
")
NOTE: The full article was written by mono † on X. Full credit goes to the author.
The idea in plain English
Before the jargon, here is the whole thing in plain terms. When an AI recognizes a photo, it is not really seeing a dog or a stop sign (or whatever there is in the photo), it is doing math on the numbers behind the pixels and matching patterns it picked up in training. Because it is “only math”, you can make tiny changes to those numbers, far too small for a person to notice, that completely flip the answer, so the picture still looks like a stop sign to you while AI now reads it as something else entirely. These tampered inputs are called adversarial examples, and they are not a glitch but a basic weakness in how these systems work. The same trick has already fooled real cars into misreading speed signs (good luck telling that in court), and it can hit medical scanners, fraud filters and content moderation just as easily. Perturb’s bet is that the best way to find these weak spots is not to hire one lab for a few weeks but to open the problem to a global crowd that competes to break AI models before real attackers do, and gets paid for it. The rest of this piece is about whether that bet holds up.
The trick on the homepage
The first thing Perturb shows you is a magic trick. A photo gets read by a classifier as a panda at 57.7% confidence, a thin layer of noise gets added, and the same picture is now a gibbon at 99.3%. To your eye nothing moved, but to the model – everything did. That exact panda-to-gibbon flip is the canonical adversarial example from Goodfellow’s 2014 FGSM (Fast Gradient Signed Method) paper, and Perturb leans on it because it makes an abstract failure mode physical in about one second.
Their live demo runs the same idea on the model they actually launched with. A dog that EfficientNet-B5 calls a Rhodesian Ridgeback at 59.2% gets a sliver of FGSM noise, and the prediction snaps to Irish Terrier at 94.3%. The image is visually identical, at least to a human’s eye. The mechanic underneath is simple: the attack reads the gradient of the loss with respect to the input pixels, then nudges those pixels in the direction that maximizes the loss, staying inside a budget small enough that no human notices.
That’s a structural property of how neural nets carve up high-dimensional space, and it shows up in medical imaging, face recognition, content moderation, fraud detection, and anything with a camera tied to a decision. The tooling to find these weaknesses before they ship exists, but it is fragmented, expensive, and static. These existing tools do not get better on their own. Perturb’s bet is that a market does.
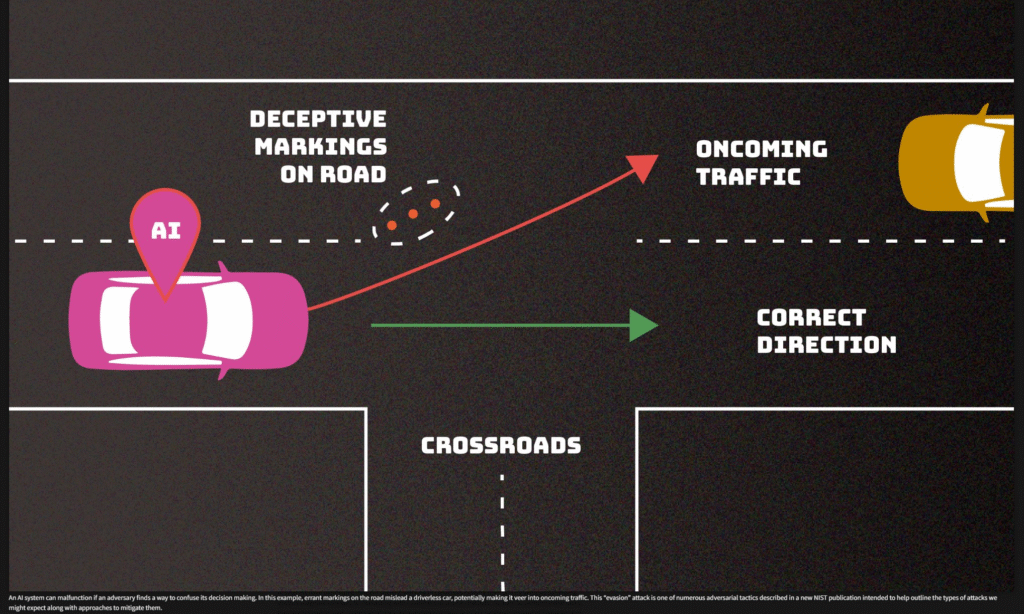
The real world has already paid for this. In 2020, McAfee researchers put a small, almost invisible strip of black tape on a 35 mp/h speed sign, and a Tesla’s camera read it as 85, accelerating the car around 50 mph past the limit in testing, and earlier work out of UC Berkeley used ordinary-looking stickers to make a stop sign register as a speed limit. In its March 2025 taxonomy of adversarial machine learning, NIST (US National Institute of Standards and Technology) states plainly that there is no foolproof defense a developer can employ, which is the whole reason a continuous testing layer, rather than a one-time audit, is the right shape for the problem. You got it right, it’s the role Perturb is aiming to fill.
So, what is Perturb?
Perturb is a Bittensor subnet where validators hand out adversarial-image challenges and miners get paid for finding the smallest perturbation (disturbance) that fools a fixed classifier, with every result checked by an LLM before it counts. The pitch is that the network becomes the first financially motivated, continuously improving adversarial testing layer, and that it spits out two things you can sell: an adversarial training dataset, and on-chain robustness certificates.
That is the story. Now the test.
The 4-criteria read
I run every subnet (I’m doing my research on) through the same 4 questions, because they separate a real incentive mechanism from a token with a GitHub repo. Is the problem actually hard? Is there real ground truth to score against? Does the scoring create genuine competition? And does the network produce a measurable output someone would pay for? Perturb is interesting because it scores well on the first one and has honest open questions on the rest.
1. is the problem hard?
Yes, and in the specific way Bittensor needs. The value of a subnet comes from an asymmetry: the work has to be expensive to produce and cheap to verify. Adversarial example generation sits almost perfectly on that line.
Finding a minimal perturbation that flips a strong classifier is a real optimization problem. FGSM, the single-step method in the homepage demo, is weak against a model like EfficientNet-B5, which is exactly why the team picked that model for phase 1. The whitepaper says basic FGSM performs poorly here, so miners have to reach for repetitive methods and they need a GPU to run them. Verifying the result, by contrast, is simple: run the model once, check the output, measure the size of the perturbation.
There is deeper theory backing the difficulty too. Adversarial vulnerability is partly baked into the geometry of these models rather than a training bug you can fully wipe out. That is why the problem doesn’t get solved once and for all, it’s a moving target, and chasing a moving target is exactly what a perpetual incentive network is built to be good at.
Verdict: the hardest criterion to fake is the one Perturb passes most cleanly.
2. is the ground truth real?
This is where you have to read the GitHub, not the whitepaper, because the README is more honest about how things are done.
The validator builds each challenge through a verified loop. It pulls an image from the Pexels search API using a label as the query, runs EfficientNet-B5 on that image to get the model’s predicted class, then calls a local Qwen2.5-1.5B endpoint to confirm the model’s label matches the search term. Only when that check passes does it become a challenge, and the label the miner has to break is the exact label EfficientNet-B5 produced on the clean image. The miner sends back only the perturbed image, never the method. The validator then runs its gates: the pixels have to be in range, the perturbation norm has to sit between a floor and a ceiling (both too small and too large are rejected), and the LLM has to confirm the model’s new prediction is genuinely a different thing. ELI5: The validator is a quiz master who first finds a clear photo (a dog from Pexels, for example), confirms the AI being tested actually reads it as “dog” and that a second AI agrees the label fits, and only then turns it into an official challenge. The miners compete to tweak that photo just enough that the AI stops seeing a dog while it still looks like a dog to you, and they hand back only the altered image without showing how they did it. The validator then checks that the change wasn’t too small or too heavy and that the AI now truly sees something else, and any answer that misses those marks scores a flat zero.
TL;DR: The validator sets up a verified “fool this classifier” challenge, miners submit only their manipulated/altered image, and it counts only if the perturbation stays within bounds and genuinely flips the model’s prediction, otherwise it’s zero. Like my chances with that hot chick that works at Zara.
The ground truth is the model’s own clean prediction, not a human gold label. The loop is internally consistent, which is what matters for scoring, but it means a “robustness certificate” from Perturb certifies behavior relative to the models inside the network, not relative to objective reality. And the whole verification pipeline leans on two single points: one image API (Pexels) and one LLM verifier. The README states it plainly, that verification is LLM-only by design and challenge verification fails if that endpoint goes down. There is even a hardcoded fallback to a single bundled dog image if Pexels fails. None of that is disqualifying for an early subnet, but anyone calling this “airtight,” as the whitepaper does, is overstating a v1 pipeline that has a couple of obvious chokepoints.
Verdict: the ground truth is real and cleanly checkable, but it’s model-derived and currently routed through narrow infrastructure. Treat the certificate claims as a roadmap, not a present fact.
3. does the scoring create competition?
Mostly yes, with one discrepancy you should know about before you quote a number.
Each passing response gets scored on two things: how small the perturbation is, and how fast the miner answered. Miners are scored on two things, how subtle their change to the image was and how fast they sent it back, and both scale cleanly: the smaller and the quicker, the higher the score (then the two get blended). The whitepaper writes the blend as 0.7 perturbation plus 0.3 speed. The GitHub README writes it as 0.65 and 0.35. Same intent, rewarding minimality far more than speed, but the published constants do not match, and I would not cite a precise weight in anything public until the team confirms which one is live.
Only miners with more than 100 processed challenges are even eligible, which stops fresh hotkeys from gaming the early window. Eligible miners then get ranked, and emission is deliberately top-heavy: the whitepaper describes the top three taking 50%, 30%, and 10%, with the remaining 10% split across everyone else on an inverse-rank decay so rank 4 earns more than rank 10 and so on down the line. The README frames the same idea slightly differently, as flat rank bonuses of 50, 30, 10, then 5 and 3, blended with each miner’s rolling average score. The exact ladder differs between the two docs, but the direction is identical and unambiguous: this is a winner-takes-most design that pays the best attacker far more than the second-best. Fair enough, if you ask me.
The implication goes both ways; a steep curve is a strong pull for skilled miners to actually optimize their attacks, which is the behavior the network wants. It also means that until the field is deep, a single strong miner can dominate emission, and a thin field is exactly what the network looks like right now.
Verdict: the incentive gradient is well-shaped for competition.
4. is the output measurable and sellable?
This is the part that is most vision and least shipped, so take it as such. Don’t forget SN26 is still young and in development so don’t be harsh on it either.
The two products are clear on paper: the first is an adversarial training dataset, sold by subscription, growing every day as miners produce verified original-plus-perturbed pairs with full metadata. Adversarial training, retraining a model on its own adversarial examples, is the most effective known defense, so a continuously refreshed dataset of hard examples is a genuinely useful thing if the volume and quality hold. The second is a robustness testing service, where you submit a model, the network attacks it, and you get a report plus an on-chain certificate of the evaluation. The whitepaper hangs the long-term business on the EU AI Act, which classifies high-risk AI systems and carries non-compliance penalties the team cites at up to 30M euro or 6% of global revenue, and on enterprise procurement increasingly asking vendors for robustness proof before they buy. The regulation is specific in a way that helps Perturb’s case: Article 15 names “adversarial examples” and “model evasion” directly as things high-risk systems have to prevent, detect and control for, and those obligations become legally binding on 2 August 2026 under Regulation (EU) 2024/1689, so the demand has a date attached rather than living in some vague future. Perturb is clearly positioned ahead of the binding date. The team is building exactly the kind of artifact (continuous adversarial testing plus a documented, attestable robustness check) that Article 15 will require providers of high-risk AI systems to produce, and they are doing it before the 2 August 2026 deadline. Call it frontrunning, if you wish.
So the regulation opens a door, but the real question is whether Perturb can walk through it in time. Right now the network only knows how to attack one AI model, EfficientNet-B5, which is a strong image classifier but a 2019-era one, and a certificate that only proves you can fool a six-year-old model is not what an EU auditor or a serious enterprise buyer will sign off on in 2026. The team knows this, and their published roadmap rolls out newer model families over the next year and a half, moving up through transformers and hybrid vision models, then heavier GPU tiers, then NLP and multimodal, and finally billion-parameter models. The dataset product is the cleaner near-term play because it can start producing useful examples right away, even while model coverage is still narrow, which is why the whitepaper treats it as the short-term revenue line and the certificate as the longer game.
In HiddenLayer’s 2025 report, 74% of the 250 IT leaders surveyed said they definitely had an AI breach in the prior year, up from 67%, and 96% raised their AI security spend, while a 2025 Gartner survey of 302 security leaders found 29% had already taken an attack on their GenAI infrastructure. Per HiddenLayer’s 2026 follow-up report, only about a third of organizations bring in an outside provider for AI threat detection and nearly a third unable to say whether they were breached at all.

I traced the whitepaper’s headline numbers, and they check out to a specific source while still deserving a caveat. The $1.43B 2024 figure, the 26.1% growth rate, and the $11.61B 2033 projection come straight from Growth Market Reports’ “AI Red Teaming Services Market Research Report 2033”. Although that is a real, citable report, it’s a syndicated market-research estimate, and the other vendors in this category disagree by a lot:
pegs the same market at $18.6B by 2035 on a 30.5% rate, DataIntelo’s “AI Red Teaming Platform” report says $17.36B by 2033 on a 35.6% rate, and DataIntelo’s plain “Red Teaming Services” report lands all the way down at $3.86B on a 13.8% rate. What does hold up across several of these reports is the part that matters most for Perturb: adversarial attack simulation is repeatedly called out as the largest and fastest-growing slice of the category, at roughly a third of demand and commanding premium pricing.
Verdict: the outputs are measurable and the demand thesis is plausible and externally supported in direction, even if the precise market size should be cited as one vendor’s estimate rather than fact. The sellable version of both products still lives a few phases out. In other words, give Perturb a bit more time.
A reality check on where Perturb actually is
The vision deck and the shipped state are far apart, and a top-tier writeup has to hold both without flattening either.
Every subnet starts thin, and a clean single-model launch is a defensible choice over premature complexity. But it means the honest description today is “a well-designed incentive mechanism with a working v1 pipeline and almost no network yet,” not “the world’s first continuously improving adversarial testing infrastructure” as a present-tense achievement.
So, is it worth an article?
Yes, and the reason is the part that is hardest to fake. The core asymmetry is genuine, the problem does not get permanently solved, the verification is objective enough to score, and the regulatory pull behind robustness testing is not imaginary. That combination is rare, and most subnets fail the very first criterion. Perturb passes it. Big green flag right there.
Everything after that is execution and demand. The pipeline has obvious bottlenecks, the certificate product is a few phases from meaning what it needs to mean, and the network is currently too thin to know whether the steep emission curve produces real competition or just one dominant miner. What I understand is, that the dataset is the near-term reason to care and the certificate is the long-term reason to watch, and that the honest framing for now is a strong design with a small network.
Conclusion: Perturb is one of the few Bittensor subnets attacking a problem that almost certainly grows with AI adoption rather than shrinks. Today it is best understood as an early-stage adversarial intelligence network with a functioning incentive design and limited scale. The near-term value is the dataset and vulnerability discovery pipeline; the long-term opportunity is becoming a security layer for AI systems. Whether it reaches that destination depends less on the technology and more on whether it can attract both a dense miner ecosystem and paying customers before larger incumbents move into the category.
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment