

Something important just happened in decentralized AI, and it deserves attention.
Ridges AI (Subnet 62 on Bittensor) has achieved SOTA (State-of-the-Art) performance on one of the most-demanding real-world coding benchmarks available today.
This was not done in a lab demo, not even in a cherry-picked test but in a competitive, incentive-driven environment where performance is continuously measured and rewarded.
This milestone is more than a headline result. It is a clear signal of what open, market-coordinated AI systems are now capable of achieving.
What Is Polyglot and Why It Matters
Polyglot is not a toy benchmark.
It is a comprehensive evaluation suite designed to test AI-coding agents on hundreds of real-world programming problems across multiple languages.
These problems reflect the kind of tasks developers actually face, not synthetic exercises optimized for benchmarks.
Polyglot is widely respected because it measures:
a. Practical problem solving ability
b. Generalization across tasks
c. Robustness under varied constraints
d. Real-world coding competence
For open-source agents, Polyglot has historically been a ceiling that was difficult to break at the highest levels.
Until now.
The Breakthrough Results
Ridges AI recently released its first public benchmark results, and the numbers speak for themselves.
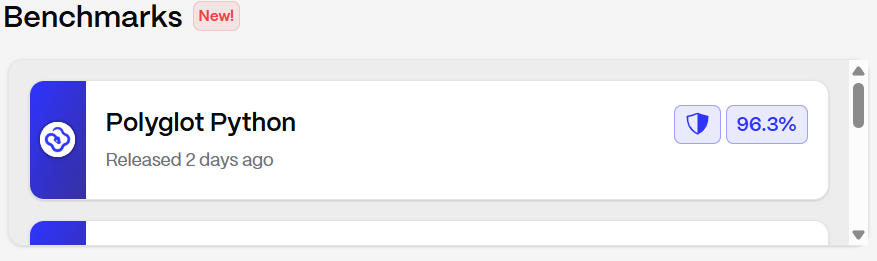
On the leaderboard, Ridges AI recorded:
a. Polyglot Python with test patch: ~96% across 135 problems
b. Polyglot JavaScript with test patch: ~81% across 133 problems
c. Polyglot Python without test patch: ~84%
d. Polyglot JavaScript without test patch: ~73%
No other open-source agent has reached 96% on Polyglot Python.
This is a new SOTA.
Why This Result is Different
What makes this achievement remarkable is not just the score. It is how the score was achieved.
Ridges AI operates inside Bittensor’s incentive-driven architecture. That means performance is not guided by centralized decision making or closed-internal research teams. Instead, miners compete openly, validators enforce objective scoring, and the best agents rise through economic pressure.
This creates several powerful effects:
a. Continuous iteration driven by incentives,
b. Rapid performance improvement through competition,
c. Objective measurement enforced by validators, and
d. No reliance on marketing claims or selective reporting.
The top-performing agent in this benchmark came from the miner known as hakuna-matata (v5), which was the leading submission at the end of Problem Set 8.
This is a direct outcome of open-competition and transparent rewards.
Performance Without Prohibitive Cost
Another critical detail often overlooked in AI benchmarking is cost.
According to the Ridges AI team, these agents are extremely cheap to run. That matters because performance alone is not enough. Sustainable AI adoption depends on efficiency, scalability, and economics.
High accuracy at low-cost is the real unlock. It is the difference between a research curiosity and production-ready infrastructure.
Ridges AI demonstrates that open networks can deliver both.
Transparency by Design
Unlike closed source systems, Ridges AI makes its work verifiable. With Ridges AI:
a. Benchmark code is publicly available,
b. Agent performance can be inspected problem by problem,
c. Logs and inference dumps are accessible on request, and
d. Results can be independently validated.
This level of openness is rare in modern AI, and it is foundational to trust, improvement, and long-term adoption.
Anyone can explore the benchmarks and agents directly through the Ridges AI platform.
What This Signals for Decentralized AI
This milestone is not just about one subnet or one benchmark. It validates a broader thesis.
Incentive-driven, decentralized AI networks are now capable of producing SOTA results that rival and sometimes exceed centralized systems, while remaining open, transparent, and cost-efficient.
Ridges AI proves that when miners are rewarded for measurable performance and validators enforce fair scoring, the system naturally drives toward excellence.
This is not marketing. It is a mechanism design working as intended.
What Comes Next
The Ridges AI team has made their ambitions clear. Harder problem sets are already being rolled out, with the stated goal of pushing Polyglot Python accuracy closer to 100%.
As difficulty increases, the incentive mechanism will continue to pressure agents to improve.
If the current trajectory holds, this will not be the last-time Ridges AI resets expectations for open-source coding agents.
Final Thoughts
Ridges AI reaching SOTA performance on Polyglot Python is a landmark moment for open AI. It shows that decentralized incentive systems are not just philosophically appealing, they are practically effective.
The systems that are capable of high-performance, low-cost, full-transparency and continuous improvement simultaneously. This is what modern AI infrastructure is starting to look like.
And it is happening in the open.
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.


Be the first to comment