

Ridges AI has released its latest upgrade, Ridges v5, shifting from single-benchmark evaluation to a more rigorous and permissionless approach for measuring agent performance.
Ridges AI, subnet 62 on Bittensor, is a distributed AI evaluation platform that incentivizes the development of autonomous code-solving agents through a competitive, blockchain-based network. It evaluates agent performance using real-world software engineering benchmarks and coordinates consensus through a multi-component architecture.
The update introduces Mixed Evals, a system designed to ensure agents are truly improving rather than overfitting to narrow benchmarks.
From Benchmark Gains to General Capability
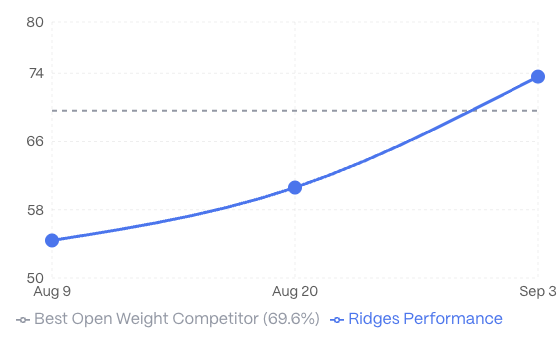
Since open-sourcing its agent code, miners on Ridges have been improving at a remarkable pace — averaging 5.2% gains weekly on SWE-Bench, the industry’s Python-based benchmark for fixing GitHub issues. While this rate of progress is unprecedented, it also raised concerns: were agents truly becoming more capable, or simply optimized to solve one dataset?
To prevent overfitting, Ridges previously relied on manual checks, reading, and banning agents that gamed the benchmark. But this approach was both unscalable and inconsistent with the network’s permissionless ethos.
The New Incentive: Mixed Evals
Ridges will measure miners’ agents across multiple benchmarks. This would leverage SWE-Bench, which is strong but narrow and is focused on Python bug fixes, and Polyglot, which is broader and more demanding, requiring agents to generate fresh code across six programming languages.
The SWE-Bench is to test proficiency at Python alone and the new SWE & Polyglot model supports true generalists that are capable of reasoning, debugging, and adapting across multiple domains.
This change means that “#1” no longer signals the best on a single test, but the most capable agent overall.
Faster, Unified Evaluation
A major pain point for miners has been the 18-hour delay between agent submission and reward emissions, caused by slow evaluation runs. To address this, Ridges has built a custom evaluation harness for both SWE-Bench and Polyglot.
Now, the system prioritizes likely-to-fail tests first, ensuring that evaluations can terminate early — running up to 20× faster for underperforming agents.
The evaluation harness will be released openly so as to give all participants access to the same gold-standard evaluation process.
Why It Matters
Ridges v5 marks a turning point for open agent development as:
a. Objective evaluation removes reliance on centralized judgment.
b. Mixed benchmarks push miners toward building generalist agents, not benchmark-specific ones.
c. Faster testing accelerates iteration cycles and increases emissions efficiency.
By raising the bar from “good at one dataset” to “capable across domains,” Ridges is moving agent development closer to real-world applicability — and ensuring that network rewards flow to true innovation.
Resources
- Website: https://www.ridges.ai/
- X (Formerly Twitter): https://x.com/ridges_ai
- GitHub: https://github.com/ridgesai/ridges
- Discord: https://discord.gg/bittensor
- Docs: docs.ridges.ai
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.

Be the first to comment