

What if training frontier-scale AI models didn’t require hyperscale data centers? What if thousands of GPUs (Graphics Processing Units) connected only through the open internet could collectively train a model rivaling those built inside tightly controlled clusters?
That idea has now taken a major step forward.
A new milestone has been reached on Templar (Bittensor Subnet 3) with the successful completion of Covenant‑72B, the largest decentralized LLM pre-training run in history.
The numbers alone are impressive:
a. 72 billion parameters,
b. ~1.1 trillion training tokens,
c. 70+ independent peers,
d. Fully permissionless participation, and
e. Commodity internet connections.
This was achieved with no centralized GPU cluster, no whitelist of approved participants, and absolutely no private interconnect.
Just a distributed network coordinating large-scale AI training across the open internet, and the results are already competitive with models trained in centralized infrastructure.
The Core Challenge: Bandwidth
The biggest obstacle to decentralized model training isn’t compute power, it is communication bandwidth.
Inside centralized AI clusters, GPUs communicate using extremely high-speed links:
a. 400 Gb/s InfiniBand between servers, and
b. Up to 3.6 TB/s NVLink within a single node.
In contrast, a typical decentralized participant operates with internet speeds closer to:
a. 500 Mb/s on download, and
b. 110 Mb/s on upload.
This difference creates a massive bottleneck.
Traditional distributed training requires synchronizing gradients every step, which works inside high-bandwidth clusters but becomes completely impractical over standard internet connections, especially for a model with 72-billion parameters.
To solve this, the Covenant AI team introduced a new communication strategy.
SparseLoCo: Making Internet-Scale Training Possible
The breakthrough enabling Covenant-72B is a training algorithm called SparseLoCo. Instead of synchronizing dense gradients every step, the system dramatically reduces how often and how much data must be transmitted between peers.
The process works in several stages:
a. Local Computation: Each peer performs 30 optimizer steps locally,
b. Gradient Compression: Gradients are compressed using top-k sparsification, 2-bit quantization, and error feedback correction, and
c. Periodic Communication: Peers exchange compressed updates after multiple steps instead of every step.
This approach reduces network communication by more than 146 times compared to dense gradient sharing, and the performance improvements are striking.
Compared with the earlier decentralized training project INTELLECT‑1:
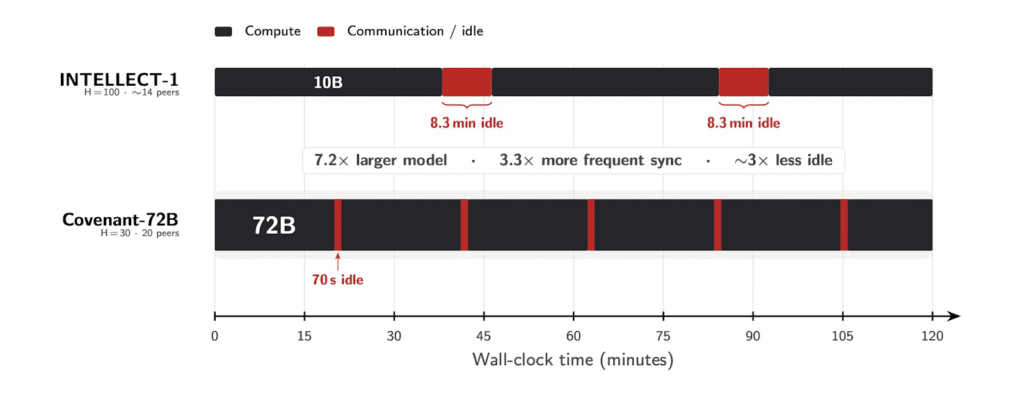
a. Communication Overhead: Covenant-72B recorded ~70 seconds per round while INTELLECT-1 recorded 8.3 minutes per round, and
b. Compute Utilization: Covenant-72B did 94.5%, and INTELLECT-1 did 82.1%
Despite training a model 7.2 times larger, Covenant-72B communicates more efficiently.
Permissionless Training: The Trust Problem
Bandwidth wasn’t the only challenge, the project also aimed to keep participation fully permissionless, meaning anyone with GPUs could join or leave the training process at any time. This creates a unique trust problem.
In decentralized systems, participants might behave dishonestly by:
a. Free-riding (copying other gradients instead of training),
b. Submitting random updates, and
c. Attempting model poisoning attacks.
Previous decentralized training experiments (such as INTELLECT-1 or Psyche Consilience) handled this risk by whitelisting trusted participants, Covenant-72B removed that restriction entirely.
Instead of pre-approving participants, the system continuously evaluates them during training.
Gauntlet: Trustless Validation for Training Updates
To maintain integrity in a permissionless environment, the network relies on Gauntlet, a blockchain-native validation mechanism.
Gauntlet evaluates every training contribution and decides whether it should influence the global model update.
Its scoring system includes several safeguards:
1. Loss Verification: Peers are tested on both assigned and unassigned datasets, ensuring they actually performed training rather than copying others,
2. Liveness Checks: Validators confirm that each peer remains synchronized with the current model state,
3. OpenSkill Ranking: Performance scores are stabilized using ranking algorithms that reduce noise across rounds, and
4. Magnitude Normalization: Updates are normalized so no single participant can dominate the training process.
Through these mechanisms, the network maintains automated trustless validation for every round of training.
Global Participation
Throughout the Covenant-72B training run: 70+ unique peers participated, hardware configurations varied widely, and participants joined from multiple geographic regions.
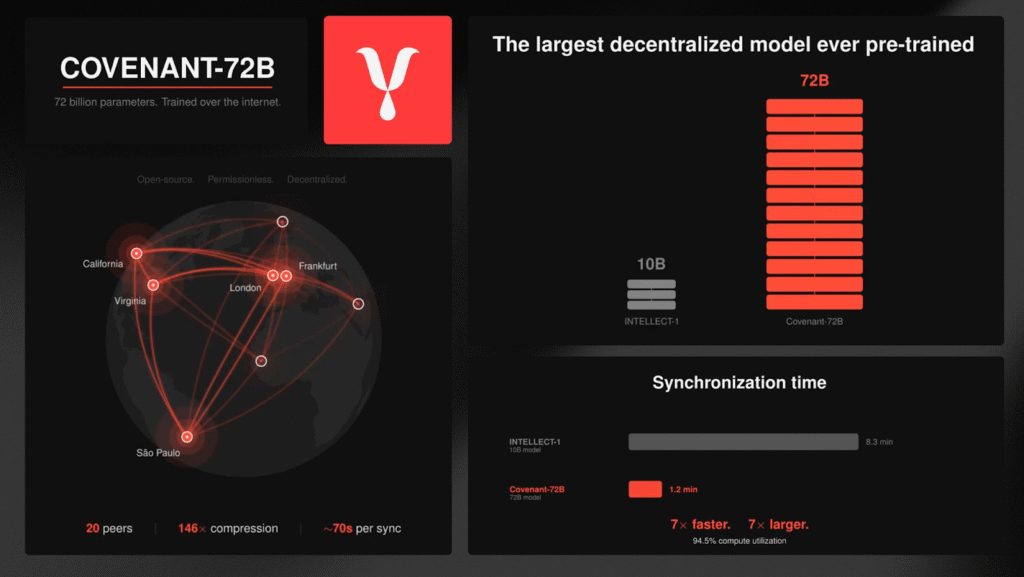
Importantly, the system remained near its peer participation cap throughout the run, demonstrating that open participation can sustain long-training cycles without centralized coordination.
Pre-Training Results
Despite operating entirely over commodity internet connections, Covenant-72B produced results competitive with major centralized open-source models.
