
")
The AI industry has spent the last few years obsessing over model size.
Every few months, a new model arrives with a bigger context window, better benchmark scores, stronger reasoning, or more convincing demos. The story usually sounds the same: more parameters, more training data, more compute.
But after a model is trained, another problem begins.
Someone still has to serve it.
That is where the excellent research story becomes an infrastructure problem. A model can be brilliant on paper and still frustrating in practice if it is too slow, too expensive, or too difficult to deploy at scale.
Users do not experience parameter counts. They experience waiting time. Developers do not only care that a model is powerful. They care how many requests it can handle, how quickly the first token arrives, and how much GPU cost sits underneath every million tokens generated.
This is the gap Cacheon is trying to turn into a competition on top of Bittensor.
Training Got the Headlines. Inference Got the Bottleneck
The AI race is no longer just about who can train the smartest model.
It is also becoming a race for the infrastructure needed to keep those models running. That shift became clearer when Anthropic secured massive compute capacity from SpaceXAI’s Colossus 1 data center to support Claude’s growth and expand usage capacity. Even the most advanced AI labs are now fighting for the infrastructure required to serve demand at scale.

This is the part of AI most users rarely think about.
Once a model is trained, it still has to be served. It has to answer quickly, handle heavy traffic, and remain affordable enough for developers, businesses, and agents to actually use. A model can be brilliant in a benchmark and still become painful in production if every request is slow, expensive, or difficult to scale.
That is the layer Cacheon is focused on.
The Problem Cacheon Is Trying to Solve
Every time someone uses ChatGPT, Claude, Grok, or any AI product, there is a machine somewhere doing the heavy work of generating that answer. For small requests, this may not feel like a big deal. But when millions of users, developers, agents, and businesses are asking models to think, write, code, search, and reason all day, the cost of serving those models becomes massive.
This is where a hidden bottleneck appears.
The AI industry talks a lot about building smarter models, but not enough about making those models faster and cheaper to use. A powerful model is only useful if it can respond quickly, handle demand, and remain affordable for the people building on top of it.
That is the problem Cacheon is focused on.
Cacheon is trying to improve the infrastructure that serves large AI models to users.
In simple terms, Cacheon asks:
Who can make a large AI model run faster, cheaper, and more efficiently without breaking its output?
Cacheon Turns Inference Into a Competition
Cacheon, Bittensor Subnet 14, is building a live on-chain arena where miners compete to create the fastest correct inference server for a fixed open-source model. In its first version, the model is Qwen2.5-72B-Instruct. Miners submit Docker containers serving the model through an OpenAI-compatible chat completions API, while validators test each submission against a vLLM baseline on the same hardware. The fastest correct server becomes the “king,” and all subnet emissions flow to that winner until another miner beats it.

In other words, Cacheon takes one large open-source model and turns its performance into a contest. Instead of one company privately trying to optimize AI inference behind closed doors, Cacheon opens the problem to competition. Anyone who can build a better serving system can prove it. If their system is faster and still accurate, they win.
What Cacheon Is Building Toward
Cacheon starts as an inference competition, but the bigger vision is to become production infrastructure.
The first step is proving that miners can compete to improve the serving performance of a large model. Once that works, the winning systems can eventually be deployed as real inference endpoints for developers, applications, agents, and businesses.
If Cacheon succeeds, it could become a decentralized performance engine for open-source AI models. The best serving methods would be discovered through an open Bittensor competition, tested by validators, and pushed toward real-world usage.
The Team Behind Cacheon

Cacheon is also backed by a team with strong Bittensor context.
The project lists Xavier Lyu on research, Clément Blaise on infrastructure, Dera Okeke on frontend, and Cameron Fairchild as advisor. Xavier is a former Opentensor Foundation contributor and now works with Latent Holdings. Dera also works at Latent Holdings, while Cameron Fairchild is a long-time Bittensor OG and one of the more familiar names in the ecosystem.
Readers can learn more about the team here: Xavier Lyu, Clément Blaise, Dera Okeke, and Cameron Fairchild.
The Cacheon Thesis
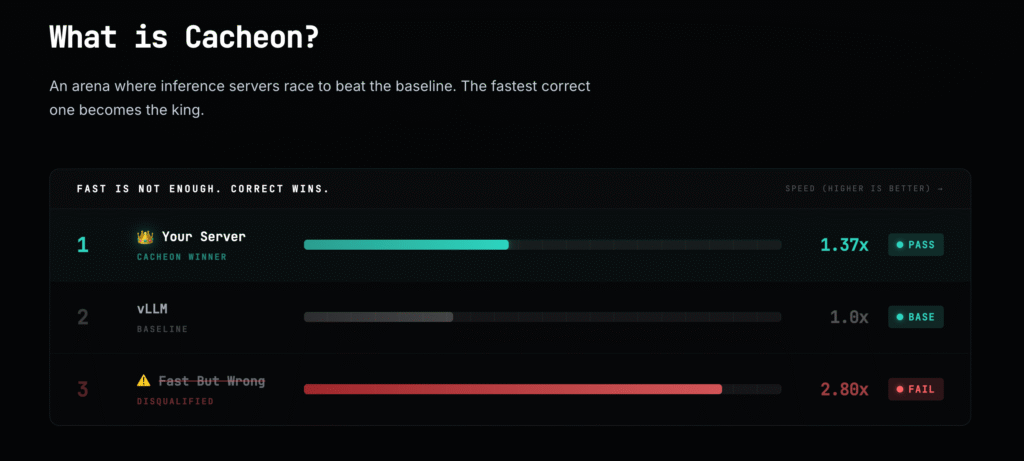
Cacheon is built on a practical belief: AI does not only need better models. It also needs better ways to run them.
The industry has spent years celebrating model launches, but the next phase will be about making those models usable at scale. Speed, cost, reliability, and performance will matter more as AI moves from demos into real products and autonomous agents.
Cacheon is positioning itself at that layer.
Follow them on X to stay updated on updates.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment