

For most of the past year, the prevailing view among AI researchers has been that pretraining large models over the open internet is structurally impossible or so inefficient that it does not matter.
Macrocosmos’s Orion-100B on IOTA (Bittensor Subnet 9) just broke that view. The run trained a 100-billion-parameter model across 48 single A100 GPUs in five US datacenters, coordinated entirely over commodity internet, hitting roughly 65% of centralized training speed at a fraction of the cost.
It is now the largest decentralized training run ever publicly announced, beating Covenant-72B on both scale and economics.
How Orion-100B Compares to Covenant-72B
Covenant-72B held the previous record for the largest decentralized training run. Orion-100B beats it across every meaningful dimension:
a. 39% larger model: 100B parameters versus 72B.
b. 40x cheaper per participant: $1.25 per hour for a single A100 versus $50 per hour for an 8×B200 cluster.
c. 2.5x cheaper per replica: ~$20 per hour for an Orion replica versus ~$50 per hour for a Covenant peer.
d. Radically lower barrier to entry: one commodity GPU is enough to participate, where Covenant required hardware that almost no one could realistically provision.
Covenant proved decentralized training could work at scale. Orion proved it could work at a larger scale with hardware that ordinary participants can actually afford.
The Performance Numbers That Matter

The run was structured as 16 pipeline-parallel stages with 3 replicas, totaling 48 devices spread across five US datacenters.
The headline figures:
a. 30.8% average training MFU (Model FLOPs Utilization), with peak sustained MFU of 38% over a continuous 6-hour window. The highest reported for any distributed pipeline-parallel training run.
b. ~9,000 tokens per second average system throughput.
c. 1.1 billion tokens trained over roughly two days before the run was stopped for cost reasons.
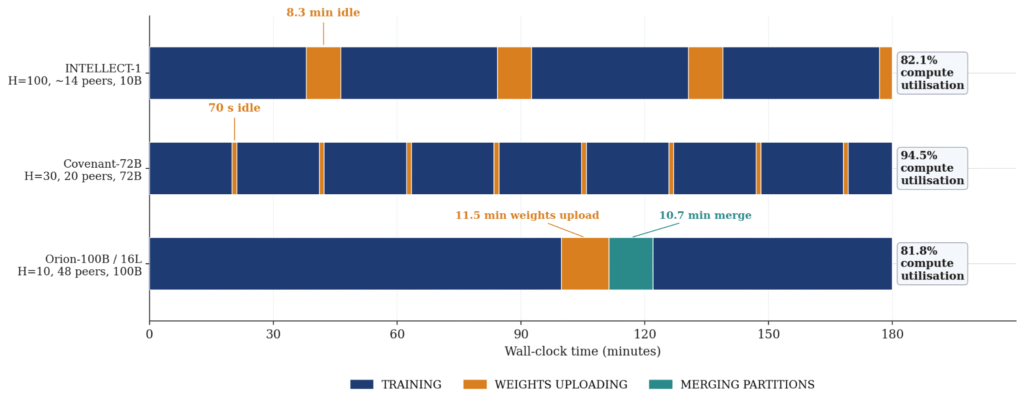
d. 81.8% overall training utilization, matching INTELLECT-1 while operating on a model 10 times larger.
These numbers cross the threshold where distributed training stops looking like a research curiosity and starts looking like a real alternative to centralized infrastructure.
Why Pipeline Parallelism Made the Difference
Covenant-72B used distributed data parallelism, where every peer hosts the full model. That approach has a structural ceiling: the largest model you can train is bounded by the memory of your smallest required peer, which is why Covenant required 8×B200 clusters.
Orion took a different route with distributed pipeline parallelism:
a. Each peer hosts only a fraction of the model, sometimes as little as a single transformer block.
b. Model capacity scales with the aggregate memory of the network, not with any individual machine.
c. Compute can be onboarded incrementally, one GPU at a time.
d. Synchronization runs in parallel across stages, completing faster than DDP (Distributed Data Parallelism) by a factor equal to the number of pipeline stages.
The shift means Orion can train models no single peer could host on its own, which is what unlocked the move from 72B to 100B.
The Three Technical Innovations Behind the Run
Orion-100B was made possible by a year of iteration on three specific advances:
a. ResBM, the state-of-the-art lossless activation compression technique, which shrunk inter-stage activation transfers from 140.6 MB to 2.2 MB. A 64x reduction.
b. Custom fault-tolerant P2P networking, optimized for throughput across heterogeneous nodes, with a stochastic pathfinding algorithm co-developed with miners on Bittensor Subnet 1.
c. The IOTA Bridge Service, for reliable distributed variable synchronization across globally distributed peers.
The team ran over 750 controlled experiments at a smaller scale, trained nearly 15 trillion tokens of test data, and improved system throughput by roughly an order of magnitude before attempting the 100B run.
Conclusion
Covenant-72B was the bar, Orion-100B raised it on every axis that matters: model size, cost per participant, and the barrier to joining a decentralized training run.
The structural shift from data parallelism to pipeline parallelism is what made the gap possible, and the technical work behind ResBM and the IOTA networking stack is what made the pipeline approach economically viable at a hundred-billion-parameter scale.
The Macrocosmos team is positioning this as the foundation for revenue-generating client work once the remaining proof points land, which is the moment Bittensor stops being narratively positioned as a training network and becomes operationally one.
➛ Learn More About Orion-100B Here
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Enjoyed this article?
Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox — every morning before markets open.



Be the first to comment