

I think the major frustration with “crypto” (or at least, my core frustration) is that founders and VCs have a massive incentive to dream up imaginary problems to solve with this new shiny tech. If blockchain is a hammer, there’s always gonna be a Patagonia-clad 28-year-old trying to convince you that your chronic migraines could actually use a hammering.
That’s why I’ve been so jaded about “exciting ideas” that spark a two-week hype cycle on crypto Twitter. The energy grid works fine without a blockchain. No one is gonna go to your sketchy site to trade corn futures when they can just make a Fidelity account. These aren’t real problems that need solving by our lord and savior, the blockchain.
Bitcoin worked because it satisfied two criteria:
- Requirement 1: The problem (centralized finance) is real and existential
- Requirement 2: Blockchain is actually the best solution to that problem
It wasn’t happenstance. That perfect storm is why we ended up with a trillion-dollar asset in the first place.
And I think we’re facing another perfect storm – this time with AI.
To understand just how dangerous centralized AI can become, picture this: You’re surrounded by personalized apps, smart speakers, and ambient devices that seem to know you better than your spouse. But behind the curtain, your data – your choices, your patterns, your identity – is being siphoned off and monetized by a handful of private entities.
These private companies will have a deeper psychological understanding of you than you do and will be able to manipulate you at the most primitive level. That’s not science fiction. That’s the default trajectory.
I’d call that existential. (Requirement 1)
So here’s what I’m trying to do in this report:
- Convince you that blockchain actually solves real problems in AI development (Requirement 2)
- Showcase the teams proving it, right now, in code
What we already know
The largest collection of coordinated computing power isn’t some supercomputer funded by a tech conglomerate nor government, it’s Bitcoin.
Bitcoin’s collective power of around 800 EH/s is hundreds of times more powerful than the world’s largest supercomputers. We already have a solution to organize the world’s compute – it’s called blockchain incentive mechanisms.
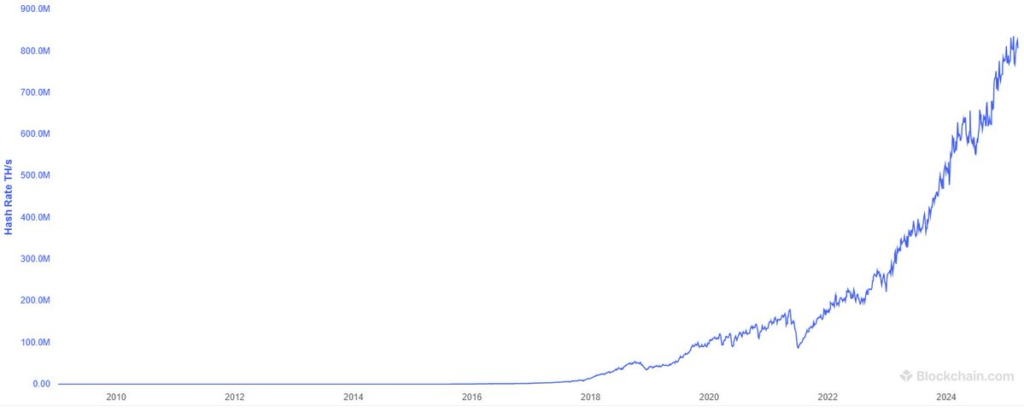
It’s a resource allocation problem – the resources exist, and blockchain makes them all march toward a common goal.
But building AI goes beyond the simple process of banging out hashes, it requires finesse along with raw compute. Projects building models need not only to scale compute, but talent as well.
Speaking of projects, let’s introduce the starring cast.
And while reviewing these chads, don’t forget their common goal – to produce world-class AI models that dethrone the hyperscalers.
The players
We’ll go through their architectures and how they compare later on. But briefly, here are the projects building in this space and why you should pay attention to them.
Nous Research

