

Templar, Bittensor’s Subnet 3, has been making waves as one of the network’s flagship projects for decentralized AI training. In late March 2026, it completed the Covenant-72B training run—the largest model ever trained on trustless, permissionless peers across the open internet.
Using commodity hardware and ordinary internet connections (no centralized data-center cluster), the subnet trained a 72-billion-parameter model on over 1.1 trillion tokens with more than 70 contributors. It achieved 94.5% compute utilization and outperformed LLaMA-2-70B on key benchmarks like MMLU. The project even earned praise from NVIDIA CEO Jensen Huang on The All-In Podcast, who compared the effort to modern-day Folding@Home.
Now, with the 72B run wrapped, Templar isn’t sitting idle. It has shifted into a new phase called Crusades, and that’s exactly why miner emissions are currently being burned at 95–100%.
What Are “Crusades”?
Crusades is not the old decentralized training protocol. It is a live MFU (Model FLOPs Utilization) optimization competition. Miners no longer train the full model from scratch. Instead, they submit a single train.py file containing an inner_steps() function. Validators then run that exact code on standardized hardware (typically 4× A100 GPUs) and measure the MFU score—the percentage of theoretical peak FLOPs actually used for useful training work. The highest MFU wins.
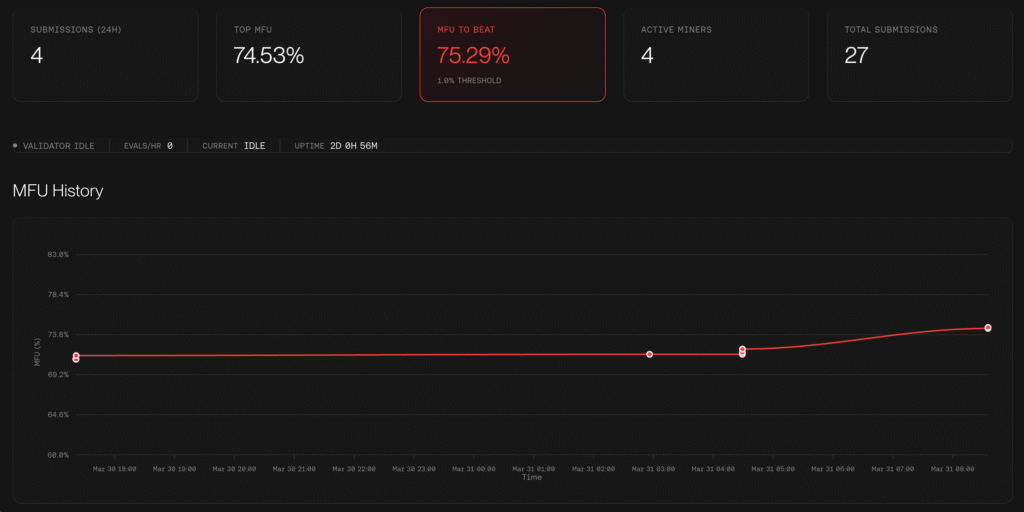
This is an engineering contest to squeeze every last drop of efficiency out of the training stack before the next big model run begins. The official Templar account has been posting regular leaderboard updates, and the competition even has its own dashboard.
Why the 95–100% Burn Rate?
During the active 72B training run, Templar ran at a 50% burn. Once the model finished, the subnet moved into Crusades and cranked the miner burn to 95% (100% if any exploit or gaming is detected). Here’s the intentional design behind it, straight from the subnet’s leadership:
- Only the threshold-adjusted rank #1 miner receives the remaining ~5% of emissions.
- Everyone else gets zero.
- This is explicitly “winner-takes-all.”
The goal is simple: concentrate rewards on genuine optimization work. Between major training runs there is no full-model work to be done, so there is no reason to pay every miner for “showing up.” High burn prevents emissions from leaking out as sell pressure while the team prepares the next run. As one community member put it: “Templar miners shouldn’t earn emissions between runs when there’s zero work to be done.”
It’s noteworthy that the top miner in the current competition has been earning roughly $5,000 per day.
The Bigger Picture
Crusades is the bridge between one record-breaking model and the next. By throttling emissions during the inter-run “preparation” phase and running a pure merit-based MFU tournament, the subnet avoids paying for idle compute and instead rewards the engineers who make the next run cheaper, faster, and more scalable.
The Covenant-72B model is now in post-training, and the subnet is already gearing up for whatever comes next. When that run starts, emissions will flow again to the miners who keep pushing the efficiency frontier.
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment