

A month ago, Cacheon (Subnet 14) launched an open competition with one question: can a market for inference optimization beat a strong baseline? It now has an answer.
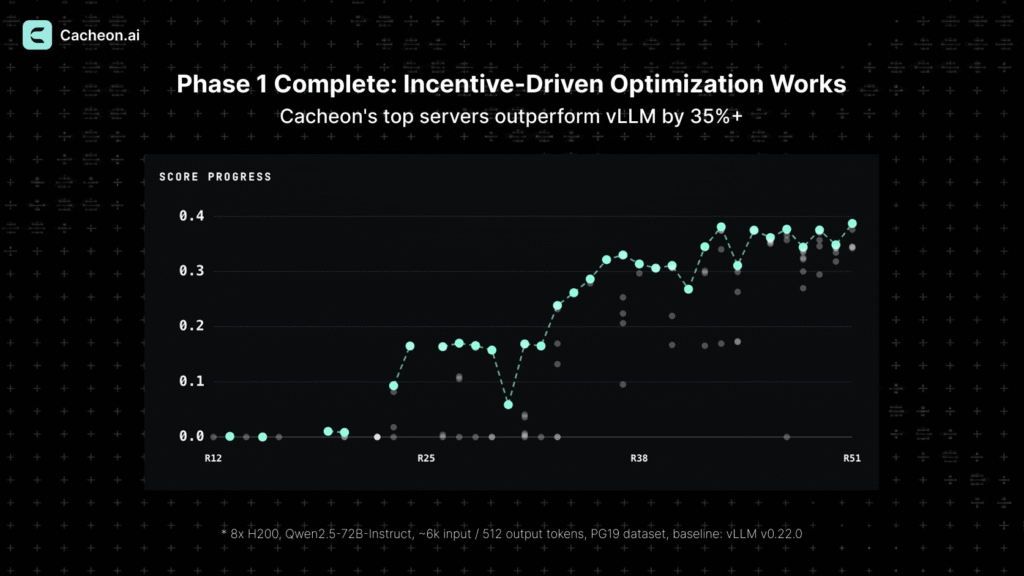
Cacheon’s top miners are outperforming the latest vLLM baseline on speed by more than 35%, consistently. This was achieved across the live competition, against the same model on the same hardware that validators use to score every submission.
For anyone hearing about the subnet for the first time, Cacheon takes a fixed open-source model (Qwen2.5-72B-Instruct in this first version), and miners compete to serve it through an OpenAI-compatible chat completions API inside Docker containers.
Validators test each submission against a vLLM baseline on identical hardware. The fastest correct server becomes the “king” and takes all miner emissions until someone beats it.
vLLM is the reference inference engine most of the industry already serves models with, so beating it by 35% is not a soft target. It’s the number teams in production are measured against.
What is the vLLM Baseline?

To understand what Cacheon just achieved, you have to understand the stuff they’re measuring against.
When a model finishes generating an answer for you, something has to be running that model on a GPU. That something takes your request, loads the model’s weights, does the math, and streams tokens back. That piece of software is called an inference engine, and vLLM is the one most of the industry reaches for first.
vLLM came out of UC Berkeley and is now the default open-source serving engine for large language models. It’s popular because it’s genuinely good at the hard parts of serving.
vLLM is not a weak strawman. It’s the engine a serious team would deploy in production today. It’s fast, it’s widely used, and it’s the number people quote when they talk about real-world serving performance.
That’s exactly why Cacheon picked it as the baseline. Every miner submission is tested against vLLM on the same model and the same hardware, so the comparison is honest: same starting line, same finish line, and the only variable is how well the miner serves the model.
When Cacheon says its top miners are beating vLLM by 35%, it means a market of independent miners found ways to serve the same model substantially faster than the engine the industry treats as the standard to beat.
Why the number isn’t the whole point
The headline is the 35%. The actual result is bigger than that.
Inference optimization is a search problem, and a brutal one. Every model, every GPU configuration, every batching strategy, scheduler, and serving parameter adds another axis to the space. The combinations multiply faster than any single team can test them, and the frontier moves every few weeks as new hardware and new techniques land. No company, however good its engineers, can stay at the edge of that space alone.
Cacheon’s bet is that you don’t need one team to. You need a market. Open the problem to competition, pay for verified improvement, and the search gets parallelized across everyone willing to mine it.
Phase 1 was the proof. It was deliberately narrow (one model, one baseline, one metric) because the only thing it needed to establish was that the mechanism produces real gains against a serious reference. It did.
A pain point the rest of the ecosystem confirmed
The team recently spoke with Chutes (SN64), and the conversation reinforced exactly what Cacheon is built around. The biggest bottleneck in inference wasn’t missing expertise. It was the size of the search space itself; too many combinations change too fast for any one group to cover.
That’s the case for doing this in the open. Most optimization work today stays locked inside individual companies, every team rediscovering the same wins in private. Cacheon’s thesis is that optimization should compound with open source, making every next AI discovery easier instead of dying behind a closed door.
What Phase 2 changes
Phase 1 competition pauses on June 20 while the team rebuilds. Phase 2 turns a set of isolated discoveries into a continuously improving optimization process. This makes the difference between proving miners can beat the baseline and building a system that keeps beating it, automatically, over time.
The team is reworking the incentive mechanism, expanding the optimization surface miners can attack, improving evaluation, and changing how miners contribute. All these are aimed at the longer goal of a genuinely scalable optimization layer for AI inference.
Behind the competition, the company side is moving too. Cacheon has been fundraising, hiring, and putting the legal and corporate foundations in place for what comes next.
The vision hasn’t moved
The long-term goal is the same one Cacheon started with. Every AI workload should have an answer to a single question: what is the optimal way to serve this?
Today that answer is guesswork, scattered across teams who can’t share what they learn. Cacheon wants it to be a discoverable, continuously improving result that anyone can plug into.
Phase 1 proved the mechanism works. Phase 2 is about scaling it into a product.
Follow Cacheon on X for Phase 2 updates as they roll out.
More about Cacheon:
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.


Be the first to comment