

Score (SN44) has spent its first year as a decentralized network where miners compete to build the best computer vision skills across CCTV, dashcams, and drones.

That scope just expanded, and the subnet is now training its own Vision Language Model, Satori 1.0 2B, available on Manako, which folds all nine perception primitives into a single compact model that runs on the camera itself rather than in a data center.
The skill competition stays live and feeds directly back into making each Satori generation sharper than the last.
What a VLM Is
The simplest way to understand Satori is to start with what a Vision Language Model is and how it differs from a Large Language Model.
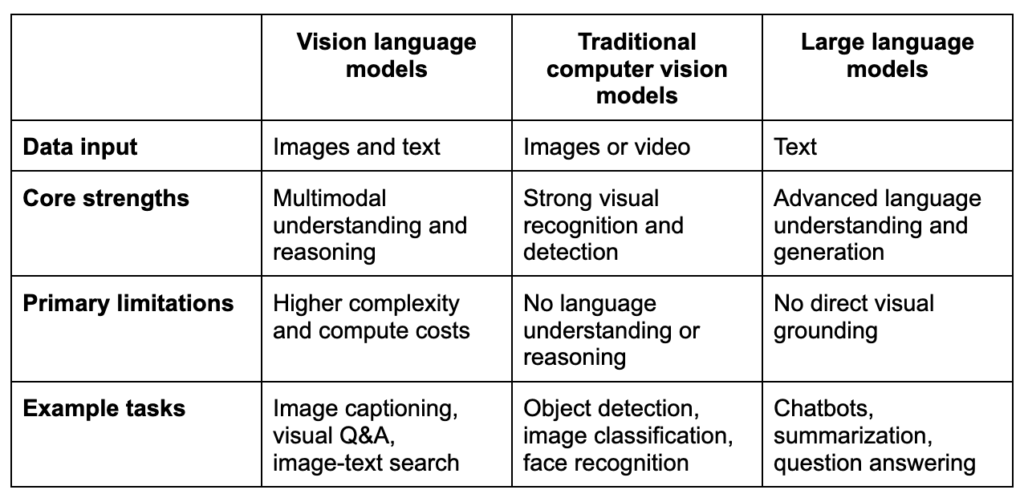
1. An LLM has read but never seen. It reasons fluently across text but cannot interpret an image on its own.
2. A VLM gives that brain eyes. It takes pixels and words together, so you can point it at any scene and ask in plain language what is there and what is happening.
A VLM is not a vision skill stitched to a chatbot. It is one model that understands the full picture natively.
What Satori 1.0 2B Covers
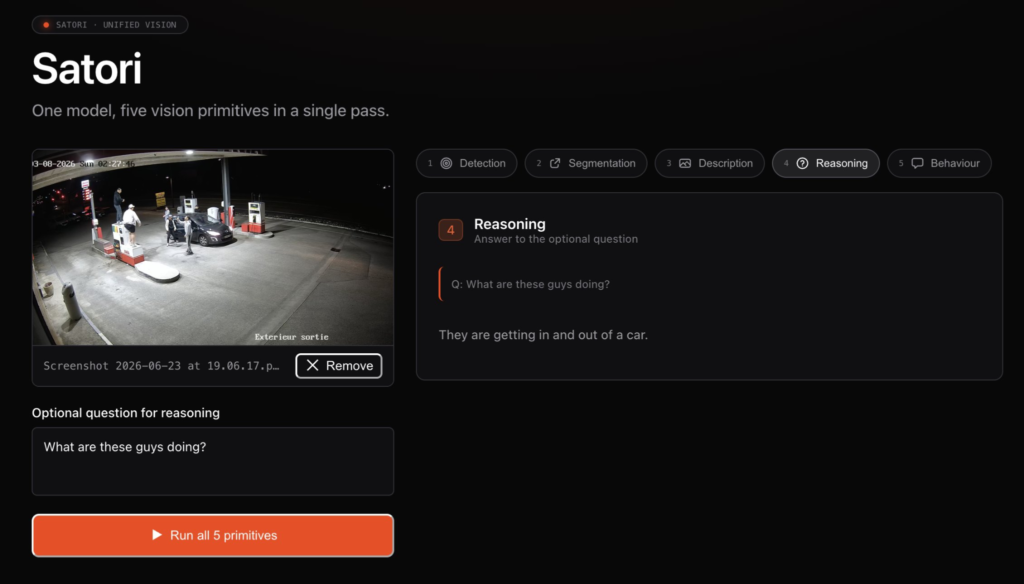
Satori is built through distillation, which compresses what the best frontier models know into one compact checkpoint. The result runs nine perception primitives in a single forward pass with no teacher needed at inference time.
| Primitive | What It Does |
| Detection | Identifying objects in a frame |
| Open-vocabulary detect-by-name | Finding objects by free-form description |
| Segmentation | Pixel-level masks for objects |
| Description | Generating natural-language descriptions of scenes |
| Reasoning | Answering questions about what is happening |
| OCR (Optical Character Recognition) | Reading text inside images |
| Counting | Quantifying instances of objects |
| Action | Recognizing what subjects are doing |
| Temporal video | Understanding sequence and change across frames (still emerging) |
Coverage is the point. Strong vision specialists top one or two benchmarks but cover only four or five jobs total. Even GPT-4o natively covers two. Satori covers all nine, posts the highest TextVQA score in its peer set at 83, and handles action recognition the others do not attempt.
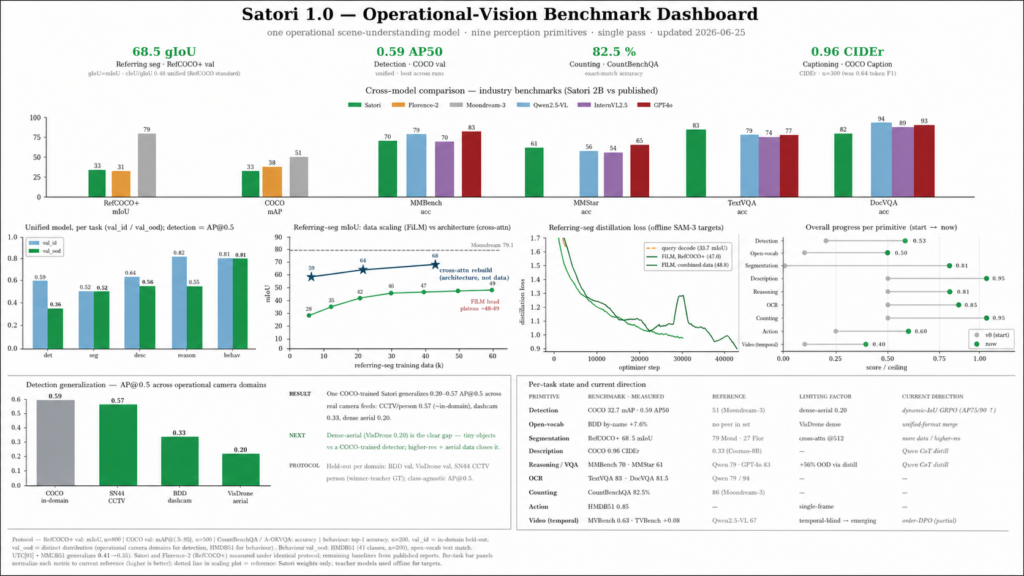
Video is the honest frontier with strong single-frame perception and temporal order just beginning to emerge. The footprint matters as much as the coverage, since Satori is built to run on the camera itself rather than in a distant data center.
The Family and the Flywheel
Satori 1.0 2B is the first model in the family, with a smaller sibling in the pipeline.
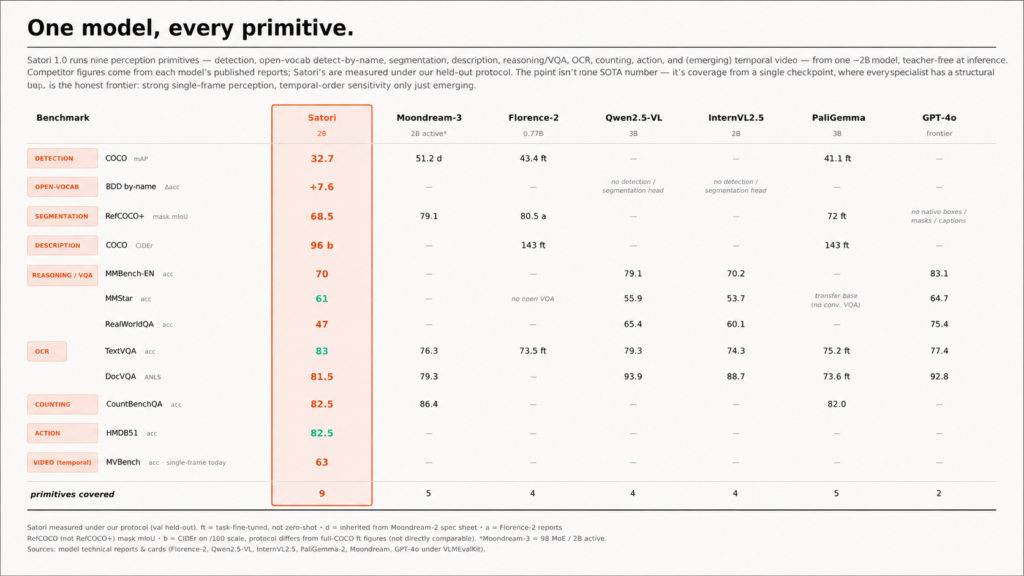
Satori’s 2B v. Other Models on Nine Primitives
1. Satori 1.0 2B. Nine primitives, ~2B parameters, on-device deployment, single-pass inference.
2. Satori 1.0 0.5B. Smaller distillation for the most constrained edge hardware. Same family, same jobs, a fraction of the footprint.
Both models exist for the same reason: physical AI has to live where the world is, not where the cloud lives. The Score skill competition does not go away either. It is the engine that keeps making each Satori generation better.
How the flywheel works:
1. Bigger models get distilled into the Satori base. Frontier vision and language models compressed into a deployable footprint.
2. SN44 miners sharpen the base downstream. Accumulated skills specialize Satori for specific domains and operational contexts.
3. Manako turns the sharpened models into vision agents. The no-code platform deploys the resulting models for real business operations.
4. Each cycle improves the next. More competition produces better skills, which produce better specialization, which produce better agents.
The Altitude Just Changed
Score’s destination has not shifted, but the altitude has. The subnet started as a marketplace for narrow vision skills and is now a lab training small on-device VLMs by distilling bigger models, then putting its decentralized skill base to work downstream.
The skill competition stays live as the engine that makes each generation sharper, and the deployment surface stays at the edge where cameras already are. The promise of one small brain for every camera, owned and run on-device, is closer to a working product now than at any point in the subnet’s history.
Satori 1.0 2B is the first step into that future, with the 0.5B variant ready for constrained hardware tiers and Manako wired in to put both into the hands of businesses running vision agents in real time.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment