization work, the team is accelerating the migration to a fully TEE-only infrastructure stack.
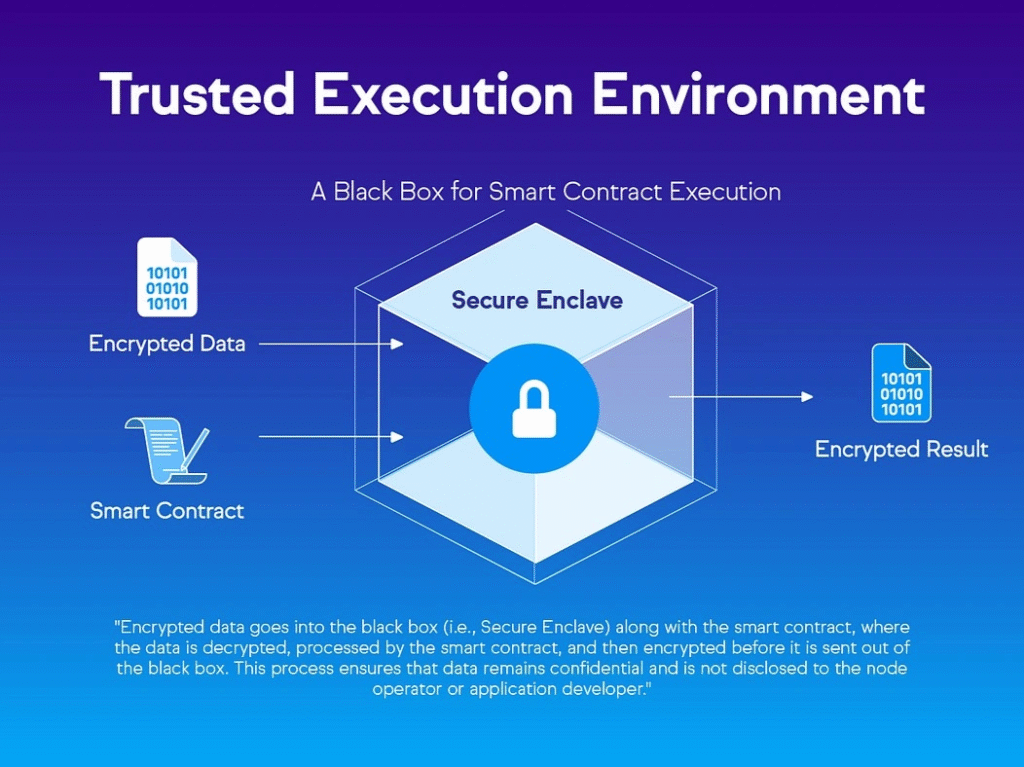
Some short-term instability is expected as TEE-incompatible models drop off the platform, but the privacy, security, and validation benefits justify the trade.
Conclusion
The update is one of the cleaner operational reads on what running a serious Bittensor subnet looks like in a tightening compute market. Chutes has already proven it can deliver scale, and the work now is converting that into a sustainable business that funds the longer-term research, particularly Parallax, which may end up mattering more than the inference platform itself.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Enjoyed this article?
Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox — every morning before markets open.


Be the first to comment