

Chutes (SN64) just started serving GLM-5.2, the new flagship from Z.ai that is currently the strongest open-source coding model available.
The model scores 81.0 on Terminal-Bench 2.1, sitting within four points of Claude Opus 4.8’s 85.0 and clearing Gemini 3.1 Pro. It runs inside a Trusted Execution Environment on Chutes, meaning the GPU operators serving the model cannot read prompts or outputs at the hardware level.
Pricing is $1.40 per million tokens in and $4.40 per million tokens out, putting genuine frontier-adjacent coding performance on decentralized infrastructure at a fraction of typical closed-model rates.
Performance, Privacy, Price
The release is notable on three separate axes, each of which would be meaningful on its own.
a. On performance:
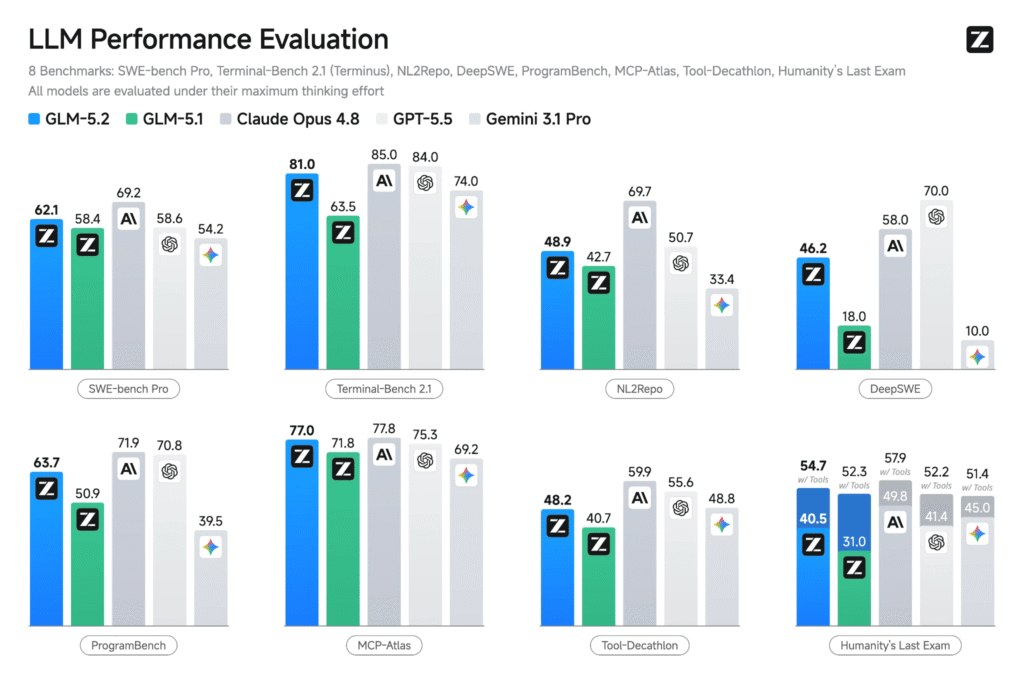
1. Terminal-Bench 2.1: 81.0 – Within four points of Claude Opus 4.8 (85.0) and ahead of Gemini 3.1 Pro.
2. SWE-bench Pro: 62.1 – A jump from GLM-5.1’s 58.4, putting it among the strongest open-source results on the benchmark.
3. Native 1M-Token Context – The model handles long-horizon coding and agentic workloads without requiring external chunking.
4. IndexShare Attention Design – A new attention mechanism that cuts per-token compute by approximately 2.9x at full context, which makes the long context usable at production cost.
b. On privacy:
1. TEE Chute Deployment – The model runs inside a Trusted Execution Environment, which means GPU operators on the Chutes network cannot read prompts, outputs, or any data flowing through the model. Confidentiality is enforced at the hardware level rather than by policy.
c. On price:
1. $1.40 input / $4.40 Output Per Million Tokens – Aggressive enough to make sustained agentic and long-context coding workloads economically viable for developers running them at scale.
The combination is what makes the release land. Open-source models have caught up on raw capability for narrow tasks, but most of them ship without privacy guarantees and at price points that erode the economic case. GLM-5.2 on Chutes delivers all three in one package.
Open Models, Real Privacy
The takeaway from this release is what it says about where the open-source side of the AI stack is heading. A model that scores within four points of Claude Opus 4.8 on Terminal-Bench is no longer a research curiosity. Add 1M context with a new attention design and confidential compute at the hardware level, and it becomes a production tool.
Chutes serving the model on decentralized infrastructure with TEE guarantees closes the last gap that has historically pushed serious workloads back to closed providers: confidentiality. The model is available now at the listed pricing. The benchmarks are public. The privacy is at the GPU level rather than the policy level.
➛ Explore GLM-5.2 on Chutes (SN64) Here
Enjoyed this article? Join our newsletter
Get the latest TAO & Bittensor news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment