

Macrocosmos published the introductory thesis behind IOTA (SN9), arguing that the next decade of AI economics will be decided by who extracts the most intelligence per installed watt rather than who installs the most GPUs.
The core idea is “liquid training”: converting AI training from a long-running, fragile, colocated workload into interruptible work that fills compute gaps rather than forming the bedrock. The proof points already exist on IOTA and through the published Orion-100B results, which trained 100B-parameter models at 30% of the cost of centralized paradigms using heterogeneous, non-frontier hardware.
Macrocosmos is taking IOTA to market with pilot customers in the second half of 2026.
The Core Argument
Macrocosmos opens with a single observation: compute is the limiting reagent of modern intelligence, and the AI industry currently buys it the way the early-20th-century chemical industry bought crude oil.
Undifferentiated, in bulk, from a handful of integrated producers. The thesis breaks down as:
1. The Old Model Does Not Scale To Today’s Workloads
A monolithic buyer worked when there was one consumer. It breaks under dozens of training, inference, and fine-tuning workloads competing for the same finite GPU pool.
2. Efficiency, Not Capacity, Is The New Scarce Position
When everyone buys the same chips, the edge shifts from how much you own to how productively you use what you already have.
3. Hyperscalers Already Spend Billions On This Problem
Google Kubernetes Engine, AWS spot pricing, and OpenAI’s Batch API are all attempts to capture the same utilization gain.
4. The Decade Shift Is From Peak To Throughput
The last decade optimized peak performance for clusters. The next decade is about total economic throughput per installed watt.
Where Training and Inference Conflict
The training-versus-inference split is where the inefficiency lives. Both workloads compete for the same finite GPU pool, but they operate on different time horizons and different commercial logic.
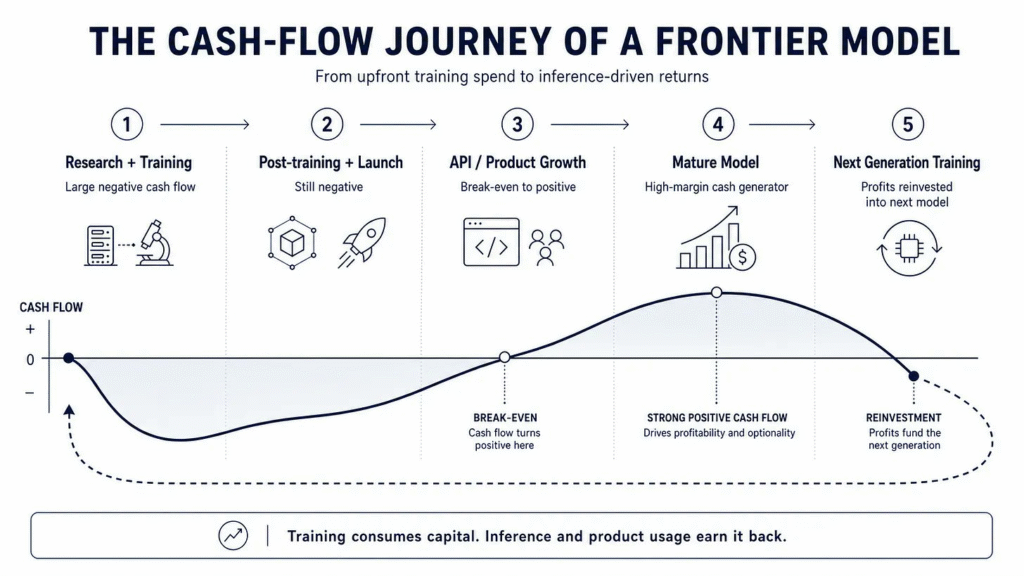
1. Training is the upfront capital commitment: Research, pre-training, post-training, evaluation, and launch happen before a model has proven commercial return. The work is long-running, fragile, and colocated by necessity.
2. Inference is where the investment gets realized: Tokens get consumed by users, API customers, agents, and applications. The work is demand-sensitive, latency-sensitive, and provisioned around uncertainty.
3. Training currently consumes capacity inference needs: Large-scale training jobs commit GPUs for long periods, which is exactly the capacity the market needs to flex across inference, fine-tuning, and evaluation workloads.
4. The strategic goal of the compute industry: Maximize total useful compute available at any given timestep. Today’s training paradigm works directly against that goal.
What Liquid Training Actually Does
The unlock Macrocosmos proposes is making training liquid: interruptible, heterogeneity-tolerant, and bandwidth-tolerant work that fills compute gaps rather than forming the bedrock.
The three non-negotiable properties:

1. Interruptible: The job must pause, yield GPUs to higher-priority workloads, and resume without losing progress.
2. Heterogeneity-tolerant: The job must run across GPUs of different generations, vendors, and performance tiers.
3. Bandwidth-tolerant: The job must work across nodes with imperfect network conditions, not just inside tightly coupled colocated clusters.
The economics that follow:
1. Liquid workloads sit in utilization troughs. They drive fleet utilization toward 100% without disrupting synchronous priority workloads.
2. Owners can flex into inference at peak. Inference becomes the priority load and training fills whatever capacity remains.
3. The Illustrative math. Moving a fleet from 60% to 85% productive utilization lowers the effective fixed cost per productive GPU-hour by roughly 30%.
Squires’ larger point is that reshaping the workload itself is where the bigger efficiency unlock lives, not just optimizing scheduling around fixed workloads.
The Orion-100B Proof Point
As Macrocosmos has shipped working evidence through IOTA on Bittensor and through the published Orion-100B results, the thesis is not purely theoretical.
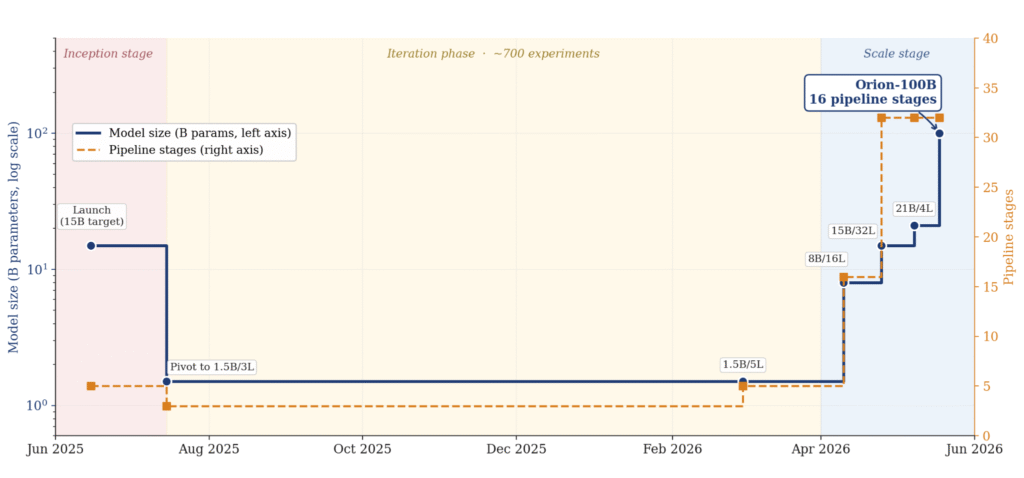
The Orion-100B numbers:
1. 100B-parameter models trained in production
2. 65% of centralized paradigm per12 formance at the model quality level
3. 30% of the cost of comparable centralized training runs
4. Heterogeneous, non-frontier, available hardware rather than uniform top-tier clusters
5. 18 months from impossibility to reality
IOTA is where the live work is happening. Orion-100B is the published case study that gives the thesis empirical backing, and Macrocosmos is taking IOTA to market with pilot customers in the second half of 2026.
The Backfill Argument
The compute market sits mid-way through the largest capital expenditure in human history, with hundreds of billions committed to GPU buildout right now. Macrocosmos’ question is not who installs the most capacity but who extracts the most intelligence per installed watt.
Liquid training is the answer Macrocosmos is offering: turn the most rigid workload in the AI stack into the grid’s backfill load, let GPU owners capture more value from inference peaks, and squeeze every drop of productive use out of existing capacity. Greater output from the same installed base, better unit economics for suppliers, more total effective flops for the AI economy.
Pilot customers arrive in the second half of 2026, and the Orion-100B results say this is no longer hypothetical. What the market does with that over the next twelve months is the next chapter.
➛ Read the Full IOTA Introductory Thesis Here.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment