
Const posted something yesterday that, on its face, reads like every other Bittensor milestone tweet:
He kick-started a 3B-parameter training run in 5 minutes for ~5 TAO, stitching together 128 total strangers’ machines over the public internet.
The interesting thing is that the same setup scales to 100B-param models as more people join.
Let’s explore what happened, why it’s super hard, and what it’s for.
Took him 5 mins to set it up
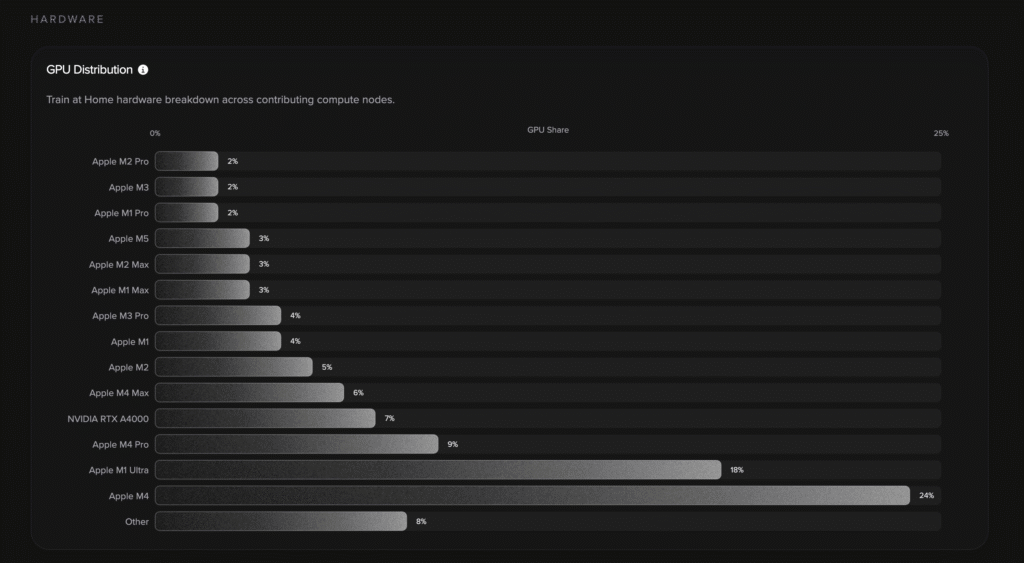
128 separate machines, owned by 128 different people who don’t know or trust each other, were stitched into a single training pipeline and started co-training one neural network. Setup took about five minutes. The on-chain cost was ~5 TAO.
No central company provisioned the cluster. No one had to ship their GPUs to a data center. The network spun up, assigned each machine a slice of the work, and started training.
That’s the kind of permissionless, fast, and cheap coordination that is enabled by the Bittensor network.
The current run kicked off June 3 under the run ID consts-v0 (yes, named after Const). More details about the training run:
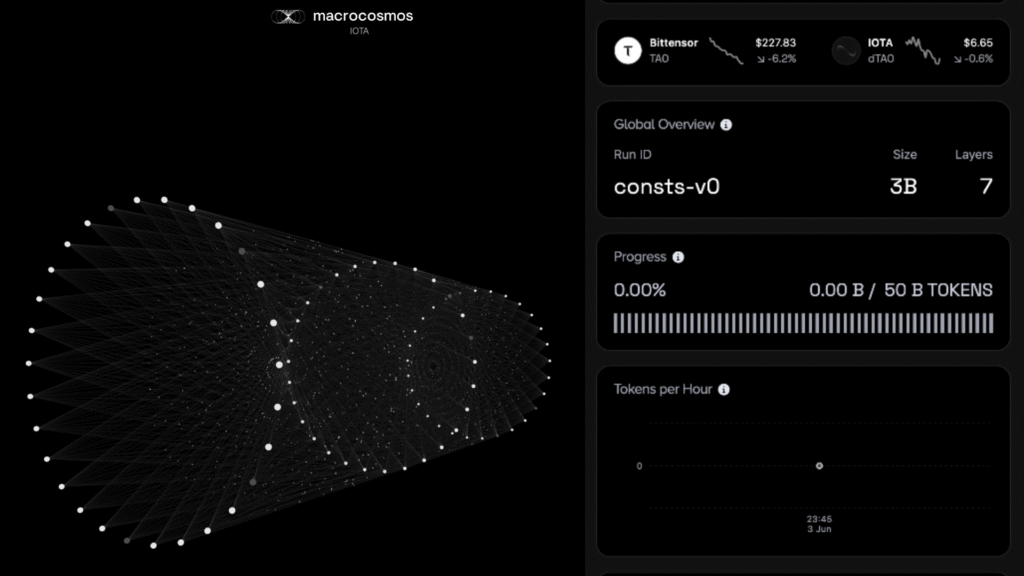
- Model size: 3B parameters
- Target: 50B training tokens
Why this is hard (the part that makes it impressive)
Training a large model has a brutal physical constraint: the whole model has to fit in your GPU’s memory. A 100B-parameter model doesn’t fit on a gaming GPU, or a MacBook, or anything you own. You need a rack of A100s/H100s wired together with fast interconnects (i.e., a data center).
That’s the wall every decentralized-training project hits.
Even IOTA faced this roadblock in its early days. Miners pretrained models from 700M up to 14B params and beat baselines like GPT-2 Large and Falcon-7B, but every miner had to fit the entire model on their own hardware. So the ceiling was “whatever the richest single miner can afford.” And because it was winner-takes-all, everyone’s work except the top model got thrown away. Was wasteful, and it caps you well short of frontier scale.
What IOTA does differently: cut the model into slices
IOTA’s fix is pipeline parallelism.
Instead of asking each machine to hold the whole model, IOTA’s orchestrator chops the model into stages and hands different stages to different machines. Picture the live consts-v0 run: that 3B model is carved into 7 layers, and the swarm forms an assembly line.
One band of machines runs the first stage, passes its output (“activations”) down to the next band, and so on. Each station only needs the tools for its own step. No single node ever holds the full model.
This means the maximum model size scales with the number of participants, not with the VRAM of the biggest machine. The more people join, the higher the chance the swarm can train a bigger model. That’s why “up to 100B params” is even sayable. The constraint moved from one machine to the size of the crowd.
Three pieces of engineering make it survive the open internet:
- 128× activation compression: those activations getting passed between machines are normally huge. IOTA squeezes them by up to ~128×, so home-grade connections can keep up instead of choking the pipeline.
- Butterfly All-Reduce: a trustless way to merge everyone’s contributions into one model without a central server, and resilient to some nodes being malicious or dropping offline.
- CLASP: a Shapley-value-style accounting method that measures how much each node actually contributed, so emissions are paid out proportionally instead of winner-takes-all. Nobody’s work gets discarded; everybody who helped gets paid for the help.
So what is it for?
Two answers, one technical and one economic.
Technical: it’s a path to training genuinely large open models without a hyperscaler. If the swarm keeps growing, the ceiling keeps rising, and it becomes a frontier-scale pretraining that nobody owns or gatekeeps. That’s the long game for a truly open AI infrastructure.
Economic: it turns idle consumer hardware into paid work. Instead of compute flowing up to whoever can afford the data-center rack (where the value also concentrates), IOTA pulls in everyday machines and pays them in $TAO for the layers they run. Const called this a cyclical economy rather than a hierarchical one, where value circulates back to the edge and helps fund the next run, rather than pooling at the top.
It only gets better from here
128 untrusted strangers’ machines were coordinated into one training run, permissionlessly, in minutes, for pocket change, using an architecture where the model can grow as the crowd grows, and where everyone who contributes gets paid for it.
It’s early, and the biggest numbers are still on the way. But the thing being demonstrated right now (cheap, fast, trustless orchestration of heterogeneous hardware into a single pipeline) is the actual hard part of decentralized AI.
And the team isn’t hedging on what comes next. When someone projected IOTA hitting ~1T params between late 2026 and mid-2027, Macrocosmos CEO Will Squires replied “too slow.”
Read more about their innovation:
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Enjoyed this article?
Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox — every morning before markets open.



Be the first to comment