
")
A few hours ago, Const dropped a line in the Subnet 3 Discord that most people will scroll past:
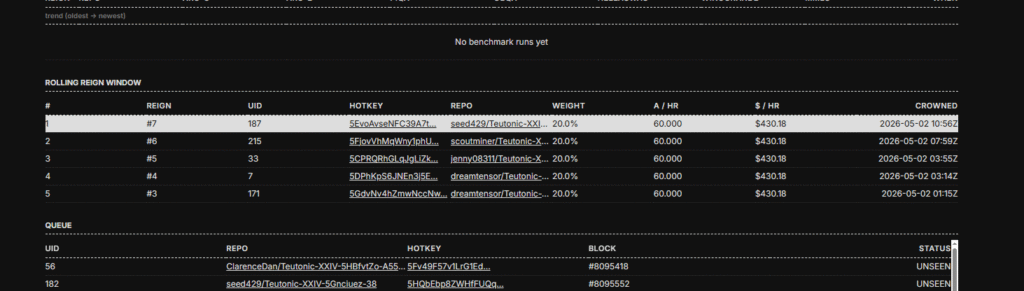
Reactions piled on (🔥, 🚀, 💯, 👀, 🐐) his remark. The duel history in the screenshot above shows a fresh challenger dethroning the king. Business as usual on Teutonic, except the architecture line item just changed.
A 24B model is a meaningful jump from the 1B Gemma3 seed king Teutonic launched with on April 13. But the more interesting word in that sentence isn’t “24B.” It’s “looped.”
If the Mythos speculation is right, Const is now training, in the open, on a decentralized network, the same class of architecture that Anthropic appears to be running in production behind one of the strongest reasoning models on the market.
That’s the story.
What “looped transformer” means
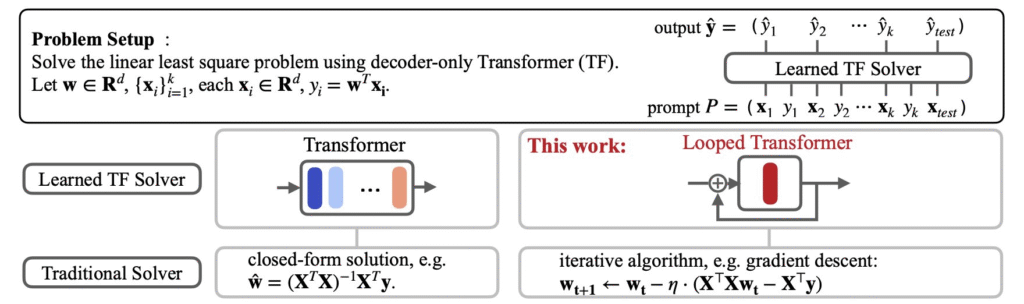
The pitch is mechanically simple. A standard transformer stacks N unique layers, each with its own weights. A 70B model has 70B distinct parameters arranged in a fixed pipeline. A looped transformer, also called a Recurrent-Depth Transformer (RDT), does something different. It uses a smaller block of weights and runs it multiple times within a single forward pass. Same weights, multiple passes.
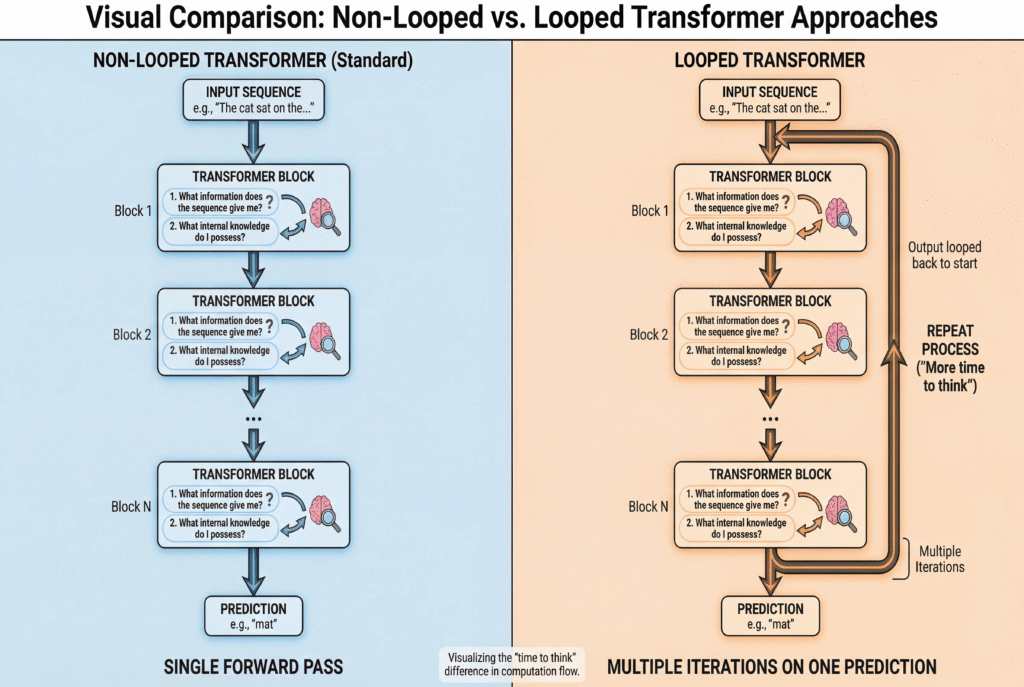
So instead of scaling reasoning by making the model bigger, you scale it by letting the model spend more compute on the same problem. Reasoning depth becomes an inference-time knob (run more loop iterations, do more thinking) rather than something you have to bake in by adding parameters at training time.
The idea isn’t new. The Universal Transformer paper from 2018 sketched the same direction. What’s changed in the last 18 months is that the empirical results have started to look real:
- Saunshi et al. (Google Research, ICLR 2025) showed that a k-layer transformer looped L times can approach the performance of a much deeper kL-layer model on reasoning tasks like math, induction, and addition. The intuition shows that a lot of reasoning isn’t bottlenecked by parameter count, but by steps of computation.
- ByteDance’s Ouro work (October 2025) trained 1.4B and 2.6B looped models that reportedly perform like 4B–12B-class standard transformers on several benchmarks. Their worked showed that gains don’t come from storing more knowledge, they come from getting better at using what’s already known.
- Pappone et al. (April 2026) pushed on the implicit-reasoning angle in their “Loop, Think, & Generalize” paper. Train a looped model on shallow reasoning chains, and at inference time it can extend to deeper chains by simply running more loops. This is only possible with looped transformers.
Then there’s Mythos.
The Mythos question

For the sake of overview, Claude Mythos is an advanced, unreleased frontier AI model by Anthropic, restricted to “Project Glasswing” partners (e.g., Google, Microsoft, NVIDIA) due to extreme, human-surpassing cybersecurity capabilities. It can autonomously discover and exploit complex “zero-day” software vulnerabilities in browsers, OSs, and infrastructure.
Anthropic has not published an architecture paper for Claude Mythos. They’ve called the internals “research-sensitive.” So everything we say below is speculation built on benchmark behavior, but the speculation is well-formed enough that several researchers have taken it seriously.
The best benchmark to prove Mythos’ monster capabilities is GraphWalks BFS. On this benchmark that tests breadth-first search over a graph at 256K–1M tokens, Mythos scores around 80%. GPT-5.4 sits at roughly 21%. Opus 4.6 lands near 39%. That’s not a scaling-law gap. Scaling improves benchmarks fairly uniformly. A nearly 4x spike on one specific iterative-graph task is the signature of an architecture with the right inductive bias for that task, and looped transformers happen to have exactly that inductive bias. They iterate. Graph traversal is iteration.
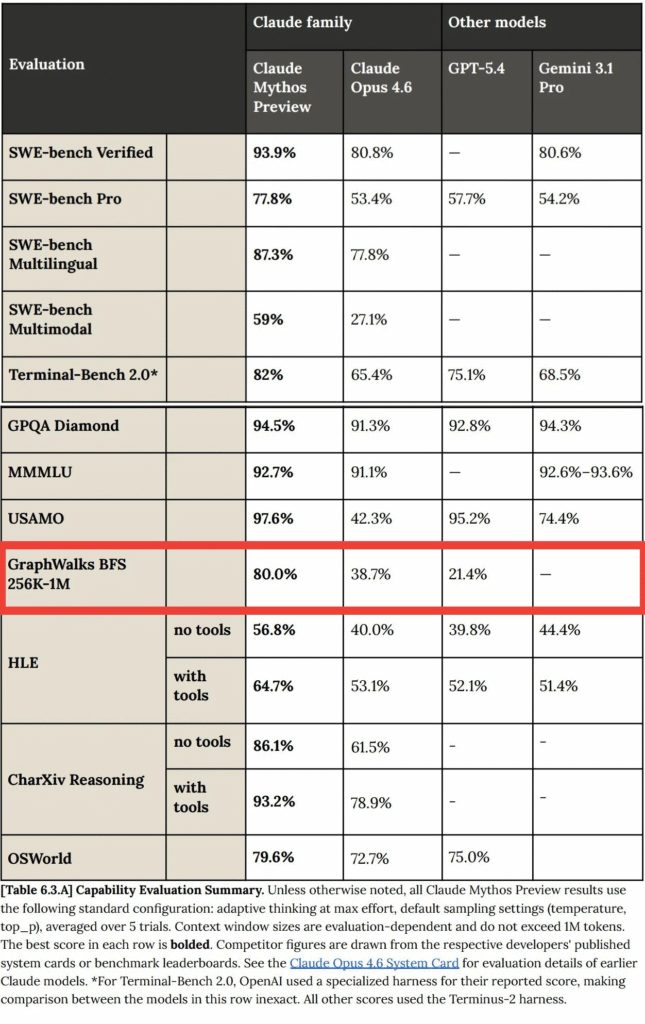
That’s the inference Kye Gomez made when he released OpenMythos, an open-source PyTorch reconstruction that bets Mythos is a Recurrent-Depth Transformer with Mixture-of-Experts feed-forward and Multi-Latent Attention, looping the same block up to sixteen times per forward pass. It’s a falsifiable hypothesis. If Anthropic ever publishes the real architecture, OpenMythos either becomes credible reverse-engineering or an instructive miss. Either way, the code runs.
These point to the convergent evidence that multiple independent research lines and at least one frontier production model are pushing in the same direction. Reasoning-as-inference-compute is a serious architectural bet.
Which brings us back to Const.
What Teutonic is doing
For anyone catching up: Subnet 3 on Bittensor was Templar, run by Covenant AI. Covenant trained a 72B model that got real industry attention (Jensen Huang and Jack Clark both publicly noticed it) and then exited the subnet, leaving roughly $10M for the community on the way out. Four days later, Const rebuilt the subnet from scratch and renamed it Teutonic.
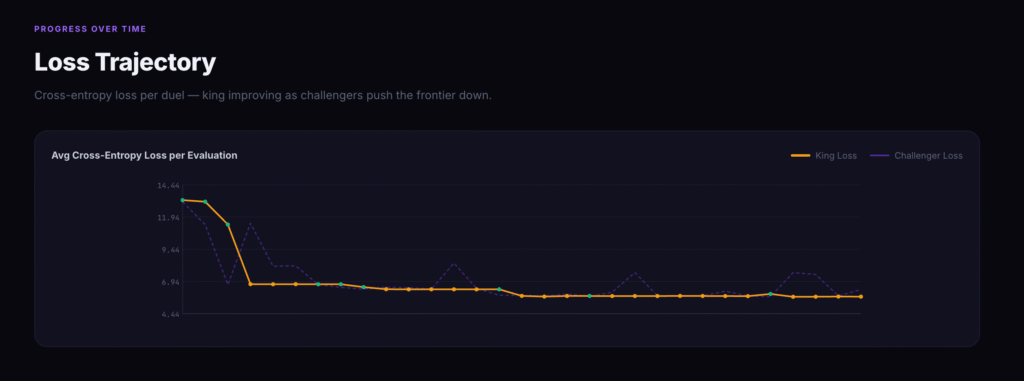
The mechanism is king-of-the-hill. Validators score every challenger model against 10,000 evaluation samples. Lowest cross-entropy loss wins the crown. The reigning king takes 100% of subnet emissions until someone dethrones it. To earn, you have to beat the king on its exact architecture.
The crucial design choice is that Teutonic is hardware-agnostic. Templar required miners to run identical hardware, which collapsed the optimization surface to “who has the most compute time.” Teutonic doesn’t care what GPU you used or what training method you ran. It only cares about your loss number. That opens up the full space: data curation, training tricks, architectural innovation. Any of those can win.
That’s the part that matters for the 24B announcement. The mechanism is specifically designed to surface architectural breakthroughs. A looped transformer entering the king-of-the-hill is exactly the kind of move it’s built for.
Where things stand
The seed king launched April 13, 2026 — a 0.9B Gemma3 model in BF16. By the time of the 24B announcement, the subnet had logged hundreds of evaluations and double-digit reign changes. Loss dropped from ~13 down into the low 5s. Perplexity is trending in one direction.
The 24B looped transformer slots between the 10B and 100B targets. And going looped at 24B isn’t a detour from the roadmap but a hedge that becomes more important as you scale. Every 10x in compute buys diminishing returns on loss. The jump from 1.1 to 0.8 nats/token is unlikely to come from “do the same thing with more GPUs.” It probably needs an architectural change. A looped architecture is one of the few well-evidenced candidates for that change.
Why this matters past Bittensor
Three things are true at the same time right now.
One: Anthropic has likely shipped a production model whose strongest capabilities, particularly long-context iterative reasoning, appear to come from looping.
Two: big research labs (Google, ByteDance, the Pappone group) have spent the last year building the empirical and theoretical case that looped transformers actually work, particularly for the kinds of multi-step reasoning that the AI field cares most about.
Three: a permissionless, decentralized network is now training a 24B looped transformer in the open, with a king-of-the-hill mechanism specifically designed to reward whoever finds the next architectural improvement.
If the first item is accurate, frontier labs are already past the proof-of-concept phase on this architecture. If the second is right, the academic foundation is solid. If the third actually scales the way Teutonic is targeting, the gap between what closed labs can do and what an open competition can do narrows considerably, and narrows fastest on exactly the architectures that benefit most from many independent attempts.
A bunch of things still have to go right. Looped models are harder to train. Stability is a known issue (the Parcae work on negative-diagonal parameterization exists precisely because every divergent run learns a spectral radius ≥ 1). Inference is slower per token. Choosing how many loops to run is itself a problem. The owner key situation on SN3 is unresolved, and Const has been clear that people shouldn’t buy the SN3 alpha token until that’s sorted.
But the architectural bet is coherent. The mechanism is built for it. And the narrative is “we’re scaling up and changing the architecture to one that the strongest closed model on the market may already be using.”
That’s the narrative worth paying attention to. Teutonic is now competing in the same architectural territory as the frontier. On Bittensor. In public. With anyone allowed to challenge.
That hasn’t really happened before.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment