

Full article credit: @arkhet
This is not another whitepaper or pitch deck full of projections. It is a working platform, live in production, that is quietly assembling the most technically sophisticated decentralized AI infrastructure anyone has ever built. Post-quantum cryptography. Hardware-level GPU verification. Trusted execution environments that guarantee not even the machine owner can see your data. Custom inference kernels hitting 1,550 TFLOPS. Real revenue. Real users. And a team whose tokens are locked in a smart contract vault so they literally cannot sell.
Its name is Chutes; it is doing to AI inference what Hyperliquid did to finance.
I have read the code. The entire codebase is open source. I have listened to the founders speak at length about what they are building and why. I have traced the architecture from the CUDA kernel level to the cryptographic transport layer. What I found is not just interesting. It is the kind of thing that forces you to rethink your assumptions about who is going to win the AI infrastructure war.
The Hyperliquid Playbook
Think back to 2023. Every decentralized exchange was slow, expensive, and unusable for serious traders. The consensus was that decentralized trading simply could not compete with Binance or Coinbase. The latency was too high. The liquidity was too thin. The experience was too painful.
Then Hyperliquid showed up.
They raised nothing. Sold no tokens. Published no roadmap full of promises. Just a perpetuals exchange that was actually fast, actually reliable, and built for people who cared about execution quality above everything else. The team shipped product instead of marketing decks. They let the performance speak.
Hyperliquid went from “interesting experiment” to one of the most valuable protocols in crypto, not through hype, but because the product worked and people used it. Revenue followed organically. S&P Dow Jones Indices now licenses the S&P 500 for perpetual contracts on Hyperliquid, reshaping how the world thinks about decentralized market infrastructure.
Chutes is at that exact inflection point right now. But the market it is entering is orders of magnitude larger.
AI inference (every ChatGPT query, every hospital diagnostic model, every autonomous vehicle decision) is a $100B+ market that has more than doubled in the past two years. And right now, the entire market flows through a handful of centralized gatekeepers: @awscloud, @Azure, @googlecloud, @togethercompute, @FireworksAI_HQ.
Chutes is the decentralized alternative.
The Numbers
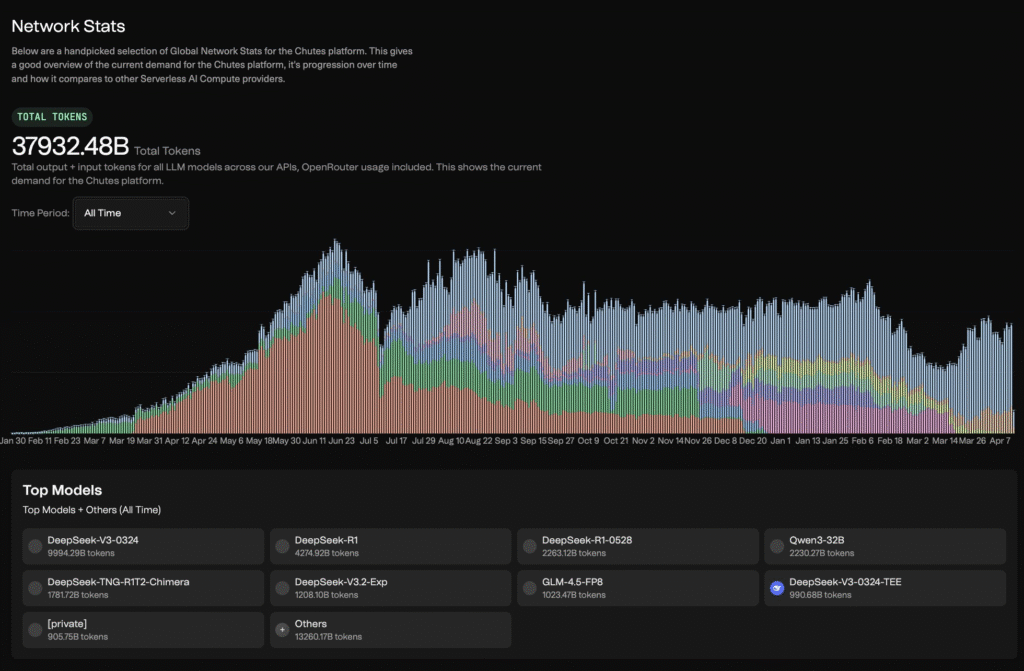
In less than four months since launch, Chutes has scaled to over 1,170 active GPU nodes on the network, including 701 @nvidia H200s and 64 B200 Blackwells already in production. The platform has processed nearly 38 trillion tokens since launch across 53 deployed applications serving more than 700,000 registered users across the Chutes and Squad platforms, not counting third-party integrations like OpenRouter.
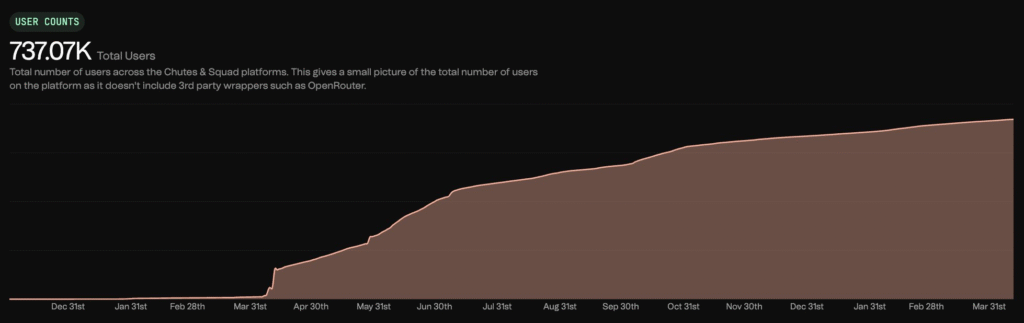
Those numbers are from before the team made the hardest decision a growth-stage company can make.
Chutes deliberately cut their GPU fleet from 1,700 H200s down to 700. They killed the free tier on OpenRouter that was driving 20 billion tokens per day at zero revenue. They shut down a free quota program serving 11,000 users. They dropped a privately-hosted model running at a 9:1 cost-to-revenue ratio. They caught companies funneling $6,400 in monthly usage through $20 subscription accounts and closed them.
Total token volume dropped 45%. Revenue only dropped 25%. Revenue per GPU jumped 44.9%, from $4.05 to $5.89 per day. And here is what matters most: organic pay-as-you-go usage, the metric that actually signals product-market fit, grew 20% in the ten days after the cuts. 85% of their users were not affected at all.
They ripped out every subsidized, unprofitable revenue stream, and the real business underneath grew.
This is the same playbook Hyperliquid ran. You do not need everyone, just the right users paying real money for a product they cannot get anywhere else.
What No One Else Can Build
Now here is where it gets technically interesting. And where I think @OpenAI, @AnthropicAI, @GoogleDeepMind, and every major cloud provider should be paying very close attention.
Chutes is the first AI inference platform shipping post-quantum cryptography in production. I do not mean it is on a roadmap or buried in some research paper. It is live, running in production right now.
They use ML-KEM-768, the NIST-standardized post-quantum key encapsulation mechanism, paired with ChaCha20-Poly1305 for symmetric encryption. Every inference request you send, every output you receive, is encrypted end-to-end with cryptography designed to remain secure when quantum computers arrive.
But encryption alone is not enough if the machine running your model can read your data in memory. So the Chutes team built sek8s, a custom Kubernetes orchestration layer that deploys every workload inside Trusted Execution Environments. Intel TDX for CPU isolation. @nvidia Confidential Computing mode for GPU memory encryption. The person who owns the physical GPU literally cannot see your prompts or outputs while their hardware processes them.
CHUTES SECURITY STACK
━━━━━━━━━━━━━━━━━━━━━
Key Exchange: ML-KEM-768 (NIST PQC standard)
Encryption: ChaCha20-Poly1305 (symmetric)
CPU Isolation: Intel TDX (Trusted Domain Extensions)
GPU Isolation: NVIDIA Confidential Computing
Orchestration: sek8s (custom K8s for TEE workloads)
Attestation: GraVal (firmware-level GPU fingerprinting)
Verification: cfsv, inspecto, cllmv (output proofs)
Status: LIVE IN PRODUCTIONThe implications for regulated industries are significant.
If you are a hospital and you want to run a diagnostic AI on patient data, your options today are: buy your own GPUs (expensive, slow, impossible to maintain at scale) or send patient data to a cloud provider and trust that no compromised insider, no state actor with a subpoena, no breach will ever expose it.
Chutes gives you a third option. Send your data to a GPU you have never seen, owned by someone you do not know, and get cryptographic proof that nobody saw it. The GPU owner cannot see it. The Chutes team cannot see it. No government can compel access to it. The math guarantees it.
No major centralized provider offers this combination today: not @OpenAI, not @AnthropicAI, not @awscloud Bedrock or @Azure AI. While cloud providers offer individual pieces like confidential GPU VMs, none delivers permissionless, end-to-end verifiable inference where the operator, the cloud provider, and the platform itself are all excluded from the trust model simultaneously.
But there is a deeper point here that most analysis overlooks entirely. Trusted execution environments and Intel TDX are not proprietary to Chutes. Other companies use TEEs. Other platforms claim confidential computing. The difference is that none of them are open source.
When a closed-source provider tells you they are running your workload inside a TEE, you are trusting their word. You cannot inspect the code that executes inside that enclave. You cannot verify what it does with your data before, during, or after processing. You cannot confirm that telemetry, logging, or model training pipelines are not siphoning off your inputs. The TEE guarantees hardware isolation, but it says nothing about what the software inside it actually does.
The entire Chutes codebase is open source and publicly auditable. Every line of code that runs inside those enclaves can be inspected by anyone. You do not need to trust the Chutes team. You can read the orchestration layer, the inference engine, the transport protocol, and the attestation system yourself. TEEs provide the hardware guarantee. Open source provides the software guarantee. Chutes is the only platform that delivers both.
This is the difference between “trust us, we use TEEs” and “verify it yourself, here is the code.”
The verticals this unlocks are enormous: healthcare under HIPAA, legal firms where inference patterns could reveal litigation strategy, quantitative finance where prompt patterns are proprietary alpha, defense and intelligence where classification levels prohibit cloud deployment. Chutes did not build a cheaper AWS. They built something AWS architecturally cannot offer.
The Hardware Fraud Problem (Solved)
The oldest problem in decentralized compute is hardware fraud. You pay for an H200, the operator gives you an A100, pockets the difference, and your model runs slower than advertised. You would never know.
Chutes built GraVal: GPU Remote Attestation and Verification. It works at the firmware level. Every GPU that joins the network gets cryptographically fingerprinted, validated against known hardware specifications, and issued an attestation certificate. If the fingerprint does not match, the GPU gets rejected. This is continuous, automated, and cryptographically enforced. Fake GPU attacks, the single biggest vulnerability in every other decentralized compute network, are structurally eliminated.
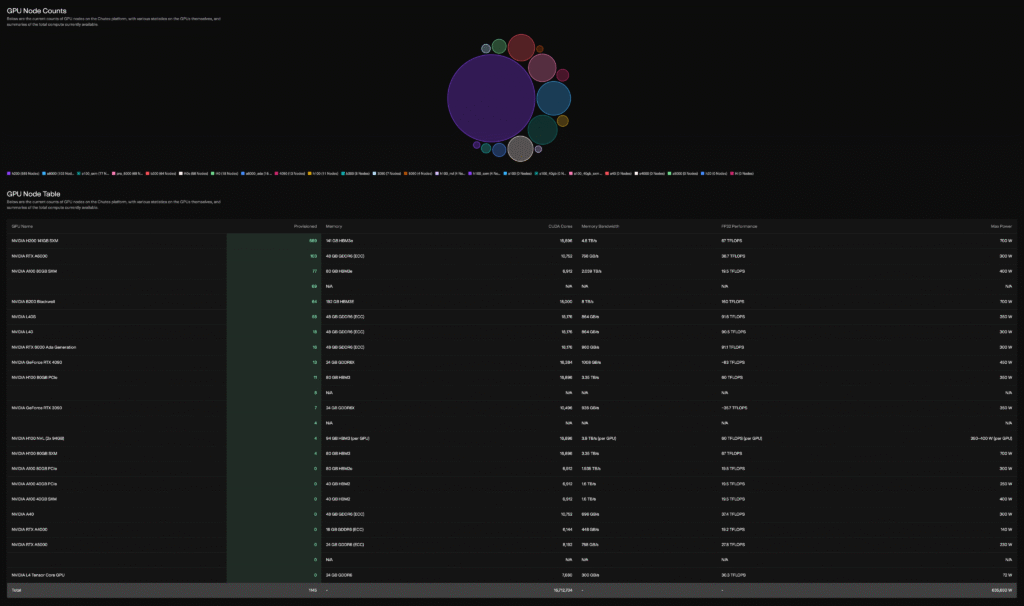
They also built verification tools (cfsv, inspecto, cllmv) that prove not just that the right hardware ran your workload, but that the correct model produced the correct output. When you call the @OpenAI API, you trust that you are getting the model you asked for. You have no cryptographic proof. Chutes provides that proof for every single inference.
The Catalysts
Two near-term catalysts have the potential to reshape how the market prices Chutes.
First, Jon Durbin, a core Chutes contributor, recently shared that the team is working on a novel approach to decentralized training of large-scale models. Details are forthcoming. If the approach works at the scale they are targeting, it would expand Chutes from inference infrastructure into the training layer as well, a fundamentally larger market.
Second, the team is hosting a public Q&A and AMA event today, where they plan to share more details and SOTA breakthroughs along with sharing a more refined future roadmap.
The Long View
If you have followed this analysis to this point, you understand that Chutes is not simply a cheaper alternative to centralized inference. It is the embryonic form of something much larger: the trust and verification layer for the entire AI economy.
If that sounds like a bold claim, read the code at github.com/chutesai.
But here is the number that should stop you cold. As of this writing, Chutes trades at a fully diluted valuation below $500 million. Hyperliquid, the closest structural analogue in crypto, sits near $40 billion. That is nearly two orders of magnitude between two projects that followed the same playbook: no venture capital, real revenue from day one, community-owned token distribution, and a technical moat that took years to build. Both platforms address effectively infinite total addressable markets. That gap does not stay at ~80x.
But the roadmap Durbin outlined goes further than research. Over the next six to twelve months, Chutes is rolling out a developer commission system: if you build an application that routes inference through Chutes, you get paid for the usage it generates. This is the same flywheel that made AWS sticky for startups and Shopify sticky for merchants, except the economics flow through a transparent token rather than an opaque enterprise contract. More developers building means more inference volume, which means more revenue, which means more token buybacks and burns.
Every major technological wave, from railroads to the internet, follows the same arc: a speculative installation phase, a repricing crisis, then a deployment phase where open, revenue-generating platforms absorb the market share of rigid incumbents. AI infrastructure is entering this transition now. Chutes is designed for the deployment phase.
Chutes’ TEE stack is not merely a privacy feature. It is a fundamental rights technology, one that cryptographically enforces the boundary between your cognition and someone else’s training pipeline. In a world where your inference history is a more detailed map of your thinking than anything you deliberately publish, the ability to prove that no entity captured, stored, or monetized your data is not a luxury. It is the precondition for intellectual sovereignty in an AI-mediated world.
In a world of razor-thin inference margins, the only surviving model is one with no rent-seeking layer, where every dollar of revenue flows directly to the operators providing the compute. That is not an ideological position. It is an economic inevitability. Chutes’ protocol-level buyback mechanism, which uses 100% of platform revenue to purchase and burn alpha tokens, passes cost efficiencies to holders in a way that centralized providers, who must extract margin for shareholders, structurally cannot match.
Compute Sovereignty and the New Geopolitics
There is a geopolitical dimension to this story that most analysis ignores entirely.
Compute power has quietly replaced petroleum as the primary resource of strategic influence. The United States and China are the only nations that control the full stack: semiconductor design, fabrication, cloud infrastructure, and energy supply. Every other country on earth depends on one of these two for its AI capabilities. Brookings Institution research describes this as “digital sovereignty,” and mid-sized economies from the EU to the Gulf states are now forming compute alliances specifically to reduce their dependence on American and Chinese cloud providers.
