
")
Sundae Bar (SN121) published a walkthrough of the internal dashboard where its evaluation agents build new challenges in real time.
Taylor ran the camera through every stage of the agent pipeline and showed exactly what each agent produces before the next one takes over.
The video follows a previous X (Formerly Twitter) post that introduced the agents by name. This walkthrough shows the factory floor in motion.
Who Taylor Is
Taylor Sudermann is the head of product at Sundae Bar (SN121). Her background spans digital platforms, audience development, and user experience across technology and gaming, with leadership work on large-scale digital ecosystems, community platforms, and AI-driven tools.
At SN121, she oversees product strategy, challenge design, and evaluation frameworks, with the explicit goal of making sure the subnet’s generalist agent evolves through measurable capability improvements.
The Agent Pipeline in Order
The pipeline runs a chain of specialized agents in sequence with each one producing an artifact the next agent consumes.
Taylor walked through the dashboard live while one challenge was actively being built and another was already complete:
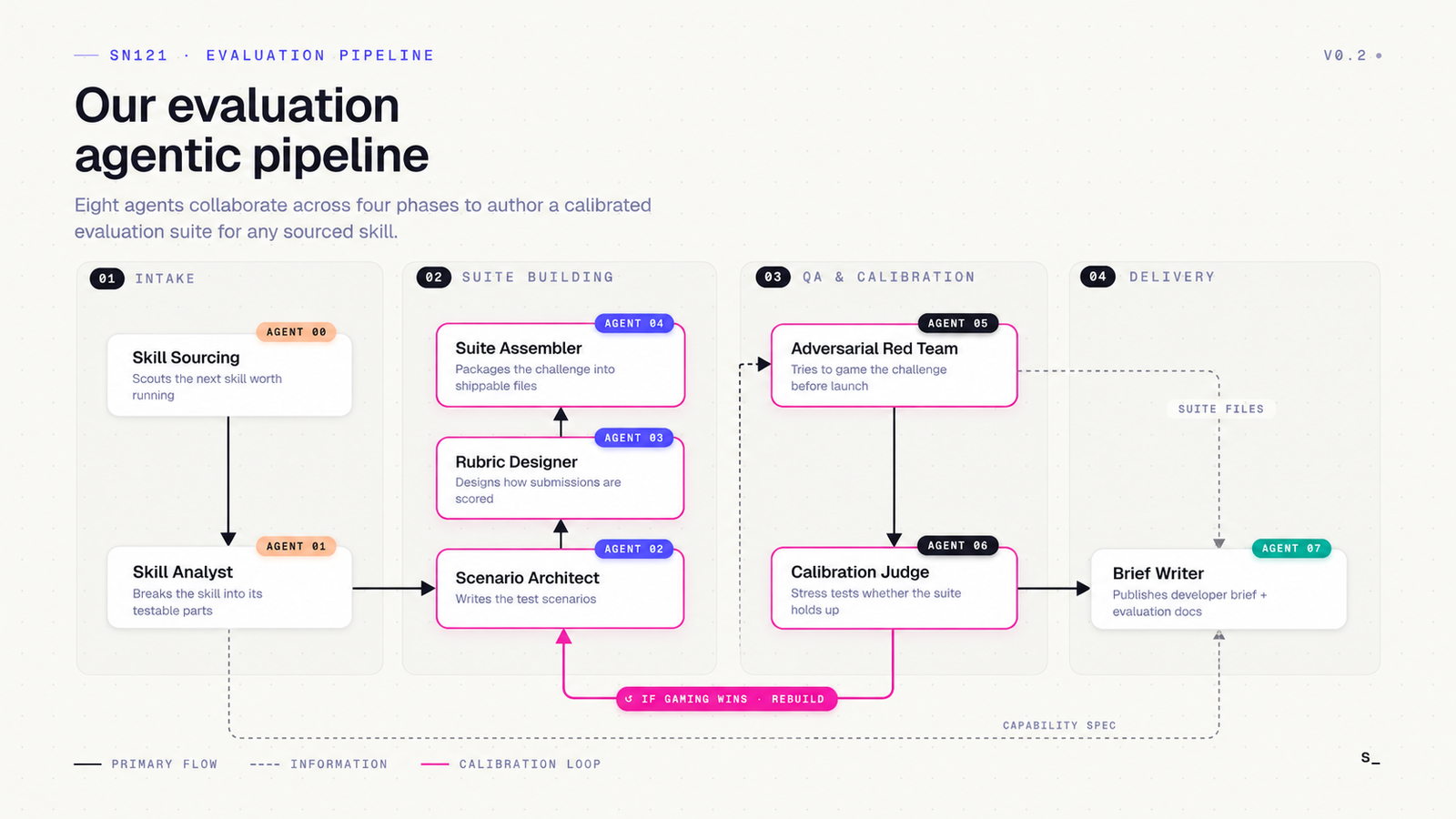
1. Skill Sourcing Agent Hands off a brief on an in-demand skill, with references to the capabilities that skill should cover. This is the entry point for every new challenge.
