
AI models are getting more capable by the day, and capability without a brake pedal is a liability. Somewhere on Bittensor, a subnet has spent the last several months building that brake pedal, then proving it works at a fraction of the size anyone thought was possible.
That subnet is Trishool (SN23), and its safety classifier is now sitting in front of live production traffic. The pitch is simple enough for anyone to understand: small, fast, and hard to fool beats big, slow, and expensive.
What Trishool Does
Think of Trishool as a bouncer for AI. Every time an AI agent receives an instruction or is about to take an action, that bouncer checks whether the request is safe to let through. If someone tries to sneak in a dangerous request dressed up in clever language, the bouncer is trained to catch it anyway.
This matters more than it might sound like at first. AI agents today read emails, browse the web, touch production databases, and move funds. Every one of those surfaces is an opportunity for something to go wrong, whether through a malicious prompt slipped into a webpage or an agent simply misjudging what it should be allowed to do. Trishool exists to sit between the agent and the world, filtering dangerous input on the way in and blocking dangerous actions on the way out.
The subnet runs on what it calls a Tri-Cameral Economy, splitting the work into three interlocking roles: component builders who produce the underlying safety models, red-teamers who continuously attack those models to find gaps, and a delivery layer that packages the result into a usable product.
The Weekly Fight Club
Here is where it gets genuinely interesting for anyone who has watched other Bittensor subnets operate.
Trishool runs a recurring adversarial competition. Each week, the team defines a harm category and generates a set of challenge questions. For four days, miners throw every jailbreak technique they can think of at the current model, from social engineering angles to prompt injection tricks, all logged on a live leaderboard. The remaining three days go to retraining the model on whatever broke it, and then the cycle starts over with a new topic.

Fourteen weeks of that loop has produced a serious body of adversarial data. Some notable numbers from the process:
- Close to 12,000 distinct jailbreaks collected and used to harden the model
- A constitution spanning roughly 30 defined harm categories paired with 15 harmless boundary categories, so the model learns intent rather than just flagging keywords
- A live, public testing ground where anyone can try to break the model themselves through Chutes Chat
That last point is worth sitting with. Most safety teams test in private and publish a paper months later. Trishool’s red-teaming happens in the open, on-chain, with the results feeding directly back into the next model version within the same week.
The Headline Number: 0.8 Billion Parameters

The core product is called Halo Guard Alpha, and its calling card is size. The model runs at 0.8 billion parameters, which puts it in the same weight class as GPT-2 from several years ago, not the multi-billion-parameter guard models most of the industry treats as the baseline for serious protection.
According to the SN23 team, Halo Guard Alpha posts an average F1 score of 89.0 across seven public safety benchmarks (ToxicChat, OpenAI Moderation, Aegis, Aegis 2.0, WildGuard, HarmBench, and Simple Safety Tests), landing ahead of several established guard models that are many times its size:
- Outperforms NemoGuard-8B, an 8-billion-parameter model from Nvidia
- Outperforms WildGuard-7B, a 7-billion-parameter model
- Outperforms PolyGuard-7B, another 7-billion-parameter model
Independent third-party benchmarking of these same guard models, such as the comparisons published in the OpenGuardrails paper, confirms the broader pattern the team is pointing at: smaller, purpose-built classifiers can genuinely compete with and beat much larger general-purpose guard models on safety benchmarks.
Although the result was self-reported by the Trishool team, their finding lines up with what the rest of the guardrail research community is finding this year.
A big question would be why does the parameter count matter so much?
Because a safety layer that adds noticeable delay is a safety layer developers will eventually route around. Halo Guard Alpha classifies in under 100 milliseconds and is small enough to run on a laptop or even a phone, which means it can sit directly inside an agent’s execution path instead of bolted on as a separate, slow service.
Proof It Is Not Just a Pitch Deck
Plenty of subnets talk a big game. Trishool has receipts.
- Chutes (SN64) adopted Halo Guard Alpha as its live security layer. The integration put Trishool’s classifier in front of Chutes’ inference stack and Chutes Chat, meaning real production traffic is running through it today, not a testnet.
- Google for Startups accepted Trishool into its Web3 program, unlocking up to $200,000 in Google Cloud credits over two years plus direct access to Google’s Web3 engineering team.
- Trishool has also secured a spot in AWS’s startup program, adding to a combined compute war chest reported in the hundreds of thousands of dollars, all of which goes straight back into training runs.
How Trishool Stacks Up Against Giants
The safety and guardrail space has no shortage of contenders, so context matters:
| Model | Approx. Size | Positioning |
|---|---|---|
| Halo Guard Alpha (Trishool) | 0.8B | Sub-100ms, runs on edge devices, trained via continuous decentralized red-teaming |
| WildGuard-7B | 7B | Strong general-purpose guard model, heavier footprint |
| PolyGuard-7B | 7B | Multilingual guard model, heavier footprint |
| NemoGuard-8B | 8B | Nvidia’s guard model, built for enterprise pipelines |
The other guard models on that list come out of centralized labs with fixed training runs. Trishool’s model instead gets rewritten every single week by an open competition that anyone can join, which means its defenses are not a snapshot frozen at release but a living target that keeps moving as new attack techniques surface.
Where This Goes Next
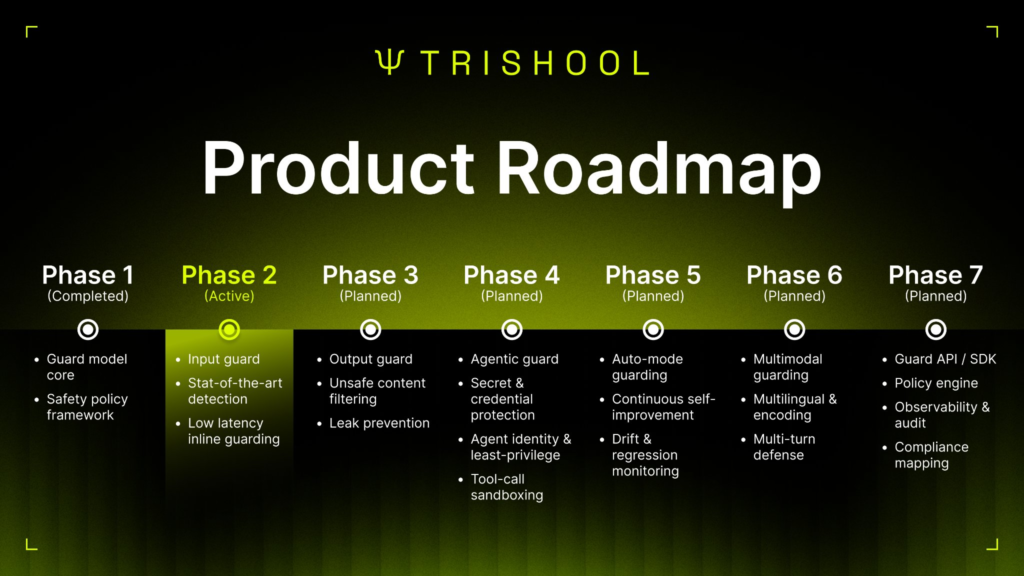
The subnet’s own roadmap breaks into phases, and it is currently working through the middle of that sequence. So far it has built and largely proven the input side, the layer that catches a dangerous request before it ever reaches an agent.
Next up is the output guard, the layer that catches a dangerous action after an agent decides to take it, which is what would have caught the file-deletion jailbreak attempts that slipped past the current version during live testing. After that comes agent-specific guards tuned to particular workflows, then a fully autonomous protection mode.
The team has said it is targeting 98 to 99 percent effective coverage once the input and output guards are both live, with a longer-term push toward the high end of that range as agent-specific guards mature. If that target holds, Trishool is not just building a clever subnet. It is building the kind of trust infrastructure that could let it sell directly into regulated industries, financial institutions, and any enterprise now under pressure to prove its AI systems are really safe.
Trishool is proof that Bittensor’s incentive model can produce something the centralized AI labs have not: a safety layer that gets better every single week because thousands of anonymous participants are paid in TAO to try to break it.
A 0.8 billion parameter model beating guard models ten times its size is proof that decentralized, adversarial training beats a single lab’s internal red team working in isolation. The subnet already has paying infrastructure running through it and cloud credits from two of the biggest names in tech backing its runway. If the output guard lands anywhere near where the team says it will, Trishool will have built something the rest of the AI industry eventually has to reckon with.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.



Be the first to comment