Besides demonstrating the absolute pinnacle of branding (shoutout John Galt), @NousResearch is an AI-accelerator company fighting for an open-source escape hatch. They’ve been able to build and deliver countless tools thanks to the sheer depth of their intellectual talent pool:
- Hermes series of language models (now including DeepHermes)
- WorldSim – a terminal interface for simulated worlds
- Agents – God, S8n, TEE
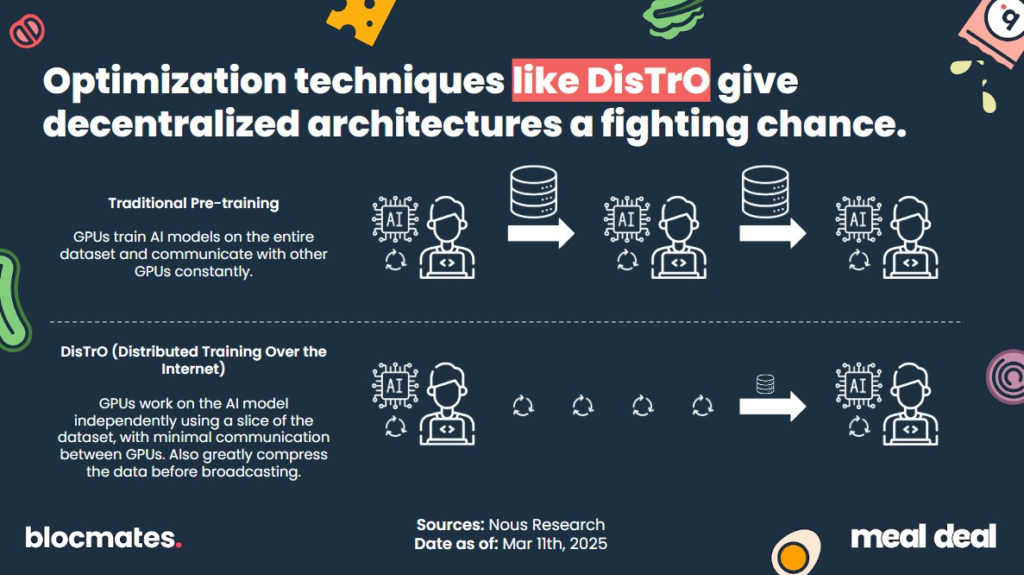
They’ve accomplished all of this while tip-toeing around “crypto,” until now. Their new project on Solana, dubbed Psyche, will leverage their family of optimization schema DisTrO to allow for the training of models in a distributed manner. And if any team is gonna try the impossible, I wouldn’t bet against Nous.
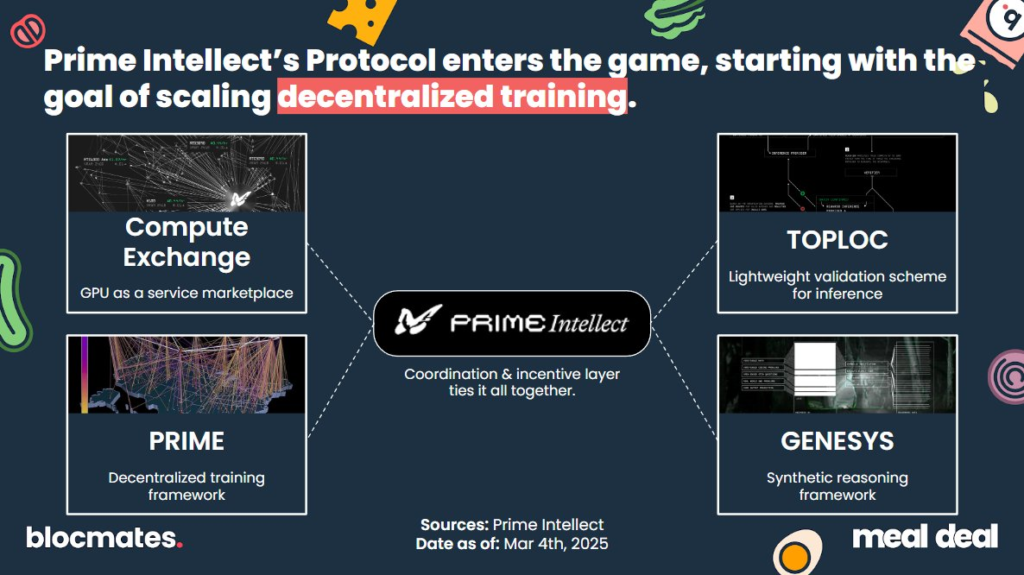
Prime Intellect

If it’s been a while since you last checked in on Prime Intellect, you probably just know them as a GPU as a service network like Akash–but the boys have since been cooking.
On top of their GPU DePIN (Prime Intellect Compute) and training their own 10b-parameter model (INTELLECT-1), they’ve released key research surrounding:
- Bandwidth-restrictive training (OpenDiLoCo)
- Training of a bio-foundational model (METAGENE-1) and RL training of a math model (INTELLECT-MATH)
- Distributed RL to generate the largest synthetic reasoning dataset (GENESYS + SYNTHETIC-1)
- Inference verification (TOPLOC)
All of this leading up to their huge announcement of a $15m round from Founders Fund (amongst others) with the goal of building their own decentralized training protocol. Serious stuff.
Pluralis Research

Not to be outdone, a couple weeks after Prime, @PluralisHQ announced their $7.6m raise, led by Union Square Ventures and CoinFund. They, too, plan on building a network for training and hosting AI models (dubbed Protocol Learning).
Their goal is slightly different in philosophy – preaching that the builders of the models ought to maintain sharded ownership over models that they help to produce.
Gensyn

Much like others in this list, @gensynai maintains a deep bench of AI talent narrowly focused on bringing open source model development to the masses.
Gensyn initially made waves with their massive $43M Series A led by a16z back in 2023 (with additional support from Canonical, Protocol Labs, and Eden Block) and has since been hoovering up AI/ML talent.
Their vision of the future sees databases, website backends, and personal devices all distilling their content down into models of their own. In this future, new communication methods will be necessary to efficiently pass information back and forth from these models, which Gensyn intends to develop.
To showcase this idea, they’ve just launched their RL Swarm testnet, where they will slowly trickle in their developments such as SkipPipe (their pipeline parallelism approach), Verde (a verification scheme), and HDEE (taking Mixture of Experts to the extreme).
Bittensor

