

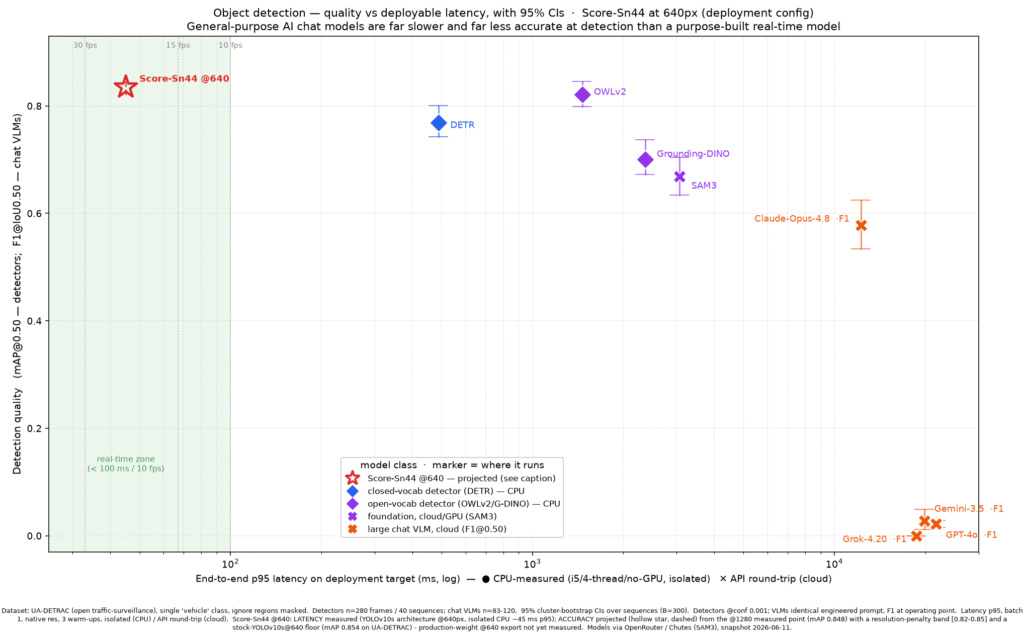
Score (SN44) published its public benchmark, and the result is a 19 MB distilled vision detection model from the subnet that beat GPT-4o, Gemini, Grok, Claude, SAM3, Grounding-DINO, OWLv2, and DETR on accuracy at vehicle detection. The model ran 9x to 130x faster than the field on a cheap 4-thread CPU with no GPU and no cloud.

The benchmark task was vehicle detection on the public UA-DETRAC dataset, but Score’s thesis is that the pipeline behind the result generalizes to any detection task a camera needs to perform. The model is called Score-Sn44, and it is the first benchmarked unit from a production line SN44 plans to repeat across every detection skill.
The Headline Result
The benchmark scored each model on the metric that fairly represents its output class, which is the right move when comparing detectors against chat models:
| MODEL | SCORE | SPEED | SIZE | HARDWARE |
| Score-Sn44 | mAP 0.848 | 167 ms/frame | ~19 MB | CPU only |
| OWLv2 (best foundation detector) | mAP 0.821 | 9x slower | larger | GPU |
| Claude (best chat model) | F1 0.58 | ~12 sec/frame | cloud only | datacenter |
| GPT-4o, Gemini | F1 ~0.00 | cloud only | cloud only | datacenter |
| Grok | F1 0.00 | cloud only | cloud only | datacenter |
A 640px export of the same model ran at roughly 45 ms per frame on CPU, comfortably real-time, with accuracy projected between 0.82 and 0.85. The 1280px run sits at 6 fps on CPU, technically just outside a strict 10 fps real-time bar but still the fastest model in the test.
Why the Frontier Chat Models Collapsed
Score made a point of testing the frontier chat models because customers keep being sold the idea that they can point a chat API at their camera feeds. The data killed that idea:
1. GPT-4o and Gemini scored F1 near zero. They emit thousands of bounding boxes per frame, and the boxes do not land on the objects.
2. Grok scored exactly zero. No usable detection at all.
3. Claude was the only chat model that managed a mediocre F1 of 0.58. It still took over 12 seconds per frame and runs only in the cloud.
Score’s argument is that this is a category error, not a failure of those models. Autoregressive chat models do not produce the dense spatial grounding and ranked-confidence outputs that detection requires. Scale does not fix a tool-class mismatch. The same gap shows up whether the task is vehicles, smoke, intrusions, safety gear, or stock on a shelf.
Why a 19MB Specialist Wins at the Edge
Real computer vision lives at the edge: intersections, motorways, warehouses, forecourts, factory lines, drones. The edge enforces four constraints the giants cannot satisfy:
1. No GPU: Deployed cameras run on cheap CPUs or tiny edge boxes. SAM3 wants a 24 GB GPU per stream. GPT-4o lives only in a datacenter.
2. Real Time or Bust: Live feeds give milliseconds per frame. A model that takes 22 seconds is useless if the event has already passed.
3. No Cloud: Bandwidth, cost, and privacy forbid streaming every frame to an API. Edge models run offline, on site, on the raw feed.
4. Scale: Real operations run thousands of cameras with multiple detection jobs each (count vehicles, spot smoke, watch safety zones). Small specialists stack on the same cheap box. Giants do not.
A city wanting real-time analytics at 500 intersections, with no new hardware and no video leaving the device, has one option on Score’s chart. A leaderboard winner that cannot run on the pole is not useful at the edge.
The Methodology That Holds Up to Scrutiny
Score built the benchmark expecting expert pushback, and the report shows the work:
1. Open, In-Domain Data: UA-DETRAC, 280 frames across 40 sequences for detectors, with ignore regions masked before scoring.
2. Right Metric Per Model Class: mAP@0.50 for ranked detectors, F1@IoU0.50 for chat models. Applying mAP to models that do not output ranked confidences would have punished them unfairly.
3. Engineered Prompt Published: Chat models got their best-case scoring with a published prompt.
4. Latency Measured Honestly: Per-frame p95, batch 1, each model in isolation on an i5-class 4-thread CPU. Cloud models labeled separately as API round-trips.
5. 95% confidence intervals on every point. Score-Sn44’s interval clears the entire field.
No projections were plotted. Only measured numbers. The team flagged one open question themselves: a 640px export should push the model firmly into real-time territory, but they have not plotted it because the production weights have not been measured yet. That number will arrive with error bars when ready.
The Pipeline Is the Story
The chart is one data point. The argument is about the production line behind it:
1. Distillation Is Not A One-Off Trick: Every detection skill on the Score network (fire, vehicles, people, events on a pitch) comes out of the same process: define the task, open it to adversarial competition between miners, let the incentive mechanism compress the best capability into the smallest deployable model.
2. Score-Sn44 Is The First Unit Benchmarked In Public: More are coming. The same harness, the same protocol, the same error bars will be applied to each one.
3. The Thesis Is That The Frontier Of Operational Vision Ai Moves To The Edge: Not one specialist, but a growing library of them, each tuned to a specific task and small enough to run on the hardware the world already owns.
The Distillation Argument
Score’s first public benchmark is a clean win against every major frontier model at the one task that matters for production cameras: precise, real-time object detection on cheap hardware. The 19 MB specialist beat OWLv2, the best foundation detector, on accuracy while running 9x faster on a CPU. The chat models did not get close. The vehicle detection task is the proof point. The pipeline behind it is the product. Score’s bet is that the same adversarial mechanism that produced Score-Sn44 will produce the next specialist, and the next, and the one after that. The frontier of operational vision AI moves on Bittensor, not in the cloud.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment