
Chutes (SN64) published a draft tech report on Parallax, the model training method the team has been experimenting with for decentralized MoE (Mixture of Experts) training.
The report proposes splitting MoE routed experts across participants to massively cut VRAM (Video Random Access Memory) and FLOPS (Floating Point Operations Per Second) per worker, while keeping the system fast to onboard and privacy-aware by default. Testing covers 20B parameter models in two configurations, small model iterations, and 176B parameters as a feasibility proof.
The report also lays out an architecture argument that goes beyond training and into what should actually be built for inference.
What Parallax Does
Parallax changes how MoE training is divided across participants. In a normal MoE setup, every training step waits on heavy data exchange between GPUs (Graphics Processing Units) holding different experts.
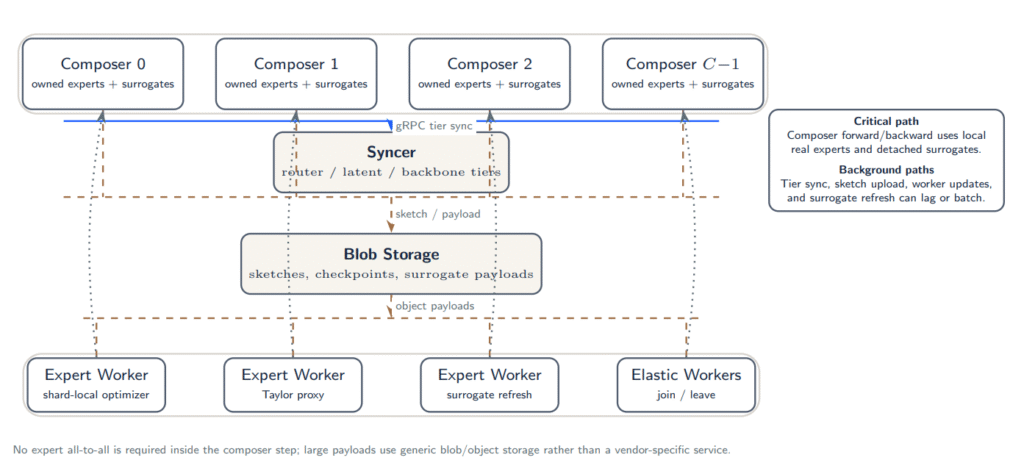
Parallax removes that bottleneck by giving each GPU node ownership of only a portion of the experts, while approximating the rest with lightweight stand-ins.
a. Each node owns a slice of the experts. Only those experts are trained at full quality on that machine.
b. The rest of the experts are stored as small, compact approximations. These let the node still route across the full model without waiting on remote data.
c. The router still sees all experts. Routing decisions are made globally, but execution stays local.
d. Owners update their approximations in the background. Other nodes pull the updates between training steps.
e. A worker-offload version of the system goes further. Heavier expert updates can be sent to cheaper remote GPUs that handle the work in parallel.
The result is a training pipeline that no longer needs every GPU to be connected by high-bandwidth links.
Why It Matters for Privacy
Privacy comes from the design rather than being added on:
a. Sensitive data can stay on the owner’s hardware. Only the first couple of layers carry enough information for an attacker to reconstruct text. The rest is safe by default.
b. Workers do not see what they are training. They receive only the small data slice needed to update one expert, with no information about layer position or full context.
c. Compressed sketches replace raw data. Workers operate on summaries, not the underlying tokens.
The 20B Results
Two real 20B training runs anchor the report:
a. 4-GPU H100 run. Reached a validation loss of 3.1896 at the comparison point. A traditional baseline at the same token count reached 3.1990. Parallax tracked within 0.3% of the baseline.
b. 8-nodes run on cheaper hardware with remote workers. Used L40S and RTX 6000 Ada nodes for the main work and two 8-GPU RTX 4090 nodes for expert updates.
Reached 3.2521 at the comparison point and improved to 3.2104 with further training. Final gap to the baseline was 2.0%.
c. Different batch sizes were normalized. Validation curves were compared on a token basis, not raw step counts.
The paper is careful to say these are point estimates, not full replication tests, and that real-world speed comparisons are not included.
The Cost Model
The bigger argument sits in the math. At the tested 20B configuration:
a. With 4 nodes: routed-expert compute drops by ~3.9× and total active compute drops by ~1.85×.
b. With 8 nodes: routed-expert compute drops by ~7.6× and total active compute drops by ~2.16×.
c. With 8 nodes plus worker offload: routed-expert compute on the main nodes drops by ~20.9×, and total active compute drops by ~2.43×.
d. Memory drops with the same pattern. Each node only holds its share of expert weights and optimizer state, with the offload version removing expert optimizer state from the main nodes entirely.
e. The heavy expert-to-expert traffic is gone. Roughly 309 GB of data per training step on the H100 run and 722 GB per step on the larger run would have moved across the network in a normal setup. Parallax avoids that entirely.
Total compute savings are bounded by the parts of the model that always have to run, but the routed-expert savings scale strongly with node count.
The 176B Feasibility Test
The 176B test is a 135-step run on four B300 nodes, and it is not a full training run. The purpose was to confirm the architecture can start cleanly, route across 640 experts per layer, sync across nodes, and reduce training loss.
The target configuration uses a Mamba-heavy backbone, low-precision (ternary) expert weights, and a compact expert interface designed for efficient serving. The paper says this is a launch-path check rather than a convergence claim.
The Architecture Argument
The broader point in the report is that decentralized training only matters if the resulting model is worth running. The architecture the team is building toward includes:
a. A compact expert interface that keeps communication and storage small.
b. Ternary expert weights that cut storage and memory pressure substantially.
c. A Mamba-heavy backbone with selective attention. This keeps long-context inference cheap without sacrificing quality.
d. Targeted hardware fit. The architecture is designed to run efficiently on specific GPUs like the RTX Pro 6000 and B200/B300, which handle low-precision compute well.
The principle Durbin emphasizes is to build for inference, not benchmarks. The metric that matters is intelligence per dollar.
The Open Question
The most forward-looking part of the paper raises a research question rather than an answer: If the lightweight approximations can stand in for real experts during training without much accuracy loss, can they replace them at serving time as well?
The paper proposes future experiments comparing full-expert, mixed, and all-approximation serving at matched checkpoints. A positive result would mean Parallax is not just a training method but a serving compression path.
What Still Needs to Be Proven
The report is open about the limits of what has been tested:
a. Scaling above 8 nodes is theoretical. Larger setups may run into staleness, drift, or worker reliability issues.
b. The worker-offload system is not optimized yet. Compression, scheduling, and acceptance gates have engineering work ahead.
c. Multi-owner expert shards are not yet tested. This is the next priority for fault tolerance and stability at scale.
d. The 176B run is not convergence proof. A long training run with proper evaluation is still future work.
The Read
Parallax is one of the more grounded contributions to decentralized AI training released this year. The 20B results are real, the cost model is concrete, and the limitations are honest.
The architecture direction, hybrid Mamba-attention with low-precision experts and a compact expert interface, is aimed as much at serving as at training.
Durbain’s central argument is that decentralized training only matters if it produces models worth running. Parallax is the training-side bet that says it can.
➛ Read The Original Paper Here
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Enjoyed this article?
Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox — every morning before markets open.



Be the first to comment