

By: School of Crypto
Late 2022 changed A.I. as we know it. A new app called ChatGPT came out and it took the world by storm. The user could ask any question to this A.I. chatbot and it would give them a well-versed answer in a matter of seconds- just like magic. It only took 2 months for ChatGPT to reach 100 million users. Fast forward 3 years, and OpenAI has reportedly been valued at around $500 billion.
However, when you look under the hood, there are systemic problems with OpenAI and the generative AI space. The operational, infrastructure, and pure compute costs led to $5 billion loss in 2024, with an expected $14 billion hit in 2026.
Other than the vast amount of money and resources OpenAI and Anthropic burn, the actual large language model (LLM) architecture they use is being called into question. These chatbots are phenomenal at computational tasks such as coding, analyzing data, and even writing. However, when it comes to exhibiting human-level reasoning and problem-solving, their capabilities fall very short.
It seems as if the crowd and consensus believe that LLMs are going to take us to AGI and superintelligence. However, Hone Training, subnet #5, has a different perspective. Hone is a subnet in the Bittensor ecosystem that strives to achieve full-scale AGI utilizing new, fresh hierarchical learning models that can transcend LLMs’ capabilities and one day mimic the human brain. Hone plans to achieve this level of AGI by solving the ARC-AGI-2, a benchmark testing A.I.’s fluid intelligence.
“There’s no ground truth in LLM’s because they don’t have a prediction of what will happen next” -Richard Sutton
Recently, A.I. influencer Dwarkesh Patel interviewed the Reinforcement Learning master Richard Sutton about the A.I. landscape, specifically speaking about the modern-day LLM. Patel looked stunned when Sutton suggested that LLM’s lack of goals, unknown training data, and inability to give a multitude of options for a problem would be a deterrent for its future.
In the Hone Training Research section of their website, they specifically detail the fatal flaws of LLMs and why they fail on many levels. LLMs are built on what’s called an autoregressive decoding mechanism, which predicts the next token in a sequence. This model suffers from a lack of long-term planning and true multi-step deep reasoning. LLMs use the same computation for easy and hard problems instead of thinking longer or harder for more difficult queries.
As seen above, LLMs need gigantic data sets, struggle with factual consistency, aka hallucinations, and basic common sense understanding. Sutton stated, “If there’s only one way to solve a problem, they will solve it. That’s not a generalization. Generalization is finding multiple ways and picking the ideal one. There’s nothing in an LLM to cause it to generalize well. Creating dissent will cause them to find a solution to problems they’ve seen”. This is the conclusion that Yann LeCun came to as well, identifying that “predicting raw high-dimensional outputs is extremely difficult because there are many possibilities at each step, meaning the model is always predicting wrong except for one correct path”.
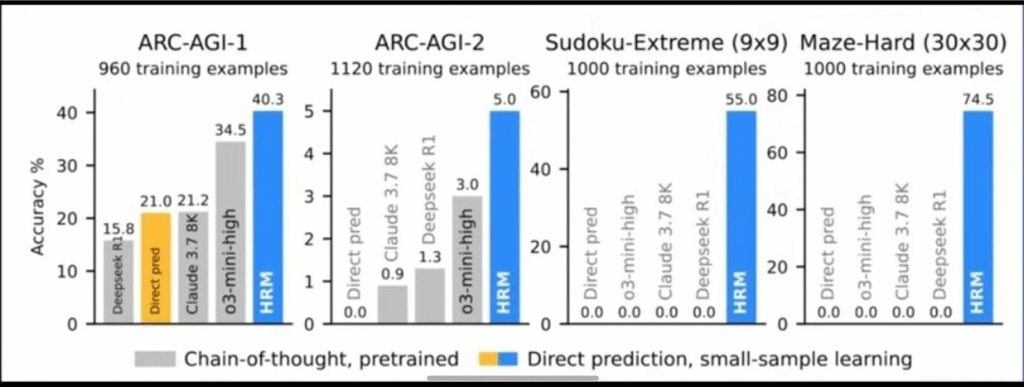
The folks at Hone Training think LLMs’ infrastructure is flawed, and there has to be another way to achieve AGI. There have been a couple of interesting revelations in the A.I. space that have a chance to further A.I.’s reasoning capacity to another level. The two models that Hone has been inspired by is Joint Embedding Predictive Architecture (JEPA) and Hierarchical Reasoning Model (HRM). These two models are inspirations for Hone Training’s miners to utilize in order to achieve a higher score on the ARC-AGI-2 benchmark, something state-of-the-art models fail to reach a 20% score on.
JEPA
LeCun’s JEPA model combats the autoregressive decoder’s flaw of lack of planning and reasoning with a novel dynamic. It involves two encoder networks that turn inputs and targets into short summaries. This inherently discards irrelevant information and learns predictable extractions. Focusing on the right information and not having to sift through erroneous data allows for a more seamless reasoning path and saves time and money on additional compute.
JEPA utilizes a self-supervised learning mechanism called VIGReg that enables a world model that understands how things work, like cause and effect. There’s a hierarchical form of JEPA called H-JEPA, which stacks JEPAs and breaks down tasks into two levels: a short-term one that predicts quick, detailed information and a long-term one that predicts the bigger picture and more abstract and complex scenarios.
JEPA aims to move beyond the one-step guessing approach of an LLM and focuses on building internal world models for adaptability, planning with uncertainty, and the ability to integrate with autonomous agents.
HRM
The HRM is essentially modeled after the way the human brain works. The framework consists of a multi-timescale organization of two interdependent recurrent modules. One is a slow updating, very high-level one for abstract planning. The other module is more of a fast iterating low-level module for detailed computations. Both work in tandem and create a nested loop where the low-level module refines sub-problems under the periodic guidance of the high-level module to achieve global coherence.
HRM demonstrates latent reasoning, or in other words, performs complex planning in its continuous hidden states before generating a final output. This greatly contrasts with LLM’s Chain of Thought (COT) step-by-step verbal reasoning that requires massive data, huge models, and is more prone to error.
Lastly, one of the benefits of using HRM is the small number of parameters it uses (~27M). The model was only given 1,000 examples and scored near-perfect scores on Sudoku puzzles and complex mazes. HRM outperformed SOTA GPT models by a large margin in these tasks.
Hone Workflow
Based on the goal of trying to get the highest score on the ARC-AGI-2 leaderboard, Hone has a certain process in getting to the top.
The validators on the subnet utilize the ARC-GEN GitHub to generate synthetic data in order to challenge the leaderboard.
Hone then takes these ARC-AGI tasks and applies multiple transformations on them to add additional complexity and create harder problems.
The miners are tasked to use models like JEPA/HRM and even LLMs to solve these problems generated by the validators. The most accurate models that solve the most problems get the rewards.
Status of Hone
The subnet is currently not live as of yet, but will be in a very short period of time. The economics of the project have not yet been disclosed and are to be determined.
Last but not least, this subnet is run by two of the biggest Bittensor supporters in Latent Holdings and Manifold Labs. Hone ranks #9 in overall emissions without even getting started yet.
Highest potential in all of Bittensor?
You can absolutely make the argument that Hone is one of the highest potential subnets in the entire ecosystem. They are striving to achieve full-scale AGI. As discussed earlier in this article, the current LLM architecture has a lot of flaws in its reasoning and planning capabilities.
If Hone achieves AGI and comes up with an architecture that resembles the human brain, this would be one of the biggest developments in all of humanity.
Are you honing in on this possibility?

Be the first to comment