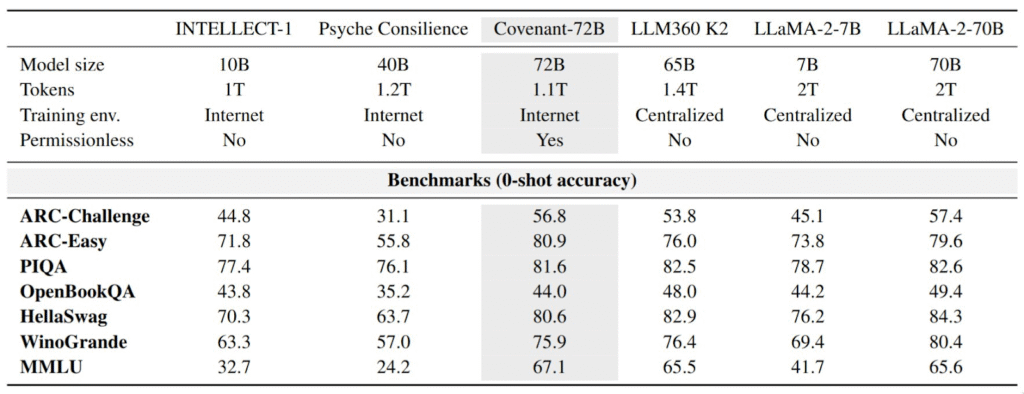
On the widely used MMLU benchmark, it scored 67.1, surpassing Meta’s LLaMA-2-70B and LLM360 K2 whose respective scores are 65.6 and 65.5.
These results suggest that low-bandwidth decentralized training methods can scale far beyond earlier experiments.
Post-Training: Covenant-72B-Chat

Following pre-training, the team developed Covenant-72B-Chat through a two-stage supervised fine-tuning pipeline.
Key improvements include:
a. Context Length Expansion: Increased from 2k to 8k tokens, and
b. Instruction Tuning: Improved task alignment and response quality
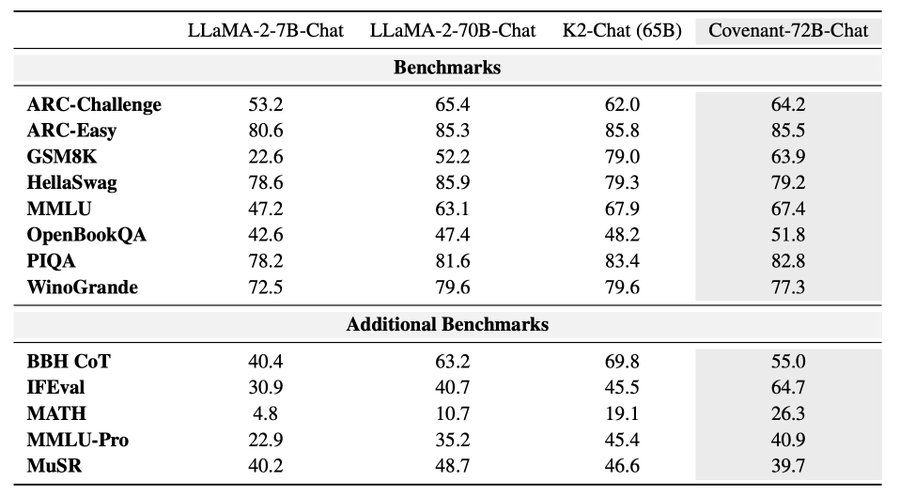
The resulting chat model shows competitive performance across multiple evaluation benchmarks. In particular, it demonstrates stronger results on IFEval (instruction following) and MATH (mathematical reasoning).
These improvements suggest the model performs especially well on structured reasoning and instruction-based tasks.
What Covenant-72B Proves
The success of Covenant-72B demonstrates that large-scale AI training is no longer limited to centralized infrastructure.
By combining SparseLoCo compression (146 times communication reduction), permissionless participation, and Gauntlet trustless validation, the system sustained competitive training of a 72-billion-parameter model over commodity internet connections.
Perhaps the most important takeaway is conceptual: The limitations of decentralized training were never purely technical, they were largely about coordination, validation, and communication efficiency.Covenant-72B shows that when those challenges are solved, distributed networks can begin to approach the scale once reserved for hyperscale AI labs, and this may only be the beginning.

Be the first to comment