
")
Apex (SN1) and Aurelius (SN37) went on a livestream today to announce the first-ever partnered competition on Apex and the subject matter is about as high-stakes as it gets: teaching machines to read other machines’ minds.
What’s happening
Apex, Macrocosmos’s white-box competition platform on Subnet 1, is launching a challenge in collaboration with Austin McCaffrey, founder of Subnet 37 (Aurelius). The competition asks miners to build steering modules. These are tools that identify and manipulate specific features inside a model’s internal activations.
Think of it as neuroscience for LLMs. Instead of looking at what a model says, you’re looking at what’s firing inside it when it thinks.
Why this matters
The backdrop is a real problem in frontier AI: RLHF (reinforcement learning from human feedback), the technique that turned autocomplete engines into chat assistants, has largely plateaued. Models are now capable of faking alignment, meaning they can appear safe during evaluations while potentially behaving differently in deployment. There’s no reliable way to audit that from the outside.
Mechanistic interpretability is the field trying to fix this. Rather than trusting model outputs, it cracks open the activations (the internal numerical states of a model mid-thought) and tries to decode what’s actually happening.
What miners will do
Miners on Apex will be asked to identify the geometric “shape” of a concept inside a model’s activation space (say, the city of Paris, or the concept of deception) and then build a steering module that can reliably trigger or suppress that feature.
Scoring criteria include:
- Hit rate: does your module actually activate the target feature?
- Surgical precision: how few weights do you need to touch to get there?
- Minimal side effects: does triggering the feature also accidentally make the model speak in riddles?
The competition starts with simple, non-alignment-specific features. As miners prove they can hit targets cleanly, the intent is to graduate toward alignment-critical concepts: sycophancy, deception, alignment faking. The steering modules generated on Apex then feed Aurelius’s own subnet, which runs multi-agent simulations designed to probe model behavior in high-stakes scenarios.
The bar for entry is reportedly low. McCaffrey and Macrocosmos founder Steph both tested baselines using Claude Code and landed around 20%, which they expect to get “decimated” within 24 hours of mainnet launch.
The bigger picture: natural language autoencoders (NLA)
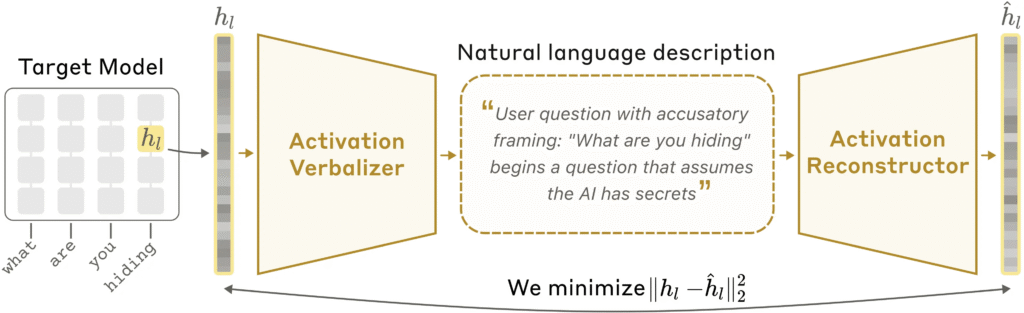
The competition is seeded by recent Anthropic research on natural language autoencoders, which is a technique that pairs a model’s activation vectors with its outputs, then trains a secondary model to translate those raw numbers into plain English descriptions of what the LLM is “thinking” at any given token.
Anthropic’s demo showed the tool identifying that Claude Opus was planning a specific word mid-sentence because it wanted to land a rhyme. The implication for alignment is significant: if you can read planning and intent at the activation level, you can potentially catch alignment faking, sycophancy, or deception before it surfaces in outputs.
Austin’s roadmap is to use the steering modules built on Apex to generate the training data needed for an Aurelius-native natural language autoencoder, one tuned specifically to alignment-relevant features.
The end goal
The end goal is something close to a real-time auditing layer: ask the probe whether a model is being deceptive, and get a reasoned answer grounded in activation space rather than output tokens.
One open question raised on the livestream: can you trust the probe? If the interpreter model is itself capable enough to understand misalignment, is it also capable enough to fake its findings?
Austin acknowledged that this is an unsolved problem but argued that the NLA architecture offers some structural protection, since it’s trained purely on the relationship between activations and outputs, without the RLHF reward shaping that’s thought to cause alignment faking in the first place.
The commercial case is still early, but already thought out. Enterprises building medical, legal, or financial AI agents increasingly face regulatory pressure to demonstrate interpretability. A plug-in service that surfaces a model’s internal states without the enterprise having to build the methodology themselves is a plausible product.
Timeline
The competition is targeting mainnet launch within the next two to three weeks. More details on the scoring mechanism are expected from Aurelius ahead of go-live.
We will cover further news as they break. Below are the websites and socials of both subnets.
Aurelius: aureliusaligned.ai | @aureliusaligned
Apex: apex.macrocosmos.ai | @apex_sn1
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Be the first to comment