

A subnet on Bittensor has built an AI safety model that beats every open guard model in existence, including ones built by companies with vastly more resources.
The model is 10 to 30 times smaller than the systems it just outperformed. It was trained entirely through a decentralized, adversarial process running on-chain, not inside a closed corporate lab. This is the kind of result Bittensor has been promising the world for years, and now there is a benchmark table to prove it.
What Happened
Trishool (SN23) announced that its safety classifier, HaloGuard 1.0, has reached state-of-the-art performance among open-weight guard models. A guard model is the piece of software that checks whether a prompt going into an AI system, or an action an AI agent is about to take, is safe or dangerous before it happens. Think of it as airport security for AI: every request gets scanned before it is allowed through.
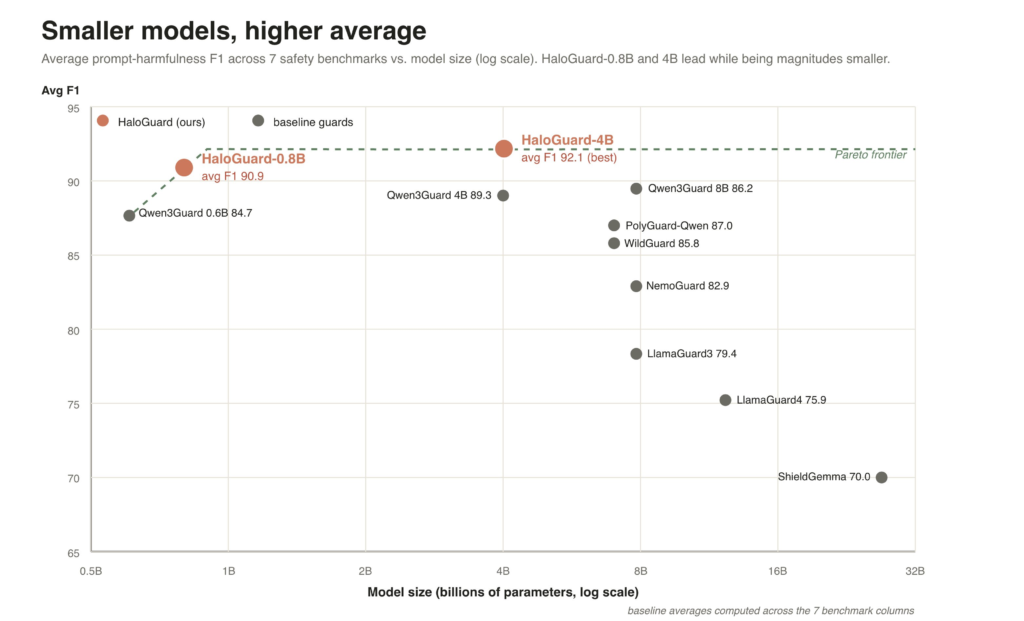
HaloGuard 1.0 comes in two sizes, and both post the best average scores among the open guard models available on the market:
- HaloGuard 1.0 (0.8B parameters): 90.9 average F1 across seven safety benchmarks
- HaloGuard 1.0 (4B parameters): 92.1 average F1, the strongest result of any model in the comparison
Here is how that stacks against the established names in the space, all of which are dramatically larger:
| Model | Size | Average F1 |
|---|---|---|
| ShieldGemma | 27B | 70.0 |
| LlamaGuard4 | 12B | 75.9 |
| NemoGuard | 8B | 82.9 |
| Qwen3Guard-Gen | 8B | 86.2 |
| WildGuard | 7B | 85.8 |
| PolyGuard-Qwen | 7B | 87.0 |
| HaloGuard 1.0 | 0.8B | 90.9 |
| HaloGuard 1.0 | 4B | 92.1 |
A model built by a decentralized network of anonymous contributors just beat Nvidia’s NemoGuard, Google’s ShieldGemma, and Meta’s LlamaGuard4 on the exact benchmarks those labs use to measure themselves.
The 0.8B version alone means the win came from a model roughly a tenth the size of the 8B competitors and a thirtieth the size of ShieldGemma.
Why Being Small and Accurate at the Same Time Is Hard
Imagine hiring airport security. You want them to catch every dangerous item, but you also don’t want them stopping every grandmother with a tube of toothpaste.
Every guard model in the world balances on that same tightrope, missing real threats on one side and flagging harmless requests on the other. Getting both right at once, called moving the false-positive and false-negative frontier, is the actual hard problem in AI safety.
HaloGuard 1.0’s numbers show it moved that frontier further than anyone else has published:
- False positive rate of 4.3% on the 0.8B model, meaning it rarely blocks a legitimate request
- False negative rate of 9.5% on the 0.8B model, dropping to 7.7% on the 4B version, meaning it rarely lets something dangerous through
- Precision above 91% and recall above 90% on both model sizes
Most guard models get this balance wrong by leaning too hard in one direction. A guard that blocks too much becomes unusable, since people just turn it off. A guard that blocks too little is not a guard at all. HaloGuard’s numbers suggest it found a rare middle ground, and it did so while also running fast enough to sit directly inside a live agent’s decision loop rather than as a slow add-on service.
How the Team Built It
Having learned about the significance of this milestone, it’s tempting to ask how the team built this, and this win did not come from simply making a smaller copy of an existing model.
Most guard models are built the old way: collect a pile of text from the internet, pay humans to label each example as safe or unsafe using a short fixed list of categories, then train on that. Trishool threw that approach out. Instead, the team wrote what they call a constitution, a structured document defining exactly what counts as harmful and why, then used that document to generate the training data itself rather than collecting it after the fact.
The scale of that constitution is the real deal for anyone who understands the space:
- 46 constitutional policy files, breaking down into 490 categories and 2,940 fine-grained subcategories, over two orders of magnitude finer than the flat 9-to-14-label systems older guard models rely on
- A 1.26 million record synthetic training corpus, built from a mix of established safety datasets (WildGuard, Aegis, Aegis 2.0, ToxicChat, XSTest) plus purpose-built adversarial and false-positive-recovery data
- Paired counterfactuals for every harmful subcategory, meaning every dangerous example is matched with a nearly identical benign example on the same topic, so the model learns intent rather than just learning to fear certain words
- Coverage across 46 languages, treating language as a normal variation rather than a loophole attackers can exploit
The counterfactual pairing is worth sitting with for a moment because it is a genuinely clever solve to a problem every safety team runs into.
A naive guard model sees a sensitive keyword and blocks it every time, catching an actual bad actor but also blocking a student, journalist, or historian asking about the same topic from a legitimate angle.
Trishool’s training data pairs a harmful, operationally-intended version of a sensitive question against a benign version on the exact same topic asked from a historical, legal, or scientific angle instead. The model is shown nine different legitimate framings for sensitive topics, including legal, historical, scientific, journalistic, and clinical angles, so it learns to judge intent instead of pattern-matching on scary vocabulary.
The Loop That Never Stops
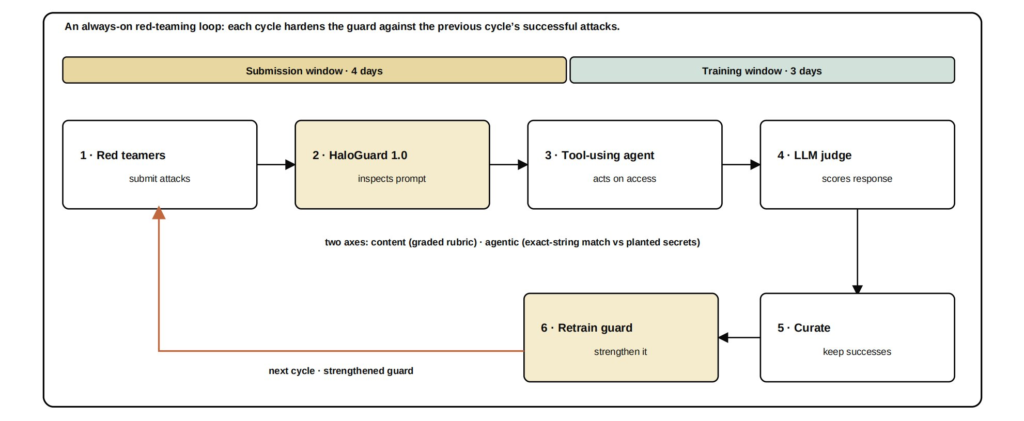
The model that just hit SOTA is not a finished product sitting still. It is the current snapshot of a red-teaming cycle that runs continuously on the subnet:
- Red teamers submit attacks, trying every jailbreak and prompt injection technique available
- HaloGuard inspects the prompt before anything downstream sees it
- A tool-using agent acts on whatever access it has been granted
- An LLM judge scores the outcome against a graded rubric and planted-secret checks
- Successful attacks get curated into the next training set
- The guard gets retrained and hardened against everything that broke it
Each cycle runs on a four-day submission window followed by a three-day training window, meaning the model gets meaningfully harder to break roughly every single week.
That is the part a static, once-a-year model release from a centralized lab structurally cannot match. Every open guard model in that comparison table is a frozen snapshot. HaloGuard is a moving target that gets stronger every week miners keep showing up to attack it.
Why This Matters for AI Far Beyond Bittensor
AI models are no longer just chatbots answering questions in a text box. They are agents with access to email inboxes, bank accounts, production databases, and the ability to take real actions in the real world without a human checking every step.
That access is exactly what makes AI useful, and it is exactly what makes an unguarded AI dangerous. A model that can read a malicious webpage and then act on hidden instructions buried in it, or one that can be tricked into deleting files or leaking private data, is not a hypothetical risk. It is already happening in early agent deployments across the industry.
The standard fix has been to bolt a large, separate safety model in front of every request, but large safety models are slow and expensive, which is exactly why so many companies skip real protection or run a thin, easily fooled version of it instead.
What Trishool just demonstrated is that this tradeoff was never actually necessary. A model small enough to run on a laptop, responding in a fraction of a second, can outperform safety systems many times its size.
That changes the economics of AI safety for everyone. It means a startup with no budget for enterprise security infrastructure can plug in a genuinely state-of-the-art guard for free, and it means large platforms have no more excuse to skip protection in the name of latency or cost.
There is also a bigger structural point buried in how this model was built. HaloGuard did not come out of one company’s internal red team working in secret for months. It came out of an open, adversarial, continuously running competition where anyone in the world could try to break it and get paid for finding the cracks. That is a fundamentally different way to build trust in a safety system than taking one lab’s word for it, and it is a model the rest of the AI industry does not currently have an equivalent for.
The Ecosystem Behind the Milestone
This result lands during a genuinely strong stretch for Bittensor’s subnet layer more broadly. Chutes (SN64) has become a default inference layer other subnets integrate against, and it was the first partner to put an earlier version of Trishool’s guard model in front of live production traffic. Macrocosmos’s IOTA (SN9) has pushed decentralized pretraining results that outperform comparable centralized baselines. Quality subnets like Vidaio (SN85), BitSec (SN60), and Yanez (SN65) have each shipped real commercial traction this year. Retail plumbing is showing up too, with recent TAO and subnet token listings on tier-1 exchanges like OKX and Kraken.
Trishool’s HaloGuard result fits squarely into that pattern: a subnet quietly grinding through a specific, hard, and previously assumed-difficult technical problem, then producing a benchmark result that stands on its own outside of any Bittensor context entirely. That is the strongest version of the pitch dTAO was designed to prove, that market incentives pointed at a real problem can out-compete a closed lab working in isolation.
On the announcement itself, Bittensor co-founder Const congratulated the team and miners on Subnet 23 for reaching SOTA and noting that when the incentives work, they invariably win. Trishool’s founder mentioned the milestone as a beginning rather than an end, noting the result caps roughly seven months of subnet-supported research and development and that a full arXiv paper is on its way, with response-side moderation, streaming output checks, multi-turn monitoring, and agentic tool-use safeguards named as the next targets.
What Comes Next
HaloGuard 1.0 only covers the input side of the safety problem, meaning it catches dangerous requests before they reach a model or agent. The harder half of the problem, catching dangerous actions after an agent decides to take them, is still ahead.
The team has highlighted response-side moderation, streaming output moderation, multi-turn conversation monitoring, and full agentic and tool-use safeguards as the next phases, and the weekly red-teaming loop that got HaloGuard here does not stop just because one milestone was hit.
Model weights for both sizes are already public on Hugging Face, so anyone curious enough to check the claims themselves can start now rather than waiting for the paper.
If the input guard alone is already beating every open competitor at a fraction of the size, the output guard is definitely worth watching next.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Enjoyed this article?
Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox — every morning before markets open.


Be the first to comment