2. Skill Analyst Takes the brief and builds out the specific capabilities the evaluation should test. The output is a structured description of what the skill should help an agent accomplish.
3. Scenario Architect Creates the actual test cases that go into the evaluation dataset. This is the heaviest step in the pipeline because it requires generating the inputs the tested agent will be given, plus metadata defining what the correct answer looks like.
4. Rubric Designer Builds the rubric the evaluation will score against. The agent reasons through what matters for the specific skill, whether that is tone, following correct steps, exercising sound judgment, or a combination.
5. Suite Assembler Bundles the rubric, dataset, and challenge template into a single runnable evaluation suite. This is the package that gets handed to both the red team and the calibration judge.
6. Red Team Receives the rubric, dataset, and template, then deliberately builds gaming skills. These are skills designed to pass the test without genuinely possessing the underlying capability, including skills that lift examples directly from the dataset and skills that subtly rephrase them. The point is to stress-test whether the evaluation can catch a cheat.
7. Calibration Judge Runs the assembled evaluation against both the reference skill and the red team’s gaming skills. The same evaluation runs against two different model judges in parallel, so the team can see how scoring varies based on the grader model.
The Feedback Loop
The pipeline does not assume the evaluation works on the first pass. The calibration judge’s job is to surface cases where the system gets it wrong, which usually means a gaming skill passes the gate or a reference skill fails it.
1. If a gaming skill passes the gate, the system flags it. The team has to decide whether the graders need improvement or the dataset itself needs work.
2. The feedback is written back into the pipeline as iteration one. The same agents run through the same process again with the new input.
3. The cycle continues until the gating behavior is correct. Reference skills should score fairly. Gaming skills should be rejected. Both conditions have to hold consistently before the challenge moves forward.
This is what Taylor described as looping with feedback until acceptance criteria are met.
The Final Production Test
Once the calibration judge clears a challenge, the team moves it onto actual production infrastructure for a final round of testing.
Taylor walked through one completed example on the dashboard where graders caught the gaming submissions on the first pass, and reference skills received fair scores. The comparison between the two confirmed the evaluation was distinguishing genuine skill from imitation.
From that point, the team has two more options before pushing the challenge live:
1. Human-Team Submission Testing: A person submits skills in various formats to probe edge cases the agent team may have missed.
2. Agent-Team Submission Testing: Another round of automated submissions in different formats to check for scoring variation based on output style.
Only after both passes does the challenge get pushed live on SN121.
The Factory Floor
The walkthrough makes a point that is easy to miss in agent demos. Rather than being in any single agent, the value is in the pipeline that connects them, the dashboard that surfaces each handoff, and the feedback loop that catches errors before challenges go live.
SN121 is treating challenge generation itself as a measurable engineering process, with specialized agents at every step, two parallel judge models, and red team adversarial testing baked in.
Taylor said more videos will follow that dive into each agent and the learnings the team has surfaced so far. The pipeline is now visible on the dashboard for anyone watching the subnet work.
➛ Read More on SN121’s Evaluation Agentic Pipeline Here
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment