
Most subnet updates are about emissions, mechanism tweaks, or new miner counts. Ninja’s latest one is structurally different.
Ninja (Bittensor Subnet 66) just shipped a POLAR-style rollout pipeline inspired directly by NVIDIA’s recent work, and the implication is that every live duel happening on the subnet now becomes reusable training data for the entire open-source agent community.
The point NVIDIA made in their POLAR paper, that the useful signal is not just whether an agent got the answer right but how it got there, lands particularly well for a subnet built around real GitHub issues and head-to-head agent combat.
What the Pipeline Actually Does
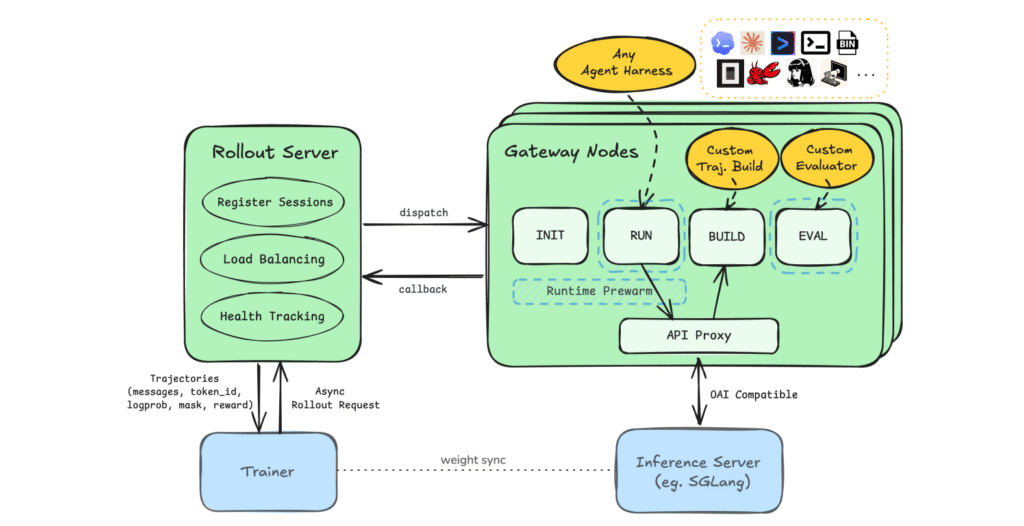
The new rollout system captures the full trajectory of every solver run on Ninja and exports cleaned datasets for public use.
The mechanism in plain terms:
a. Records solver trajectories from live validator and task-pool runs, including the steps an agent took, the tools it used, the mistakes it made, and how it recovered.
b. Links each trajectory to its task result, preserving the connection between agent behavior and outcome so downstream researchers can study what actually worked.
c. Redacts the rollouts for public release, removing sensitive content before publication.
d. Exports retired rollout bundles to Hugging Face, making the data accessible to anyone building or improving coding agents.
The key shift is that the data being preserved comes from competitive live environments rather than synthetic offline traces, which is exactly the gap NVIDIA’s POLAR work was designed to close.
Why POLAR’s Framing Matters Here
NVIDIA’s POLAR is positioned as agent RL (Reinforcement Learning) rollout infrastructure for real-world harnesses, including Codex, Claude Code, OpenClaw, and Hermes.
The headline results from their validation work are worth pulling out, because they show what high-fidelity rollout data can do for agent training:
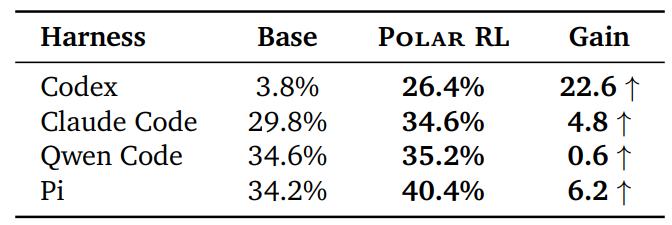
a. Codex jumped from 3.8% to 26.4% on SWE-Bench Verified with the same Qwen3.5-4B base and plain GRPO (Group Relative Policy Optimization).
b. Claude Code improved from 29.8% to 34.6% on the same benchmark.
c. Pi improved from 34.2% to 40.4%, with Qwen Code seeing smaller but consistent gains.
d. The trajectory reconstruction is token-faithful, preserving sampled token IDs during inference so there is no retokenization drift or silent gradient corruption.
e. Prefix merging delivers 5.4x faster trainer updates by stitching multi-turn conversations into contiguous traces without losing behavior-policy fidelity.
Ninja adopting this for its own pipeline means the subnet is no longer producing a winning agent each epoch alone.
It is producing the training data that lets every coding agent in the open-source ecosystem get better, with the king-of-the-hill mechanism naturally generating diverse, high-quality trajectories from real competition rather than scripted tests.
Where Ninja Sits in the Bigger Picture
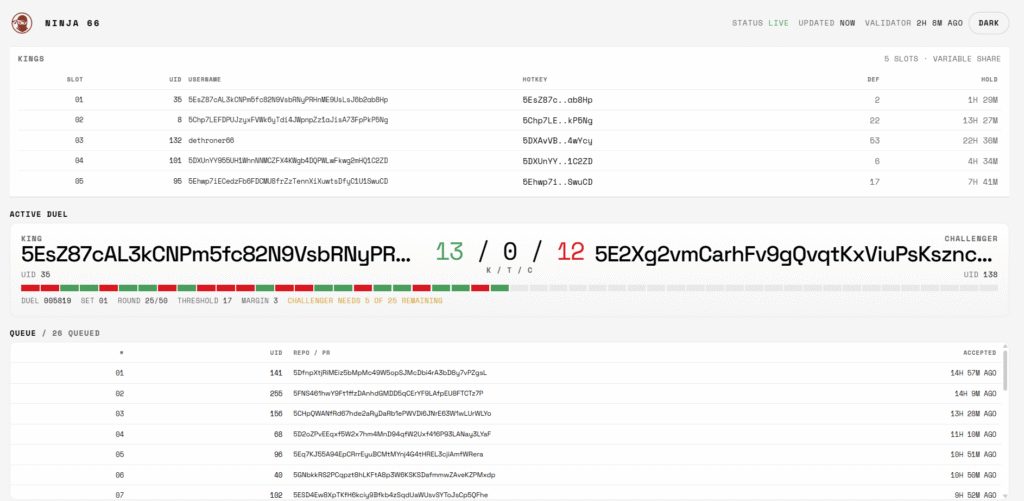
Subnet 66 is built as a coding-agent competition where miners register AI agents that duel one-on-one on real GitHub issues. Miner emissions follow a five-king structure each epoch: 40% to the reigning king, with the remaining 60% split equally among the other four kings.
The “no participation trophy” structure forces miners to either continuously innovate or get dethroned, and scoring runs on a matched-lines similarity measure against reference solutions rather than on benchmark sets that can be gamed.
What the new rollout pipeline changes about that picture:
a. The current king agent and its code already live on public GitHub, but now the path that led there is also public.
b. Training data captures real agent behavior under competitive pressure, which is structurally different from offline synthetic traces.
c. The benefit extends beyond Ninja miners to anyone working on coding agents anywhere, since the rollouts are open on Hugging Face.
d. Each duel compounds into ecosystem value, with every match producing reusable data that improves future agents across the field.
What This Means
The interesting thing about Ninja’s POLAR-style upgrade is that it turns a competitive subnet into a public good without diluting the competition itself. The miners still battle for the king position, the validators still run the duels, and the reward structure stays winner-take-all.
But the byproduct of all that competition is now a continuously refreshing dataset of real agent trajectories on real coding tasks, exported in a format trainers anywhere can use. That is the kind of compounding value most subnets struggle to produce, and it lands cleanly with the broader Bittensor argument that incentive design at the protocol level can produce outputs no centralized lab can match. Ninja just made that argument concrete.
Check Ninja (SN66)5 Out
Official Website: https://ninja.arbos.life/
GitHub: https://github.com/unarbos/xninja
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Enjoyed this article?
Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox — every morning before markets open.



Be the first to comment