
")
More than 300 million scientific papers exist, and 0% are structured as data that a machine can reason over. Frontier models hallucinate scientific references more than half the time (62% for Claude Opus 4.6, 59% for GPT-5.2 on ScholarQABench).
Claims (SN111) is the Bittensor subnet turning scientific literatures into a structured claim-evidence graph, with every claim mapped against supporting and contradicting evidence, whether it replicated, and a calibrated strength score.

The team built SciWeave, the AI research assistant that drove hallucinated references to 0% on a Nature-published benchmark, and Claims is their answer to the harder problem retrieval alone cannot solve.
The Problem Claims Is Solving
A scientist at a biotech asks an FDA-relevant question, tries to vibe-code an AI workflow to read thousands of papers, and gets back fake citations, unreplicated results, and no view of where the literature actually disagrees. Multi-million-dollar decision, no answer anyone can trust.
The structural failures in current AI tooling for science:
1. Frontier models hallucinate citations more than half the time. 62% for Claude Opus 4.6, 59% for GPT-5.2.
2. Retrieval tools fixed fake citations but cannot tell you whether a finding is true. They parrot what an author said without checking replication or contradictions.
3. Most failed replications and negative results never get published. Errors stay in the record while corrections sit in the file drawer.
4. R&D teams spend months and millions reconciling contradictory papers or discovering that a result they bet on never replicated.
R&D intelligence is a $20–$50 Billion market growing with global research spend, and the AI training data market is doubling year on year. Claims sit at the intersection.
The Solution And The Team
Claims turns the scientific literature into a structured claim-evidence graph. Retrieval was the first problem (already solved by SciWeave), but getting the right paper is not enough when a decision rests on whether the findings are real.
The team:
1. Philipp Koellinger: Led a 300+ scientist consortium that fixed the replication crisis in behavioural genetics, built the data standard for the field, and published the results in Nature and Science. Co-founded DeSci Labs and SciWeave.
2. Dr. Christian Roessler: Professor of economics in game theory and mechanism design, building incentive systems that produce the behaviour you actually want.
3. Ogban Ugot: ML (Machine Language) and back-end engineer behind SciWeave who knows where traditional RAG (Retrieval-Augmented Generation) falls short.
A first paid pilot with a drug-discovery startup is already underway, and Claims is launching as Bitstarter’s Proof of Pitch winner.
Why This Belongs On Bittensor
A company could start building a dataset like this. No company can engineer the incentives to improve its quality continuously at the scale required.
The four properties Claims needs:
1. Vast coverage. Hundreds of millions of papers cannot be processed centrally.
2. Extremely high extraction quality. Source-grounded claims with no hallucinations.
3. Adversarially robust scoring. Catching the dropped negations and sign flips that summaries hide.
4. Continuously compounding quality. Forever, with every new contribution sharpening the signal.
How the subnet workflow runs:
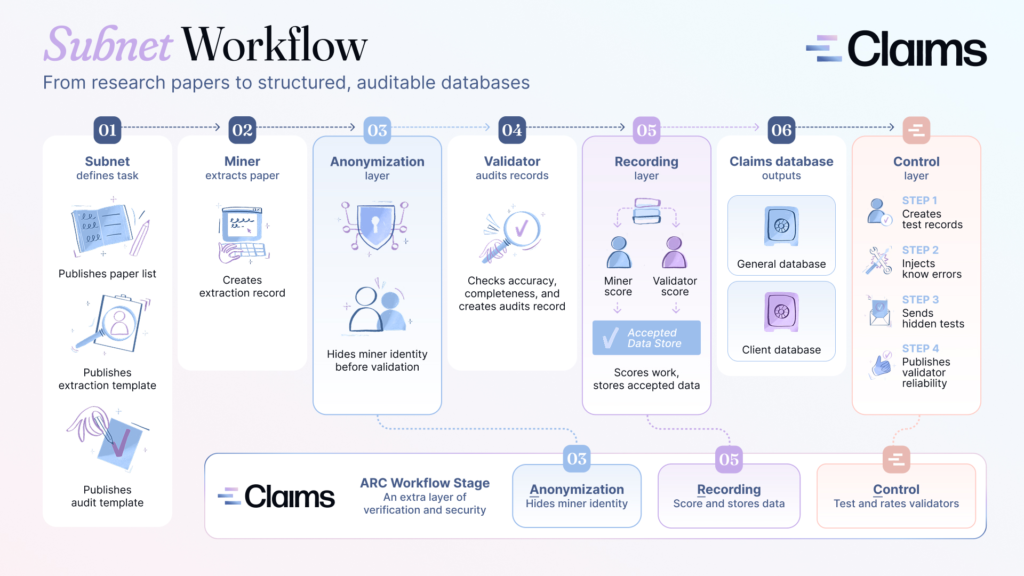
1. The subnet defines the task. Publishes paper list, extraction template, audit template.
2. Miners extract papers across four dependency-gated channels.
3. An anonymization layer hides miner identity before records reach validators.
4. Validators audit records blind. Scoring against a reference model and expert-curated gold data they cannot see, plus adversarial probes.
5. A recording layer scores both sides and stores accepted data.
6. The Claims database outputs to a general dataset and client-specific databases.
Underneath sits a control layer that creates test records, injects known errors, sends hidden tests, and publishes validator reliability scores. Miners are tested by validators, and validators are tested by the control layer. Stake follows the strongest contributors.
The Context Database For Future Research AI
Current AI RAG systems rely entirely on semantic similarity to surface relevant content. Claims combine semantic retrieval with fine-grained structured context, which means better context produces better outputs.
Miners build agents that extract meaning from scientific articles, map concepts to ontologies, and report findings in a structured template, creating the context database for downstream research agents.
Paper, the printing press, microscopes, computers, networks, sequencers, and now AI: each new technology has enabled the next leap in scientific progress, and Claims is building the context database future research AI will run on. The scientific record belongs to everyone, and right now almost no one can use it.
➛ Explore Claim (SN111)’s GitHub Profile Here
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.


Be the first to comment