
If you’ve ever wondered why an AI image classifier can confidently identify a panda one second, then call the same image a gibbon the next, you’ve already encountered the problem Perturb (Subnet 26) exists to solve. Perturb is building a decentralized, global, always-on red team for AI models.
What does “perturbation” mean?

In computer science, perturbation is the act of introducing small, often imperceptible noise into a data input.
For instance, flipping a few pixels in an image, adjusting subtle frequencies in audio, or swapping a few characters in text. To a human eye or ear, nothing has changed. The panda still looks like a panda. The stop sign still looks like a stop sign. But the AI model sees something very different.
Some real-world examples:
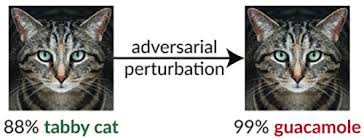
- A panda image a model classifies with 57.7% confidence can become a gibbon at 99.3% confidence after a tiny perturbation.
- A Rhodesian Ridgeback (59.2% confidence) changes to an Irish Terrier (94.3%) after FGSM noise is applied.
- A stop sign can be made to read as a speed limit sign by a self-driving model.
- Medical imaging tools can misclassify scans. Facial recognition can be fooled. Fraud detection can be bypassed. Content moderation can be steered.
Modern AI models often pick up on subtle, non-human-intuitive features in their training data. Perturbation attacks exploit exactly those features.
Koyuki, the owner of SN24, puts it plainly: “It’s easier in some cases to fool the AI models than to fool a human.”
Why this is the next frontier of security
Today, when most people think about online attacks, they think DDoS or cyber intrusion. Perturb’s bet is that the next major attack surface is autonomous AI networks themselves.
Imagine an attacker who doesn’t try to crash a platform like X but instead manipulates its moderation algorithms to surface the exact content that should be suppressed.
Imagine an attacker who feeds carefully perturbed inputs into a bank’s fraud-detection system to slip transactions past it.
Imagine a coordinated campaign that turns an autonomous vehicle’s perception layer against itself, swaying self-driving vehicles.
The problem is simply astronomical. The current defense industry is static, expensive, slow, and doesn’t scale. The market for AI red-teaming is projected to grow from $1.43B in 2024 to $11.6B by 2033, and regulation is part of the reason.
Under the EU AI Act, companies that deploy high-risk AI systems (things like medical AI, fraud detection, and biometric tools) can be fined up to €15M or 3% of global annual turnover if they fail to meet requirements like risk management, technical documentation, and cybersecurity.
How the subnet works
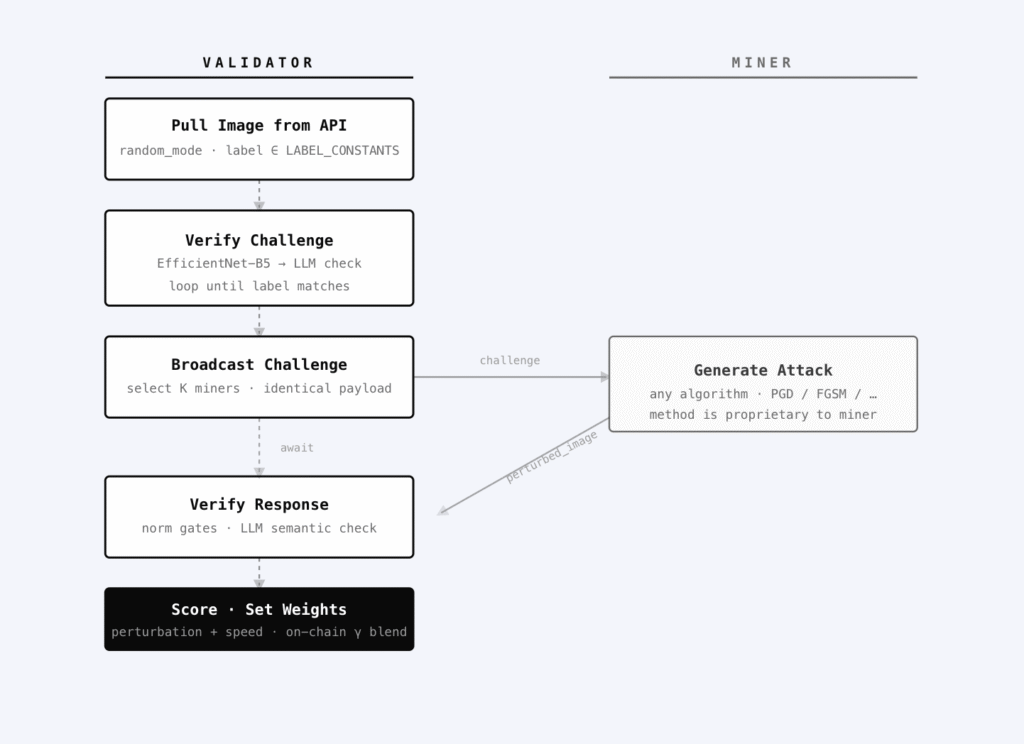
Perturb runs as a challenge-response loop between validators and miners:
Validators build the challenges.
- Pull a random image (e.g., from Pexels).
- Run it through a fixed classifier (currently EfficientNet-B5).
- Use a small LLM (Qwen2.5-1.5B-Instruct) for semantic verification, making sure the label actually matches the image.
- Package the challenge (clean image, true label, attack constraints) and send identical payloads to all miners.
Miners generate the attacks.
- Apply adversarial perturbations (default PGD-style, with proprietary methods encouraged).
- Return only the perturbed image, encoded.
- Their goal is to cause the classifier to misclassify the image, while keeping the perturbation as small and as fast as possible.
Validators verify and score.
- Check that the image is valid, that the perturbation falls inside tight L∞ norm bounds, that the LLM confirms a semantic mismatch, and that image quality metrics (SSIM, PSNR) hold.
- Final score blends 70% perturbation quality (smaller, harder-to-detect attacks score higher) with 30% speed (faster responses score higher).
- Miners need to process more than 100 challenges before being able to earn emissions.
The whole system allows progressive improvement, since quality gets better as miners discover new attack methods that the next generation of validators then have to defend against.
How the subnet makes money
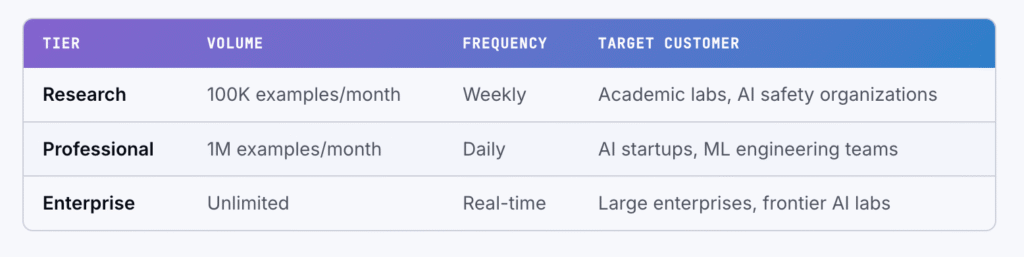
Two outputs come out of the loop, and both have commercial value outside Bittensor:
- Adversarial training datasets. A continuously growing corpus of original + perturbed images + attack metadata, sold via subscription tiers to AI labs that want to harden their models. This is the “data” side of the business.
- On-chain model robustness certificates. Cryptographic proofs containing scores, attack examples, LLM analysis, and AutoAttack comparisons that are usable for compliance, procurement, and AI Act audits. This is the “certification” side.
The vision is that any company training or deploying an AI model can plug into Perturb to get a continuous, decentralized, financially incentivized red team probing it for weaknesses.
What’s happening at Perturb (SN26) right now
The subnet has been moving fast in its first weeks, and most of the visible activity is converging around one thing: getting the Playground in front of real users.
- The playground waitlist is live. An interactive demo where you upload an image and watch a perturbation flip the model’s prediction in real time.
Try the demo here at perturbai.io
- Cross-subnet integrations are in motion. Koyuki has indicated that several Bittensor subnets will be plugging into Perturb’s perturbed datasets to retrain their own models for robustness. This is because it makes Perturb’s output useful inside the ecosystem before external enterprise customers arrive.
- Commercialization push is days, not months, away. The team has confirmed that partnership announcements with both subnets and external institutions are lining up over the next few weeks, including a joint research project with MIT.
This is a subnet that launched four weeks ago and is already lining up academic research collaborations, cross-subnet data partnerships, and a public-facing product. Worth watching closely.
Look at their whitepaper to learn more.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Enjoyed this article?
Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox — every morning before markets open.



Be the first to comment