Did you really think I’d write a report about decentralized AI and leave out Bittensor?
For the uninitiated, Bittensor is a permissionless network where startups can launch a competition, incentivizing participants to compete against each other, all striving to achieve the best score in a certain metric.
The reason why you often see the “Bittensor is too complicated” argument is that these “competitions” (they call them subnets) can be basically anything. Whether it’s DeepFake detection, trading signal generation, or scientific research – if you define a problem well enough, Bittensor can help you solve it.
There have been a few “decentralized training” efforts over the months/years, but today we’re going to be focusing on Templar (subnet 3). Their approach is notably different from other training architectures on Bittensor (which have seen success, in their own right), coordinating countless nodes to collaboratively contribute to a single model – in a completely permissionless (and adversarial) environment.
Oh, and it’s already live.
EXO Labs

One more wildcard in the mix for those keeping score at home. @exolabs is cut from the same cloth as the rest of these teams – constantly shipping insightful research while still managing to fly under the radar.
While they are generally focused on edge computing and clustering to run large models locally, they’ve dipped their toes in distributed/decentralized training research.
Their “12 Days of EXO” series last holiday season had some bangers, notably:
- SPARTA – a data parallelism approach also stemming from DiLoCo
- ML verification from edge devices
- EXO Gym – a decentralized training simulator for algorithmic experimentation
Ambient

Fresh off the presses, Ambient announced their $7.2m raise from a16z, Delphi, and Amber on March 31, 2025 to build a massive (600b+ parameter) model continuously trained and hosted on their bespoke PoW Solana fork.
Key features of their tech stack include:
- Their novel consensus mechanism, Proof of Logits, allows validators to confirm that node participants are acting honestly. This builds off previous innovations in decentralized inference and training (PETALS / D-SLIDE).
- An ever-improving foundational model that is completely hosted and inferenced from the blockchain, without the need for any off-chain storage/services, through their sharded design
Why distributed training is becoming interesting now
Now that you know the players, you’re probably wondering:
- How do they overlap?
- Why are there so many acronyms?
- Their branding is sick, where can I get some merch? (I got you – Nous, Prime, Bittensor)
On top of it all – why now?
After all, at first glance, it’s somewhat strange that all of these networks (that all kinda have the same goal) sprung up around the same time.
Why now, though? Because until recently, the tools to make decentralized training scalable and efficient simply didn’t exist.

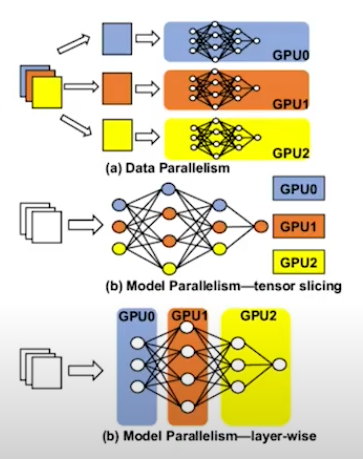
A big one is parallelism, a fundamental technique for efficiently distributing workloads across GPUs. This is the key to enabling decentralized training at scale.
Data parallelism is the simplest form of parallelism, where each GPU holds a full copy of the model and trains on different data subsets. This works well until models get too large for a single GPU to handle.
- Examples: OpenDiLoCo from Prime Intellect, SPARTA from EXO Labs, DisTrO from Nous (Templar also runs DisTrO)
Model parallelism (sometimes called “tensor parallelism”) is where the model is split across GPUs so that each GPU handles only part of the overall model. Pipeline parallelism is a specific case where these parts are arranged in stages that pass data from one GPU to the next.
- Examples: FSDP used by Prime Intellect, SkipPipe from Gensyn, D-SLIDE and PETALS used by Ambient
Solving bandwidth constraints with parallelism
Imagine you’re training a model on 1,000,000 different recipes to create your ChefGPT bot. You could sit there and wait for your GPU to chug through all 1,000,000 recipe examples, or…
You could enlist your 9 other friends to help train the model and send them each 100,000 recipes to train on – cutting the training time by a factor of 10. Congrats, you just discovered data parallelism.
Data parallelism
As we mentioned, data parallelism is the simplest and most common form of parallelism for AI training, where every node gets a full copy of the model and trains on a different subset of the data. The only drawback is that, eventually, you’re gonna have to share notes with your friends – and this is where bottlenecks can happen.
Sharing all of the data of your model with your friends requires a lot of bandwidth (as an example, Llama 3.1 70b is around 140GB), so you want to do this sparingly. But if you don’t do it often enough, each friend’s model will diverge from one another, giving you 10 crummy models in the end, instead of 1 chad model.

This is basically what DiLoCo (Distributed Low-Communication, dropped in November 2023 from Google DeepMind) optimizes for. The goal is to leverage the power of your combined, yet distributed, hardware to crank through training, but still staying in sync enough so that your models don’t completely diverge from one another.
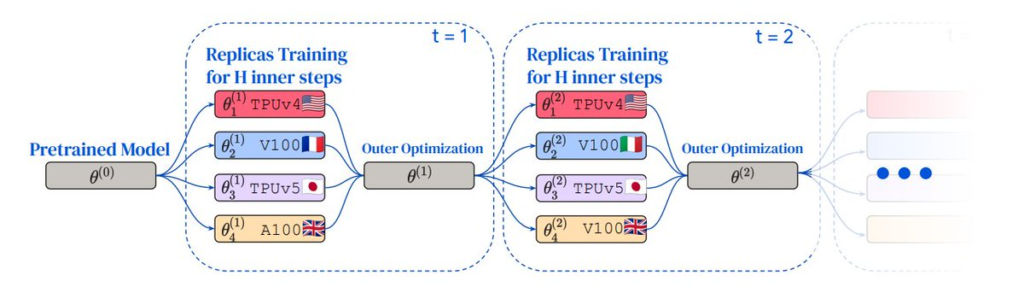
Prime Intellect took this one step further with OpenDiLoCo, in July of 2024, taking DeepMind’s vision, open-sourcing it, and scaling it to the next level.

They were able to train a 150m parameter model using this method (3x the size from the original paper), utilizing compute from 3 countries on their small testnet.
Pretty slick – but there’s still some efficiency to be eeked out. After all, every time you’re synchronizing, you have to send a huge amount of data to your fellow peers. The lads at EXO and Nous both agreed that this could be improved.
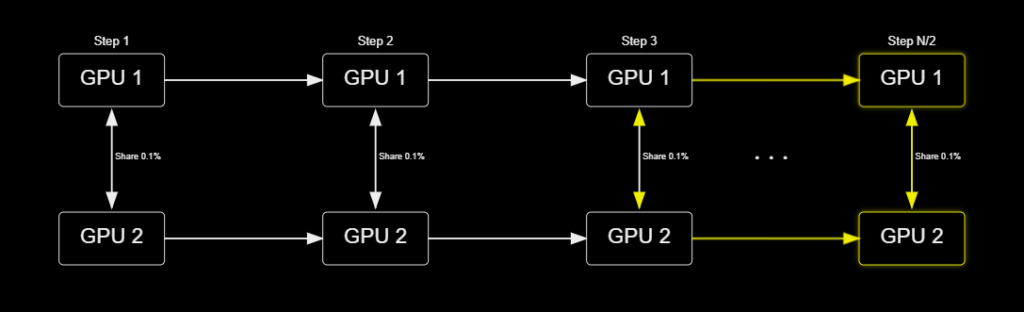
EXO Labs’ solution was dubbed the SPARTA optimizer (Sparse Parameter Averaging for Reduced-Communication Training) and just asks, “I know we have to share some data with each other, but exactly how much do we have to share each time?”
If we share 0.1% of the model each time we synchronize, for example, is that enough?
EXO showed that this technique, when combined with the DiLoCo framework, still provided converging models, despite the massive decrease in bandwidth.
Going back to our ChefGPT example, this is like texting your friend group chat to make sure they all remember that salt exists and no one is cooking up meth instead. At least you’re heading in the same direction.
Nous actually has been tinkering with this problem as well, dropping a paper with OpenAI founding team member Diederik Kingma (who also introduced the legendary Adam optimizer) called DeMo (Decoupled Momentum Optimization).
Their distributed training solution DisTrO (Distributed Training Over-the-Internet) is a family of optimizers that includes DeMo and builds off of it. These optimizers massively compress the amount of data shared between nodes for each step of synchronization, a bandwidth savings on the order of 1,000x.

Nous proved that this method could be used with distributed and heterogeneous hardware – by actually doing it.
They trained a 15b parameter model in December of 2024 using this tech, showcasing its capabilities on a closed testnet with some big-name partners.
Psyche, the much-anticipated protocol soon-to-launch on Solana by the Nous team, will leverage DisTrO to scale their training efforts to the next level. To read a full breakdown on Psyche, check out my previous report.
But if you want to see this tech in action today, look no further than Templar over on Bittensor subnet 3. These fellas have been testing/hacking in production, leveraging techniques like DisTrO to build new models in a completely permissionless environment.
However, for extremely large models that can’t fit on a single GPU, data parallelism alone won’t work; that’s where model parallelism comes in.
Model and Pipeline Parallelism
Data parallelism is like having everyone read the same cookbook but divvy up the pages. Model parallelism, by contrast, is more like turning your friends into a human centipede of chefs – one chops, one sautés, one plates – and the data flows through them like a very hot potato.
Breaking it down:
- Model (or tensor) parallelism splits the model itself across devices. Each node holds a chunk of the model weights and is responsible for its piece of the forward and backward pass.
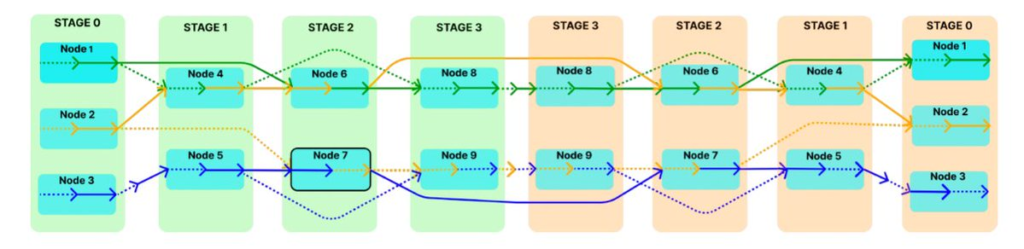
- Pipeline parallelism takes this further, organizing the model into sequential stages. Think assembly line – the output of one stage becomes the input for the next.
This kind of slicing gets tricky. You need all the GPUs to be relatively in sync, passing tensors back and forth without dropping packets or frames. That’s a tough ask in adversarial or flaky environments (read: the open internet), which is why execution here is a standout.
Gensyn tackles this head-on with their SkipPipe approach – a custom pipeline parallelism method that reduces memory overhead and latency during training. SkipPipe minimizes the idle time between stages, and is designed to work even in lossy, high-latency networks (like the ones you’ll find outside the cozy confines of hyperscalers). It forms a core piece of their scaling thesis, so hopefully we get to see it in action following their RL Swarm demo.
Prime Intellect and Ambient lean into similar approaches (FSDP and D-SLIDE/PETALS, respectively) which enable nodes to independently train their assigned subsets of the overall model while remaining resilient to faults, such as GPUs leaving the network. In particular, D-SLIDE leverages sparsity, meaning that during both training and inference, only a small subset of nodes is activated at any given time. This sparse, sharded architecture significantly reduces inter-node communication and eliminates unnecessary redundant computations.
Meanwhile, FSDP shards the model’s weights/gradients and optimizer states between nodes so that they don’t have to fit the entire model on a single GPU.
These parallelism techniques are excellent for traditional pretraining, but when we want to start our posttraining efforts of adding reasoning or domain expertise on top, we have to start fine-tuning.
And that, as we’ll see in the next section, is where things start to get spicy.
The DeepSeek Moment – the power of RL
Until recently, most AI training followed the same well-trodden path:
- dump a bunch of text into a giant blender (your model),
- swirl it around with supervised learning,
- and hope you end up with something smart enough to autocomplete your emails without also inventing war crimes.
This approach – called pretraining – is compute-hungry, tightly coupled, and not particularly fault tolerant. LLMs then typically undergo a series of supervised fine-tuning (SFT) and then some reinforcement learning with human feedback (RLHF) during a process known as “post-training.” Each of these methods would handhold the model to yield better and better results, but are very costly (in terms of compute and time).
Then along came DeepSeek.
In January 2025, DeepSeek released an open-source language model that combined pretraining with extensive reinforcement learning (RL) to produce a performant reasoning model that rivaled the best that OpenAI had to offer. This simplified the post-training process immensely.
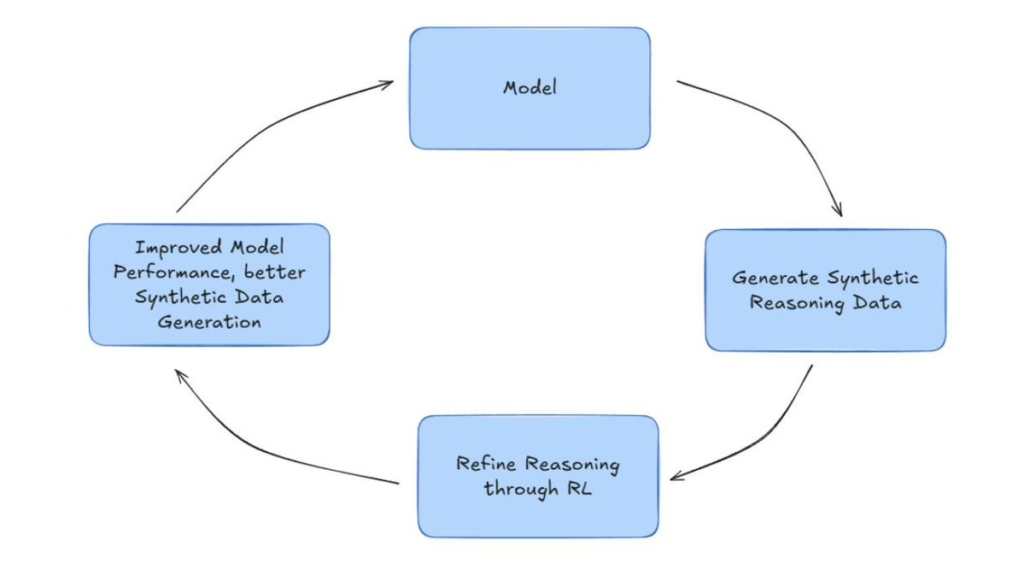
While RL has been used at the tail-end of training (think RLHF), this was one of the first real attempts to use it as the main course instead of just the seasoning. The results? Surprisingly good.

What matters more than the model quality, though, is what it implies for the future of distributed training.
RL is inherently tolerant of chaos. Nodes can drop out. Latency can spike. Participants can work asynchronously or even adversarially. In a centralized data center, those would be bugs – but in decentralized networks, they’re just Tuesday.
With RL, you can frame training as a multi-agent optimization game where each participant tries to maximize a reward function. That’s music to the ears of any protocol designer working with flaky nodes over flaky networks.
It’s no surprise, then, that several projects are leaning into this trend:
- Gensyn is exploring reinforcement learning directly via its RL Swarm, in which nodes not only self-learn, but also learn from all other nodes in the swarm. Much like DeepSeek, they are taking a GRPO approach – a flavor of RL that instead of guiding you towards a solution, gives the model free reign to discover the answer in any way they wish. You just need to ask it questions with verifiable solutions.
- Prime Intellect, not to be outdone, is leveraging its massive SYNTHETIC-1 reasoning database to conduct reinforcement learning on their protocol testnet to generate their INTELLECT-2 model.
Outside of RL, DeepSeek-R1 (and o1 before it) showed that by simply allowing the model to “think” longer yielded better results: this is known as test-time compute.
If you zoom out, this starts to look like a shift in how we think about the AI value chain. Training might still be expensive, but inference is where value is realized – and where new incentive systems can shine. In decentralized settings, that’s exactly what you want: something that spreads the work out, tolerates messiness, and still rewards useful behavior.
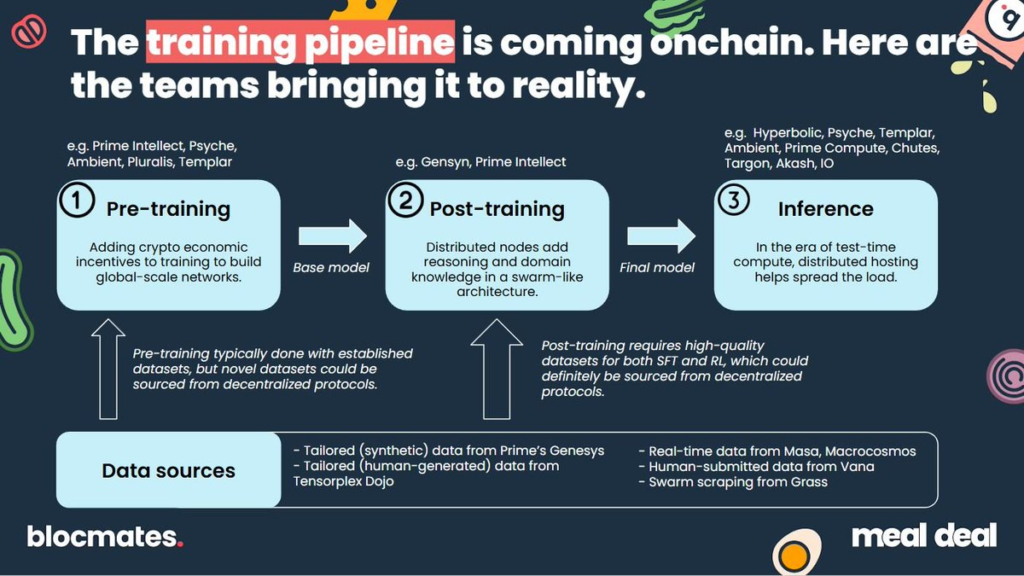
We’ll probably look back and realize DeepSeek wasn’t just a one-off curiosity. It was the moment a bunch of people realized that RL isn’t just for agents playing board games – it might be the perfect tool for building AI in the wild.
Who to incentivize – the outcome or the process?
If you’re going to build AI on a blockchain, the most important question isn’t which chain you use or what fancy parallelism trick you implement. It’s this:
Who do you pay?
And more importantly – what do you pay them for?
Incentives are the heartbeat of decentralized systems. Design them poorly, and you’ll either bleed money or reward useless behavior. Design them well, and you can orchestrate massive global coordination from a standing start.
Each project in this space is taking a slightly different swing at the incentive problem – choosing whether to reward raw compute, quality outputs, validator work, or even model ownership itself.

Important note: Aside from Templar, most of these projects are still in development. Hell, even Templar is proudly building in production. That means reward mechanisms could (and likely will) evolve as they test assumptions and learn what actually works in practice.
Let’s break it down.
Pay-for-compute models
Psyche (Nous), Gensyn, and Prime Intellect stick with the classic “task fee” model. Contributors rent out their GPUs, perform compute jobs (e.g. gradient updates, training steps), and get paid in tokens. It’s straightforward and familiar. The teams also want to introduce staking and slashing – validators are required to stake tokens and can be penalized for bad behavior, helping keep results honest.
Pluralis takes a different approach. Rather than paying contributors for individual tasks, they propose a system where contributors earn sharded ownership of the final model. If you help build the model, you get a cut of future monetization – think equity instead of hourly wages.
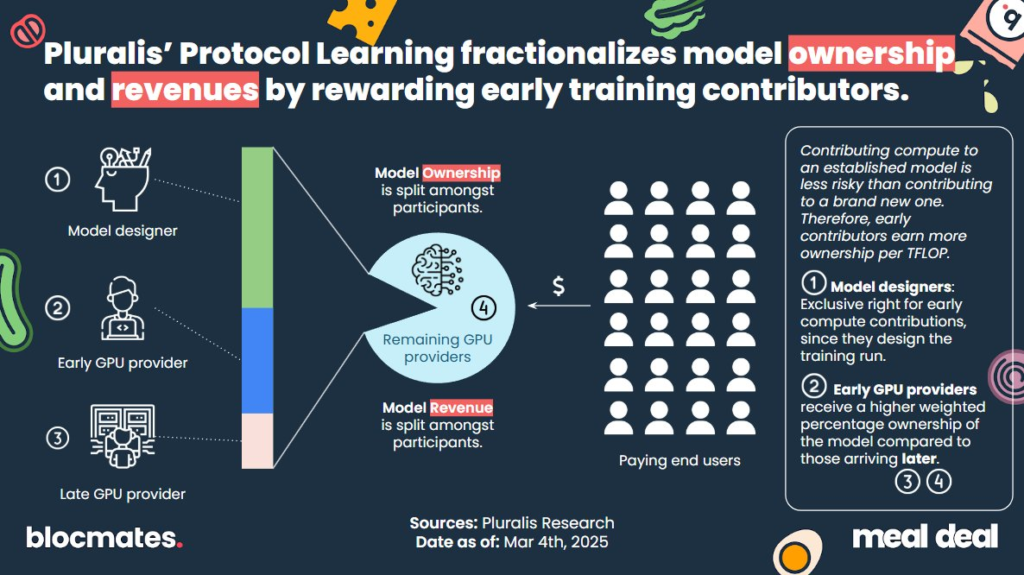
It’s a philosophically appealing idea – aligning incentives around long-term value instead of short-term tasks. But it makes two big assumptions:
- That contributors can recognize which models are worth backing, and
- That the market will actually pay to use those models once they’re built.
Neither is a given. Most GPU contributors are just looking for stable, predictable payouts – they’re not model scouts or product managers. Expecting them to intuit the commercial potential of a random fine-tune is optimistic at best. And in a world saturated with open-source models and minimal barriers to entry, monetization is far from guaranteed.
In that light, Pluralis’ system may end up attracting more ideologically aligned contributors – those who care about specific use cases and want skin in the game – rather than mercenary compute providers. That’s not necessarily a bad thing. But it’s not a plug-and-play model for mass coordination either.
Still, if the right tools are built to surface promising projects, and contributors are given enough context to make informed bets, the upside could be powerful: true aligned ownership, and contributors who actually care about the models they help create.
Custom incentive games
Then there’s Bittensor, which turns the whole thing into a game.
Each subnet on Bittensor can define its own reward logic. So on Templar (Subnet 3), the subnet owner sets the rules: how compute is measured, how performance is scored, and how rewards are distributed. The miners (those doing training) get paid on a sliding scale based on their contributions – and penalized for bad behavior like dropping out or producing junk gradients.
Templar’s current design:
- Rewards nodes that contribute useful gradients
- Deducts rewards for latency spikes, crashes, or divergence
- Continuously updates scoring rubrics to improve convergence
The kicker? The subnet owner is also rewarded by the broader Bittensor network if their subnet produces valuable outputs. So there’s a recursive incentive to fine-tune the incentives themselves – a game within a game.
Then there’s Ambient, which reimagines mining entirely, ditching old-school number-crunching for something with tangible value: generating and fine-tuning large-language-model outputs.
Ambient’s network security is embedded directly in each inference step. Every token generated is a cryptographic stamp of authenticity, a “Proof of Logits” that both secures the blockchain and creates valuable text outputs as a byproduct.

- Makes model inference the “work” itself, rewarding miners for generating real AI responses instead of empty computations
- Keeps nodes honest through verifiable logits, creating a tamper-proof AI production line where each inference is transparently validated.
- Runs adaptive sharding and dynamic load balancing, swiftly reshuffling tasks if miners slow down or drop out, ensuring performance never skips a beat
Miners aren’t just incentivized to compute, they’re incentivized to compute correctly, efficiently, and reliably, since their rewards directly depend on the quality of their AI outputs. So miners turn into competitive “LLM farms,” tweaking and optimizing their hardware specifically to host and fine-tune the Ambient model.
It’s a feedback loop: the more useful the AI becomes, the more secure the chain is, which further incentivizes miners to crank out even better inference.
Bittensor and Ambient push beyond traditional “pay-for-compute” models, experimenting with incentive systems that treat training and inference not just as tasks, but as dynamic, game-like ecosystems.
Bittensor creates modular incentive playgrounds through subnets – each one a live experiment in how to reward useful contributions and penalize noise. Ambient goes further and deeper towards a singular goal, embedding its incentive structure directly into the act of inference itself, where every token generated is both a useful output and a cryptographic proof of honest computation.
Together, they hint at a deeper shift: from renting out raw compute to architecting economies where AI progress and economic security are one and the same.
Who should you incentivize?
It’s easy to assume that more GPUs equals more progress. But in a permissionless environment, not all contributors are created equal – and not everyone should be rewarded the same way.
Let’s ask the uncomfortable question: do raw GPU contributors even know how to train good models?
In centralized labs, performance gains often come from obscure tricks: weird optimizers, gradient skipping strategies, layer freezing schedules, or subtle tweaks to the loss function. That knowledge is guarded – and it’s what makes the difference between a decent model and a state-of-the-art one.
If you blindly pay people to run jobs, you’re not incentivizing innovation – you’re just rewarding availability. That gets you compute farms, not breakthroughs.
But go too far in the other direction – only paying for final outputs – and you introduce new problems. Most contributors don’t have the context, insight, or authority to guide model development. They’re workers, not architects.
So maybe the answer isn’t “pay-for-compute” or “pay-for-output.” Maybe it’s both.
You need a division of labor:
- Dumb compute: large pools of contributors who perform the heavy lifting and are rewarded based on execution (e.g. task fees)
- Smart oversight: protocol designers, subnet owners, and contributors with actual ML expertise who set the objective, design the scoring, and guide convergence
In other words, you need a strong army (of compute) and a skilled enough general to focus the scattered legion.
While Pluralis gives credit to the compute providers and assumes they have some skill in backing winners, this does carry risk that you’re asking too much from data systems engineers.
The teams at Nous, Prime Intellect, and Gensyn are absolutely cracked (just peep their literature drops), so perhaps they themselves provide the correct direction to the mindless drones providing GPU power to their models. A lot of this is TBD at the moment though, and I’m looking forward to seeing how they optimize (Gensyn in particular has mentioned Mixture-of-Expert architectures that would be cool to see in practice).
Bittensor’s and Ambient’s approaches encourage specialization. Templar miners optimize for producing satisfactory gradients quickly, while the owner is in charge of steering the ship towards better and better models. Ambient’s sharded design rewards miners that train the model as well as those that provide inference, instigating a two-pronged approach.
Incentives aren’t just about distributing money. They’re about encoding strategy. And if you want the future of AI to be built by more than just the biggest server farms, you’ll need incentives that are smart enough to see the difference.
Are these projects competitive or collaborative?
Let’s be honest – this space is competitive. Very competitive.
Each team is chasing the same rare resources: top-tier ML researchers, distributed systems talent, GPU allocations, and maybe most importantly – mindshare. Whether it’s Nous’s DisTrO, Prime’s OpenDiLoCo, or Gensyn’s RL Swarm, the biggest credibility boosts in this space have come from dropping real research that actually pushes the frontier. And every paper, benchmark, or framework that lands is a signal to the rest of the ecosystem – “we know what we’re doing.”
It’s a talent arms race, and no one’s pretending otherwise.
But here’s where it gets interesting: all of that research is open-source.
So even though these teams are competing for attention and resources, the ideas themselves flow freely. Gensyn can build on DiLoCo. Nous can improve on Verde. Prime can fork SWARM. That open flow of knowledge is what makes this different from traditional corporate R&D, where IP is locked down and competition is zero-sum.
In that light, you could argue that the ecosystem is more like a loose pipeline of innovation – not because it’s coordinated, but because it’s cumulative. Tools invented by one group often become foundations for others. No formal integration needed.
Case in point: Templar, the live training subnet on Bittensor, is literally using DeMo (from the DisTrO family), a system first developed by Nous. So even though they’re entirely separate projects, one is already accelerating the other – in production – thanks to open tooling.
Still, that doesn’t mean these projects are working together. They’re not forming a nice little assembly line. They’re each trying to be the place where decentralized AI happens. And maybe that’s a good thing – competition drives quality. Without it, we’d probably still be arguing about whether decentralized training is even possible.
As of today, they’re at different stages:
Among them, only Templar (on Bittensor) is currently live in a permissionless, adversarial environment. And they’re already seeing convergence gains vs. baseline approaches. If they hit their next milestone – training a 1.2B parameter model before scaling up to 70B – it could be the first proof that this thing actually works at scale.
The competition really gets spicy when these other projects start generating tokens. After all, the fastest way to gain mindshare is to add an army of bagholders to your ranks. Will a first-to-token race kick off soon between Prime/Gensyn/Nous/Pluralis?
So yes, it’s competitive. But that might be the point. The best decentralized systems aren’t designed in conference rooms. They emerge from pressure – through iteration, collision, and yes, even ego. As long as the ideas remain open, the whole space benefits.
Final thoughts
We started this report with a simple claim: that centralized AI poses an existential threat – and that blockchain might actually be the right tool to do something about it.
Not in the abstract. Not as a buzzword. But as a real, tested infrastructure for aligning global incentives, coordinating compute, and building systems that can survive in the wild. What Bitcoin did for money, this next wave of protocols is trying to do for machine intelligence.
It’s early. Messy. Competitive. But it’s real. And if this momentum holds – if these networks can continue to scale, attract talent, and reward useful contributions – then for the first time, we might be able to build AI that’s not just powerful, but open, composable, and collectively owned.
DISCLAIMER: This report was published for Meal Deal members on April 3.
The author of this report, 563, has exposure to both Bittensor in general (via TAO) and Templar specifically (via its subnet token). He would also have exposure to basically everything else mentioned here, if it were an option (DM secondaries, please). Be aware of this bias while reviewing this report.
⚠️ Note: This article was originally published by Blocmates on X (formerly Twitter). It is republished here with full credit to the author. All rights belong to the original author.



Be the first to comment