The vulnerability is not abstract. When your national AI infrastructure runs on three AWS regions and two Azure zones, a single policy decision in Washington or a supply chain disruption in Taiwan can functionally disable your entire AI capability overnight. Centralized inference is a single point of geopolitical failure.
Decentralized inference changes the calculus. A distributed GPU network spanning jurisdictions, with orchestration any government can audit, is structurally resistant to the kinds of choke points that make centralized cloud a national security liability. This is the same design principle that made TCP/IP resilient: you cannot shut down a protocol by taking out a single node.
Chutes is not marketing itself as critical infrastructure. But that is what it is becoming, whether the team intended it or not.
And they are not using off-the-shelf inference engines. Dig into the GitHub and you will find their integration of DeepGEMM, the FP8 matrix multiplication kernels hitting 1,550 TFLOPS on H800 GPUs, with dedicated optimizations for Mixture-of-Experts architectures. They forked and maintain both DeepGEMM and SageAttention, delivering 2-5x speedup over FlashAttention through quantized attention with outlier smoothing. These are not cosmetic patches. This is hardware-level inference optimization that compounds. Every percentage point of efficiency improvement across 1,100+ GPUs translates directly into margin.
The Team Structure That Changes Everything
This is where the @HyperliquidX analogy cuts deepest.
Hyperliquid launched with no VC backing. No investor unlock schedules. No misaligned incentives between the team and the users. Chutes took that model and went further.
The team has no CEO, no board of directors, no institutional investors. Jon Durbin, Namoray, and roughly 10 other contributors form a decentralized collective operating as Chutes Global Corp. They ship code. Their entire GitHub is open source. The core platform infrastructure, from orchestration to transport to verification, is all original work. Where they do fork, they fork inference engines like vLLM and SageAttention and maintain them with deep, performance-critical modifications. Nothing wraps someone else’s API. They even built their own design system (chutes-style), a comprehensive component library with brand tokens in both CSS and JSON. That is the kind of infrastructure investment you make when you are building for the next decade, not the next funding round.
What should make every other crypto project uncomfortable is this: the team’s alpha tokens are locked in a smart contract vault. They literally cannot sell.
Their only path to financial upside is making the platform generate real revenue, which flows back through the Bittensor auto-staking mechanism to increase the value of the tokens they hold. By construction, this is the most incentive-aligned team in AI infrastructure. They cannot rug, they cannot dump, and the only way out is building something that works.
Compare that to the standard playbook: raise at inflated valuations, launch a token, vest over two to four years, and dump at the first sign of momentum. Or the venture path, where the mandate is to grow at all costs and never think about unit economics.
Chutes cannot play either game. The structure will not let them, and that is precisely the point.
Beyond Inference: The Platform Play
What caught me off guard is how quickly Chutes is expanding beyond inference.
The decentralized training approach mentioned earlier is not a side project. If it works at the scale the team is targeting, it would expand Chutes from inference infrastructure into the training layer, a fundamentally larger market.
Inference is becoming a commodity. Prices compress. Open-source models keep getting better. And I mean actually open source, not the watered-down “open-weight” releases we have been seeing from companies like MiniMax and others, where they hand you the weights but bury commercial restrictions in the license. Chutes is fully open source. The distinction matters because real open source means anyone can build on it, fork it, commercialize it, extend it without asking permission.
Training is where the structural value lives. And doing it on decentralized, verified, confidential hardware? Nobody has cracked that yet.
But training is not the only expansion. Look at what is already live:
- Chutes Search (search.chutes.ai): A Perplexity competitor running on decentralized infrastructure. Zero data harvesting. Your search queries do not train anyone’s model.
- Chutes Chat (chat.chutes.ai): Hundreds of LLMs, vision models, image models, and audio models working together in one interface. A ChatGPT alternative where your conversations belong to you.
- Sign in with Chutes: An OAuth 2.0 implementation that lets developers build AI-powered apps where users bring their own compute. Think “Sign in with Google” but for GPU access. If you are an indie developer building an AI search engine, your users can power their own queries. Zero inference cost for you. Five minutes to integrate.
- Chutes Dropzone: A self-hosted workspace bundling OpenWebUI, n8n workflow automation, and Chutes SSO. Deploy your own private AI workspace connected to decentralized compute in minutes.
- OpenClaw: A local-first personal AI assistant connecting to 20+ messaging platforms. WhatsApp, Telegram, Slack, Discord, Signal, iMessage, Teams. Your AI, accessible from whatever app you already use.
Under the hood, the developer infrastructure is equally ambitious.
- model-router: An intelligent task classifier that analyzes incoming queries and routes them to the optimal model. Math to math models. Code to code models. Creative writing to creative models. Automatic fallback chains. Infrastructure that makes the whole platform smarter over time.
- responses-proxy: A Rust service translating @OpenAI’s Responses API into Chat Completions. Any application built for the OpenAI API can switch to Chutes as a drop-in replacement. Circuit breakers, streaming, dual-format tool calling. Production-grade.
- Vocence (SN102): The first decentralized voice AI platform, running on Chutes infrastructure. Cross-subnet collaboration previewing what the Bittensor ecosystem looks like when subnets start composing.
Taken together, this is a single platform offering search, chat, an inference API, developer authentication, workflow automation, personal AI, voice AI, intelligent model routing, and drop-in OpenAI compatibility, backed by university research partnerships and with training capabilities on the near horizon.
The Developer Ecosystem
Chutes is not just an API. They are embedding into every tool developers actually use.
Roo Code (the popular VS Code agent, a Cline fork) has Chutes as a native provider. LiteLLM supports Chutes, meaning any app on the LiteLLM abstraction layer can route to Chutes with a config change. OpenRouter has Chutes as an inference provider, plugging into hundreds of downstream apps. They built a Vercel AI SDK provider with image, video, text-to-speech, and music generation. They built n8n community nodes with full tool calling and LangChain compatibility. They even built claude-proxy, a Rust proxy letting @AnthropicAI Claude Code and Claude Desktop use any OpenAI-compatible backend through Chutes.
And then there is chutes-audit: an independent system verifying validator fairness in request distribution. Requires 16 CPU cores, 64GB RAM, and 1TB NVMe to run. This is serious accountability infrastructure.
This is how platforms win. You do not just build the product. You embed yourself in every toolchain, every workflow, every developer’s daily driver. Every Roo Code session, every n8n workflow, every Vercel app using the AI SDK, that is another thread in a web of integrations that becomes progressively harder for competitors to displace.
And the university strategy is quietly brilliant. Chutes is rolling out campus partnerships, bringing decentralized AI infrastructure to student developer clubs. The students building on Chutes today are the CTOs making infrastructure decisions in five years.
The Revenue Reality
Post-cleanup, Chutes is running at seven-figure annual recurring revenue, with daily revenue around $16,900 and recent peaks above $22,000. All organic, all from paying customers, after surgically removing every subsidized revenue stream. By year end, the trajectory points squarely at eight figures. The compounding here is what matters: every new model deployed on Chutes becomes available to every developer. Every new GPU added serves every model. Every new developer building on the API creates integrations that attract more developers. Platform network effects are what take a business from eight-figure to nine-figure revenue faster than any linear projection would suggest.
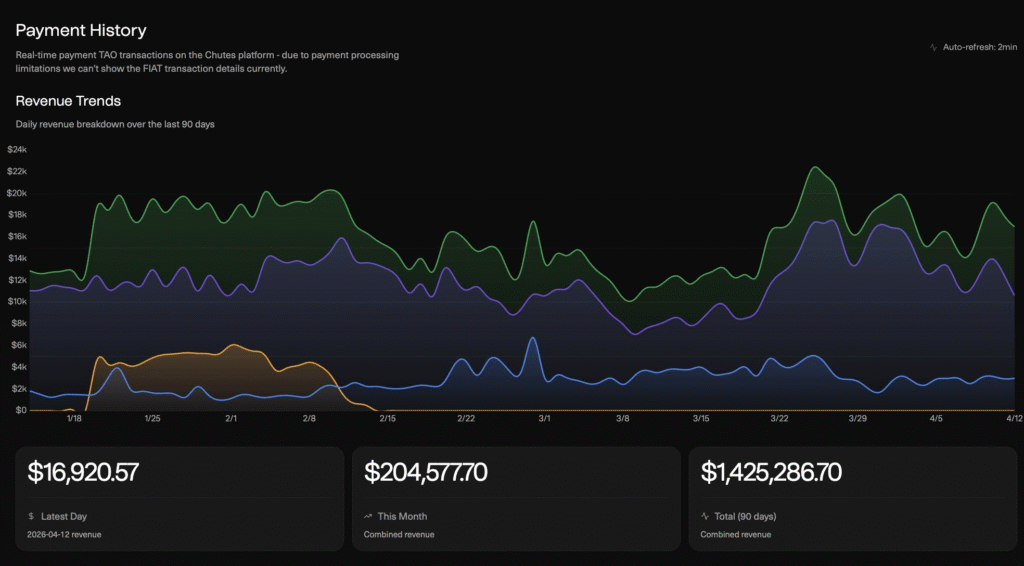
The tokenomics reinforce this. SN64 alpha tokens, the subnet’s native token, are priced through an on-chain AMM pool against TAO. New alpha is emitted daily on a 4/14/1/18 split across miners, validators, the subnet owner, and stakers. TAO flow directs TAO into the alpha liquidity pool based on how validators weight the subnet, deepening the pool over time. The result is a flywheel: more usage attracts GPU supply, more GPUs enable lower prices, lower prices attract developers, and developer adoption drives the TAO inflows that sustain alpha token value.
But here is what most analysis misses. Chutes auto-stakes platform revenue directly back into the SN64 alpha token. Real revenue from real customers creates structural buy pressure that has nothing to do with crypto sentiment, market cycles, or speculation. It is a protocol-level buyback funded by actual inference revenue. As the platform scales, this mechanism compounds.
The Bear Case (and Why It Is Wrong)
I want to be honest about the bear case, because conviction without intellectual honesty is just delusion.
The “income desert” analysis points out that SN64 alpha emissions, valued at roughly $52M annually at recent prices, dwarf the platform’s external revenue. That framing is not wrong on the surface. But it misunderstands the mechanics. Under TAO flow, those emissions are alpha tokens distributed to participants, not TAO being printed into the pool. The alpha only holds value if people are buying it with TAO through the AMM. In other words, the “subsidy” is already market-validated: it persists only as long as stakers believe in the subnet’s future revenue. Without subsidies, Chutes pricing would be roughly 1.6x to 3.5x more expensive than centralized alternatives.
Here is why the bears are analyzing a version of Chutes that no longer exists.
First, the team already proved they will sacrifice growth for unit economics. They cut 59% of their GPUs and revenue per GPU went up 45%. That is a team actively preparing for a world where subsidies decline, not one coasting on them.
Second, the TEE stack creates pricing power that pure cost-per-token comparisons completely miss. Enterprise customers in healthcare, legal, and finance do not compare Chutes to DeepSeek on price. They compare Chutes to “we literally cannot use cloud inference because of our compliance requirements.” When your alternative is building your own datacenter, Chutes at 2x the price of Together AI is a massive bargain.
Third, the TAO halving (projected late 2029) will compress emissions across every subnet. The subnets that survive will be the ones with real revenue. Chutes started the revenue pivot two to three years early. That is not a coincidence.
The bears are running numbers on a version of the company the team has already dismantled.
The Data Custody Thesis
In the early years of crypto, the mantra was simple: not your keys, not your coins. It took billions of dollars in exchange collapses, from Mt. Gox to FTX, before the industry internalized that custodial risk was not theoretical. People learned, painfully, that handing control of your assets to a third party meant trusting that third party with your financial life.
The same lesson is about to play out in AI, and the stakes are arguably higher.
Your prompts to an AI model are not throwaway queries. They contain your reasoning patterns, your business strategy, your medical questions, your legal exposure, your intellectual property. In aggregate, your inference history is a more complete portrait of your thinking than anything else you produce. It is, in a meaningful sense, a map of your cognition.
Right now, nearly all of that data flows through companies with terms of service that reserve the right to use your inputs for model training, with retention policies measured in years, and with security track records that include significant breaches. @OpenAI suffered a data leak in 2023 that exposed payment information and chat histories. Their default data retention policy permits training on user inputs unless you explicitly opt out, and the opt-out process has changed multiple times. @AnthropicAI retains conversation data and reserves broad rights to use it for safety research and model improvement. Neither company allows you to audit what happens to your data after it leaves your device.
This is the custodial model applied to cognition. You hand over your most sensitive thinking and hope their incentives stay aligned with yours.
Chutes offers the alternative. Run an agent framework like Hermes locally. Route inference through the Chutes security stack described above. Neither the node operator nor the platform can see your data. When the response comes back, you hold the only copy.
This is self-custodied AI. Not your inference, not your data.
Chutes is building the infrastructure now so that when the migration starts, the destination already exists.
Where This Is Going
Here is the question nobody in crypto or AI is asking yet, but everyone will be asking within 18 months: what happens when inference becomes a commodity?
It is already happening. Open-source models keep closing the gap with frontier labs. @AIatMeta’s Llama, @MistralAI’s Mixtral, DeepSeek’s v3, they are good enough for 90% of production workloads. Inference providers are in a race to the bottom on price. @togethercompute, @FireworksAI_HQ, and a dozen smaller shops are all competing on cents-per-million-tokens, shaving margins thinner every quarter. This is a commodity curve, and it only moves in one direction.
So if raw inference becomes a commodity, what captures the value?
The trust layer, the verification layer, the privacy layer: the infrastructure you cannot replicate by spinning up more GPUs.
That is exactly what Chutes is building. And the alpha token is how that value accrues.
In the next 3 to 6 months, the decentralized training approach ships and enterprise pilots in healthcare and legal begin closing. Over the following year, inference pricing compresses industry-wide, but Chutes captures a privacy premium that commodity providers cannot match, while the “Sign in with Chutes” SDK starts embedding decentralized compute into thousands of independent applications. By 2028 to 2030, the TAO halving will force every subsidized subnet to survive on real revenue. Chutes, which started its revenue pivot years earlier, will already be operating at scale while competitors scramble to find paying customers.
Why This Matters Now
I keep coming back to the @HyperliquidX parallel because it is so precise.
Chutes is at the same point in its arc. The product exists. The revenue is real. The technical moat, post-quantum crypto, TEEs, firmware-level GPU verification, is not something you replicate by writing a check or hiring a team. The founders are contractually locked in. They are expanding from inference into training, search, chat, mobile, voice AI, and developer infrastructure. They are embedding into the developer toolchain through Roo Code, LiteLLM, and OpenRouter. They are building the next generation of AI developers through university partnerships.
@OpenAI just closed at an $852 billion valuation. @AnthropicAI at $380 billion. @togethercompute seeking a $7.5 billion valuation. These companies are building centralized inference and training infrastructure without the security guarantees or incentive alignment that Chutes has constructed.
I am not saying Chutes should be valued like @OpenAI. I am saying the gap between what Chutes has actually built and what the market currently recognizes is wider than anything I have seen in this space since @HyperliquidX was “just another DEX.”
What Chutes has assembled without venture funding amounts to the most comprehensive decentralized AI infrastructure stack in existence: real revenue, locked team tokens, custom inference kernels, and a security stack no competitor has matched. The product surface spans inference, training, search, chat, voice AI, workflow automation, personal assistants, and developer tools, supported by university research partnerships, an independent validator auditing system, and a design system that reflects a team building for the next decade.
Audit every line yourself at github.com/chutesai.
The broader market will come to recognize what Chutes has built. The question is how much of a head start you want when it does.
Sources
[1] Chutes GitHub: github.com/chutesai (open source)
[2] NIST FIPS 203: ML-KEM-768 Post-Quantum Key Encapsulation Standard
[3] Intel TDX Architecture: intel.com/content/www/us/en/developer/tools/trust-domain-extensions/overview.html
[4] NVIDIA Confidential Computing: nvidia.com/en-us/data-center/solutions/confidential-computing
[5] Bittensor Network: bittensor.com
[6] Chutes Platform Metrics: chutes.ai (as of April 2026)
[7] Hyperliquid Protocol: hyperliquid.xyz
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Enjoyed this article?
Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox — every morning before markets open.



Be the first to comment