

Ditto (SN118) shared how the team made Ditto better at answering vague questions like “what did I decide about that thing a while back?”
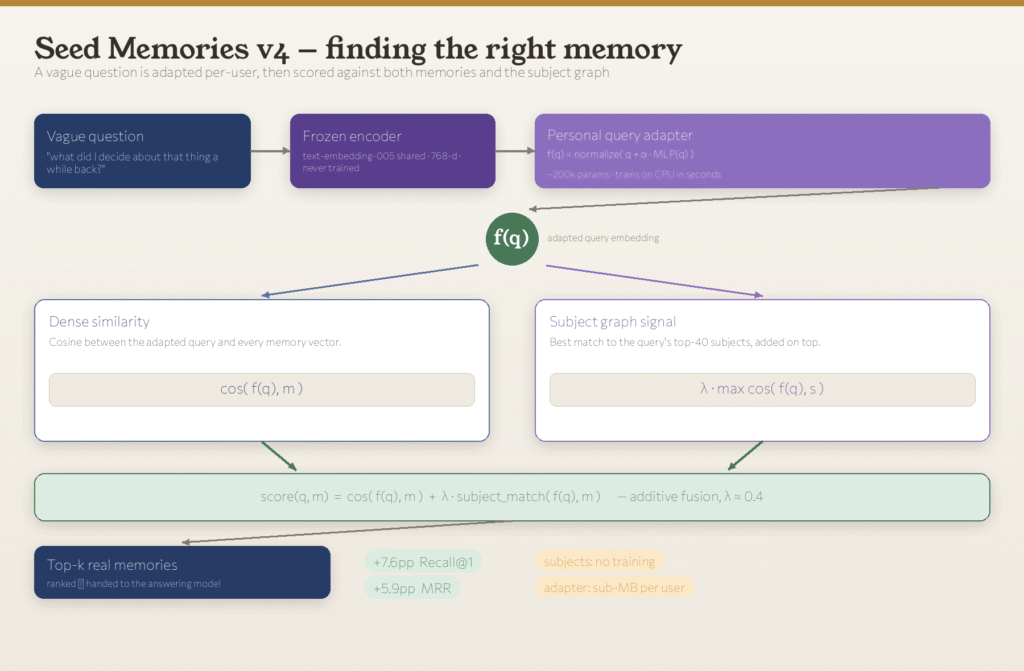
The new system, called Seed Memories v4, helps Ditto find the right memory from thousands more often than before. It lifts Ditto’s top-result accuracy by 7.6% points without needing a GPU, without retraining the main AI, and without storing anything heavy per user.
The whole improvement comes from two simple ideas that work better together than apart.
The Problem Ditto Was Trying to Solve
Asking a chatbot a clear question is easy. Asking it a fuzzy one is the hard part. When a user says “remind me what I decided about that thing,” there is no keyword to search and no obvious filter to apply.
Where Ditto stood before v4:
1. The existing approach worked. Every memory and every question gets turned into a kind of mathematical fingerprint, and Ditto finds the memory whose fingerprint looks most like the question.
2. It was good but not great on vague questions. The right memory landed at the top of the list about 60% of the time.
3. The team wanted to improve without trade-offs. No slower performance, no higher cost, nothing harder to ship.
Idea One: Let the Knowledge Graph Help
Every Ditto user already has a quiet knowledge graph being built behind the scenes. As conversations happen, Ditto tags the people, projects, and topics that come up and links them to the memories where they appeared.
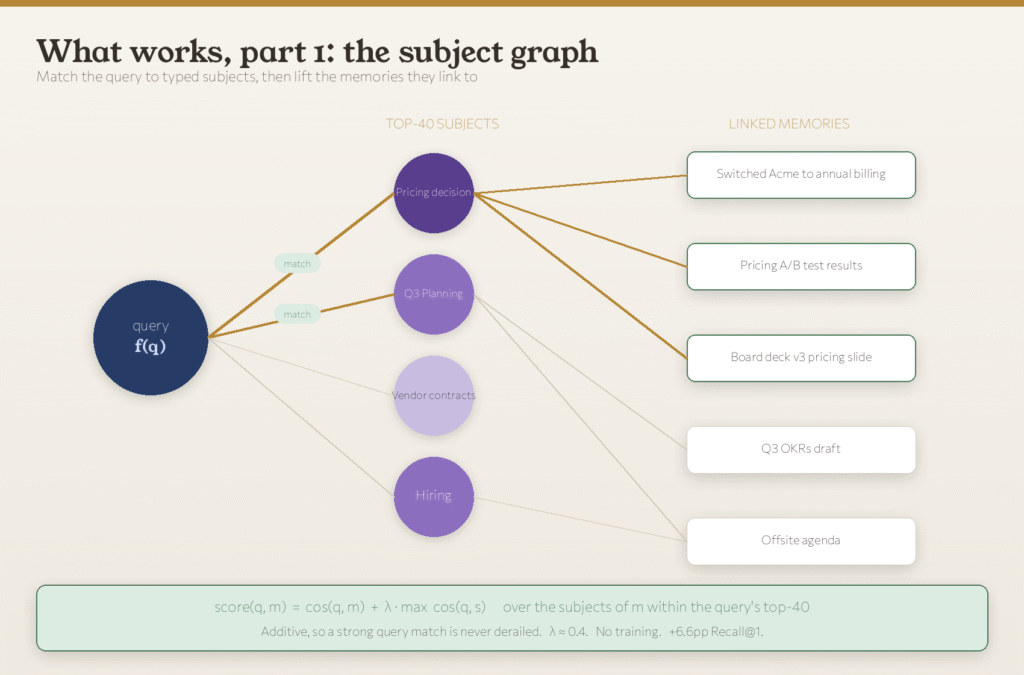
Seed Memories v4 uses that graph as a second opinion:
1. The system checks which topics match the question. When a user asks something, Ditto first finds the closest matching topics in the graph.
2. Memories tied to those topics get a small boost. Any memory linked to a matching topic is nudged higher in the ranking.
3. The boost can only help, never hurt. A memory already matching the question gets lifted. A memory that does not match cannot be artificially pushed to the top.
4. The graph cannot make things up. It only knows topics the user has actually discussed.
5. It requires no training. The graph is already there. The system just reads from it.
This idea alone delivered most of the accuracy improvement, with no per-user training required.
Idea Two: A Tiny Model That Belongs to Each User
The second idea gives each user their own small AI model. Not a chatbot, and not a copy of the main system. Just a tiny helper that learns the user’s personal way of asking questions and quietly adjusts queries so Ditto can find the right memory faster.
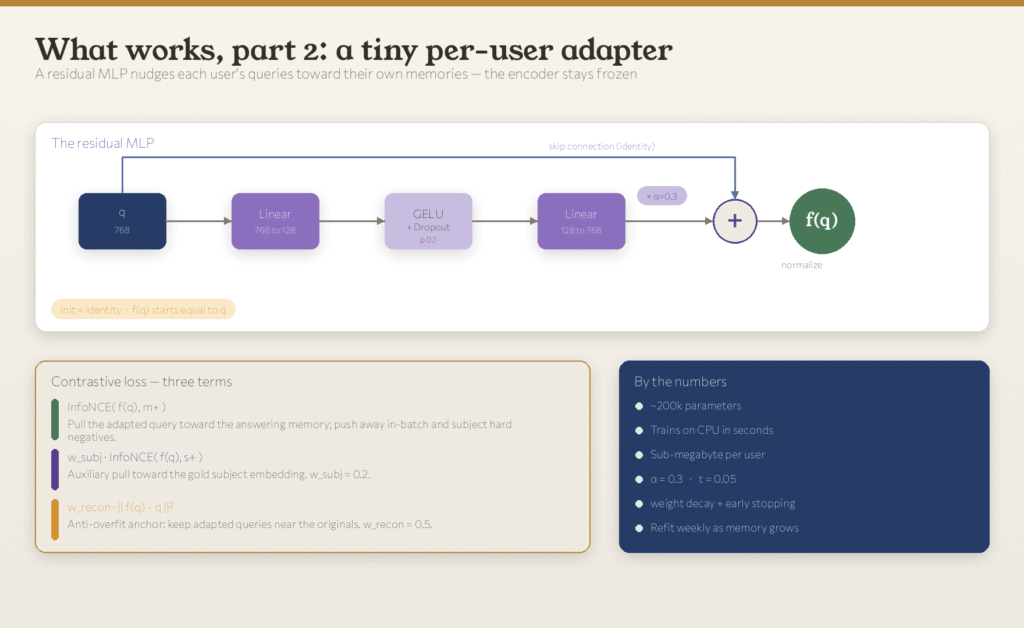
What makes this practical:
1. It is small. Less than a megabyte per user.
2. It trains in seconds. On a regular CPU (Central Processing Unit), no GPU (Graphics Processing Unit) needed.
3. It cannot drift away from the main system. The helper is built to nudge queries, not replace them.
4. It learns from the user’s own history. Over time, it gets better at understanding how that specific person phrases their vague questions.
5. It only ships if it wins. A new version is only sent to a user if it beats the old one on test questions.
The Results in Plain Numbers
The team tested the system on a real user’s memory store of about 2,200 memories and 200 hard, vague questions. Here is what changed:
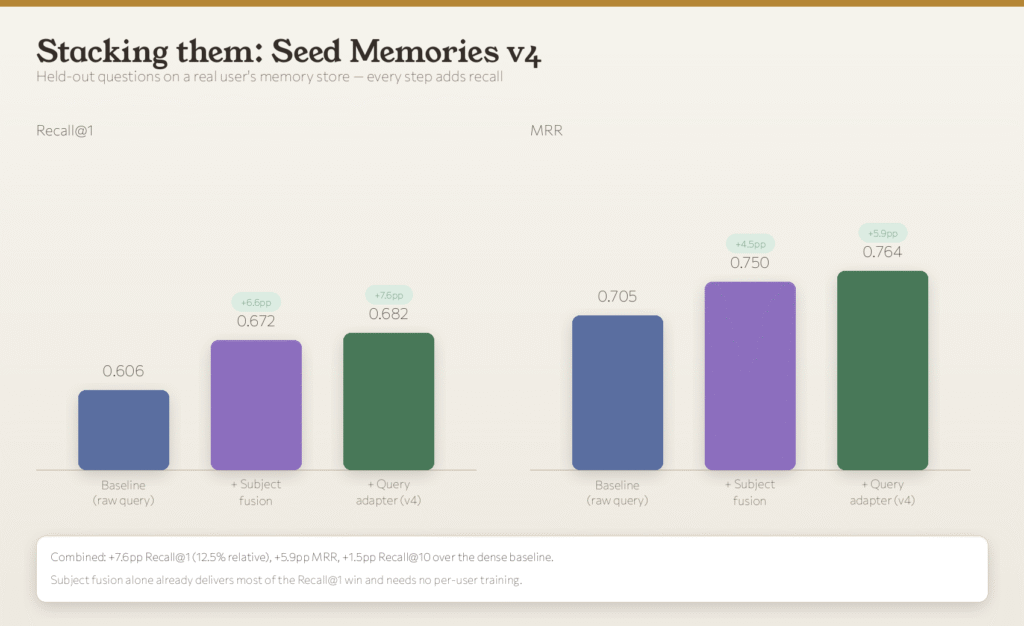
1. Top-result accuracy. Went from 60.6% to 68.2%, a 7.6-point gain on the hardest type of question.
2. Ranking quality overall. Improved by 5.9 points, meaning the right memory now lands higher up the list more often.
3. Improvement scales with use. Users with more memories and more conversations get progressively better results.
4. The graph carries most of the win. Idea one (subject matching) does the heavy lifting. Idea two (the personal helper) adds a smaller but reliable extra boost on top.
What the Team Tried That Did Not Work
Not every idea panned out. The team also tested an approach called Personalized PageRank, which spreads scores across the knowledge graph through multiple hops. It is the technique behind some well-known memory systems.
Why it failed here:
1. It made accuracy worse, not better. Performance dropped on the same test questions.
2. It is designed for multi-hop reasoning. PageRank shines when answering means connecting several things across a network.
3. Finding one memory is a single hop. The wrong tool for the job.
4. The simpler approach already captured the useful part. Subject matching in v4 did what PageRank was meant to do, without the side effects.
The team kept what worked and dropped the rest.
What’s Next: Memories That Describe Themselves
The team is now building a third idea called Generative Memories. Instead of just adjusting a user’s question, this future system would generate a rough draft of the memory the user is reaching for, in their own phrasing, and use that to find the real one.
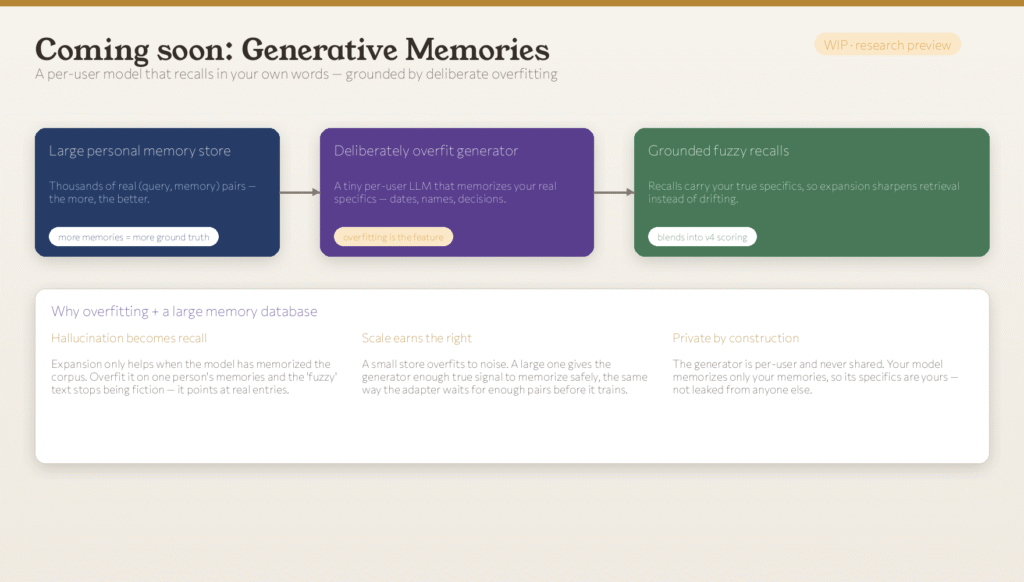
Two design choices make this work:
1. The model is fully personal. It only ever sees one user’s memories and is never shared. The only details it can know are the user’s own.
2. It is trained to be deeply familiar with that user’s memories. This sounds risky on the surface, but a model deeply familiar with real memories stops inventing fake details. It reaches for things the user actually said.
The team is taking the same careful approach as before. Generative Memories will only ship if it beats the current system on real test questions.
The Personal Memory Story
Seed Memories v4 is a small but meaningful upgrade in how Ditto recalls memories. The two ideas behind it, a knowledge graph that quietly helps and a tiny personal model that adjusts each user’s questions, deliver real accuracy gains without making Ditto heavier or more expensive.
The combined system finds the right memory 12.5% more often on vague questions, and the helper only ships if it actually proves itself. The bigger picture is the direction Ditto is moving in, and personalization is becoming something the system ships per user, not per model. The next step is letting the memory finish the user’s sentence before they do.
➛ Read About Ditto’s Seed Memories v4 In Full Here
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment