
")
On May 12, Connito (Bittensor subnet 102) released its V1 whitepaper, and the timing feels deliberate. Decentralized AI training is hitting its stride: SN3 (Teutonic) just proved the network can handle base-model training at 80B+ parameters. Connito is staking out the next layer, a specialized system for adapting and composing open models through a Mixture-of-Experts (MoE) architecture.
Quick primer: What is Mixture-of-Experts?
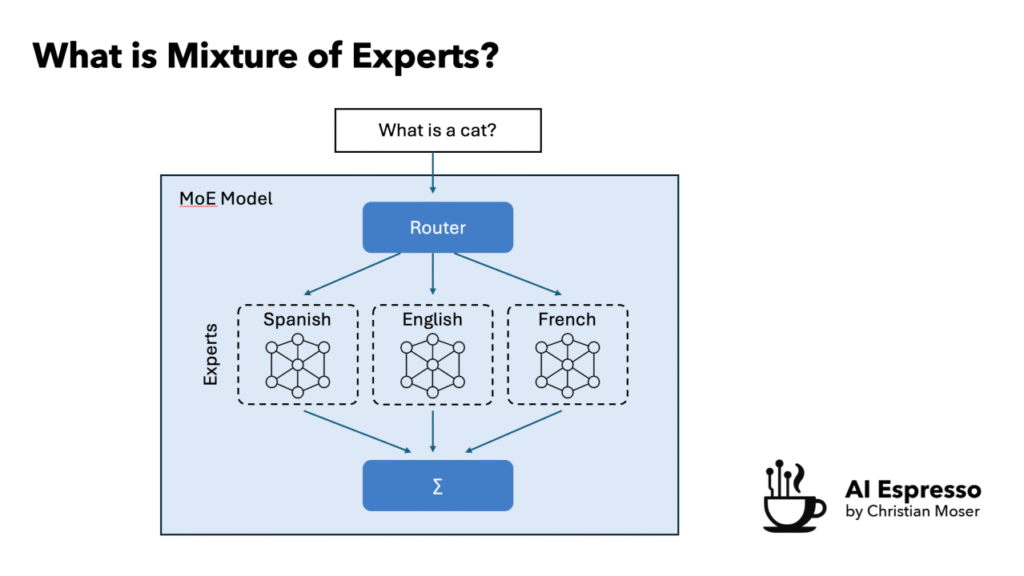
Mixture-of-Experts (MoE) is an architecture where a model is split into many smaller specialized sub-networks, the “experts”, instead of one giant dense network where every parameter fires on every input. A lightweight router sits in front of them and decides which experts to activate for a given query.
The payoff: you can scale total parameters massively (hundreds of billions) while only using a small fraction at inference time. You get the capacity of a huge model at the compute cost of a much smaller one. It’s the architecture behind models like Mixtral and (reportedly) GPT-4.
For decentralized training, MoE is a natural fit. Experts are modular by design, which means the work can actually be split across a network instead of demanding one operator hold everything.
What is Connito?
Connito is a decentralized framework for improving open foundation models via composable MoE adaptation.
The core insight: instead of forcing miners to fine-tune entire massive models, which demands huge compute and risks catastrophic forgetting, Connito breaks models into sparse expert subsets.
Miners train only the experts relevant to a specific domain (math, code, legal, etc.). A learned router then dynamically directs queries to the best experts at inference time.
The result is a network of domain-optimized specialists that compose into powerful modular systems. No central operator. No monolithic GPU cluster. No single point of failure. It turns open-model improvement into a genuine distributed market for expert-level intelligence.
The team behind it
The whitepaper is authored by Isabella Liu and George Kim.
Isabella is a founding ML engineer at Bittensor, one of the earliest technical contributors to the core protocol. Her involvement has generated real excitement in the TAO community; prominent voices including Shib (co-founder of Opentensor and Crucible Labs) have publicly highlighted her background and expressed confidence in the team. George Kim brings full-stack development and AI research depth.
In a space filled with new teams, having day-one Bittensor builders gives Connito immediate credibility.
What makes the subnet technically interesting
Four mechanisms do the heavy lifting:
Sparse expert training + Frozen Routing Anchor. Only a small fraction of experts gets updated per task, and the router stays frozen during adaptation. This solves a classic alignment problem in decentralized training where workers optimize against a stable shared reference instead of diverging. Compute, communication overhead, and VRAM drop by roughly 90% versus dense training.
Proof-of-Loss (PoL) validation. Validators score miner updates based on actual loss reduction on held-out data. Only genuinely useful improvements get rewarded.
Commit-Reveal scheme. Miners commit a hash of their work before seeing the validation set, which kills copy-paste and gaming attacks.
Composable expert market. Validated experts become reusable modules. You can mix and match them across models and domains, creating a marketplace for specialized intelligence. It pairs cleanly with base-training subnets like SN3: train the foundation once, then adapt and compose experts forever.
The net effect: 100B+ parameter MoE models become practical in a fully decentralized setting — by distributing the work intelligently instead of asking everyone to shoulder the full load.
Miner and validator roles
Miners receive a target expert subset, train it locally on their data partition using DiLoCo-style optimization, commit a checkpoint hash, and reveal it once validators clear it. Per-miner requirements stay low since you don’t need to hold the whole model.
Validators distribute expert tasks, run PoL scoring on held-out data, rank submissions, and integrate the best updates into the global MoE via pseudo-gradients. They enforce quality and security at every step.
How the community is reacting
Strongly positive and energetic. Early voices are calling it an “exciting new subnet” and labeling the whitepaper drop legendary. The technical excitement centers on the Frozen Routing Anchor + PoL + Commit-Reveal stack. These solve real alignment and copy-resistance issues that most decentralized training proposals simply hand-wave past.
Builders are especially bullish on the SN3 + Connito synergy: SN3 handles base training, Connito handles expert adaptation and composition. Together, they form a complete decentralized training pipeline. Many see Connito as one of the more technically credible attempts at scaling the training layer subnet-by-subnet.
What’s next
- Whitepaper is live at connito.ai/whitepaper
- Dashboard drops May 26
If you’re in the TAO ecosystem and care about the infrastructure layer for frontier AI, this is one to watch closely.
100B+ parameters, fully decentralized. Bold claim or buildable reality? Drop your take below.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.

Be the first to comment