
")
For years, progress in artificial intelligence has been framed as a function of scale. Larger models, more data, and increasing compute have driven nearly every meaningful breakthrough.
Yet despite that progress, one constraint has remained stubbornly persistent: Memory.
Not storage in the conventional sense, but the ability of a model to retain, reason over, and reliably use information across long sequences without degradation. As context grows, even the most advanced systems begin to lose coherence, forget earlier inputs, and degrade in performance.
This is a structural limitation, rooted in how attention mechanisms work.
Quasar Attention emerges at precisely this fault line, not as an incremental improvement, but as a redefinition of how memory itself is modeled in modern AI systems.
The Context Window Problem
Transformer-based models rely on attention to connect tokens across a sequence, but this design introduces inherent constraints that become increasingly visible at scale.
a. Attention scales quadratically with sequence length, making long-contexts expensive,
b. Memory and compute requirements grow rapidly, limiting practical deployment, and
c. Performance degrades as sequences extend beyond training distributions.
To address this, the field introduced linear attention variants, including those used in models like Qwen 3.5. While more efficient, these approaches come with trade-offs:
a. Approximation errors that accumulate over time,
b. Instability at extreme sequence lengths, and
c. Reduced precision in long-range retrieval.
The result in a persistent tension between efficiency and reliability, where improvements in one often come at the expense of the other.
Quasar Attention: A Structural Redesign of Memory
Developed by SILX AI and advanced within the Quasar (Bittensor Subnet 24), Quasar Attention departs from conventional approaches by rethinking memory at a foundational level.
Instead of approximating attention more efficiently, Quasar introduces:
a. A continuous-time formulation of memory,
b. A matrix-based internal state, and
c. Update rules derived analytically from differential equations.
This shift replaces heuristic updates with mathematically grounded dynamics, allowing the model’s internal state to evolve in a stable and controlled manner over time.
Continuous-Time Memory: Why Stability Finally Scales
In traditional linear attention systems, memory is updated in discrete steps, with small approximation errors accumulating as sequences grow longer. Over time, this leads to:
a. Drift in the internal representation,
b. Loss of earlier information, and
c. Eventual instability or collapse.
Quasar (Subnet 24) eliminates this failure mode by modeling memory as a continuous system. By integrating differential equations directly into its update mechanism, it achieves:
a. Bounded and stable internal states,
b. Consistent behavior far beyond training context lengths, and
c. Reliable extrapolation to extreme sequences.
This is not merely an optimization, it is a change in how memory behaves under scale.
The Matrix State: Preserving Relationships at Scale
A defining feature of Quasar is its use of a matrix-based memory state, rather than the simpler vector representations used in most linear attention systems.
This enables:
a. High-resolution associative recall,
b. Preservation of relationships between distant tokens, and
c. Robust retrieval even in extremely long contexts.
While this introduces slightly higher per-step computation, the trade-off is decisive. Quasar maintains precision where other systems degrade.
Performance Where It Matters
Quasar’s design has been tested under conditions that expose the limits of existing attention mechanisms.
1. Extreme Context Stability
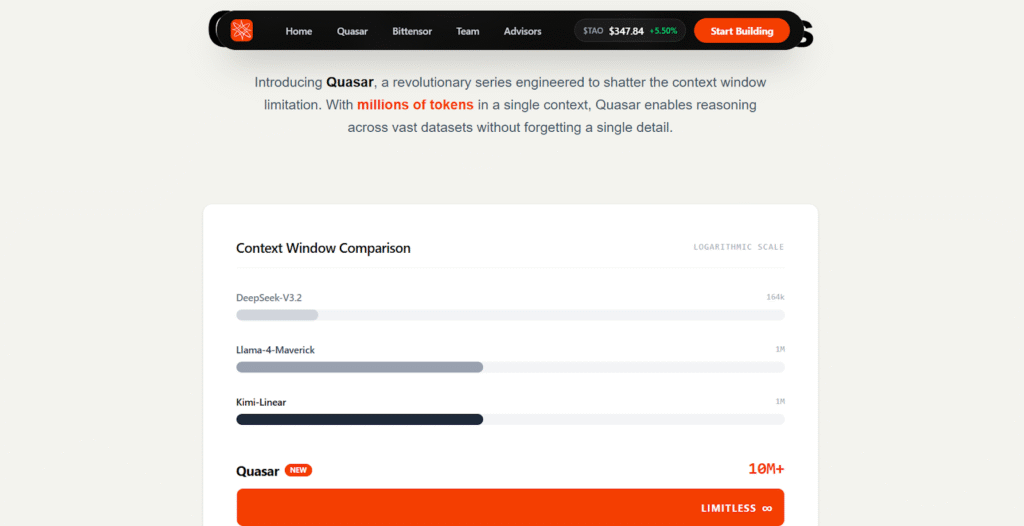
a. Stable performance up to 50 million tokens,
b. No collapse or divergence in internal state, and
c. Competing approaches degrade significantly.
2. Long-Context Generalization (BABILong)
a. Strong extrapolation from short-training sequences,
b. Sustained performance from 1 Million to 10 Million tokens, and
c. Up to 8 times improvement at extreme lengths.
3. Long-Context Understanding (RULER Benchmark)
Using a Quasar-enhanced Qwen model:
a. +3% improvement at 128,000 tokens,
b. +13% at 512,000 tokens, and
c. Over +20% at 1 Million tokens.
These results point to a broader shift in the field: Attention design is becoming the primary driver of long-context capability.
4. Training Stability
a. Smooth gradient behavior across long sequences,
b. No instability spikes seen in competing methods, and
c. Reliable convergence at scale.
5. Hardware Efficiency
Despite its richer representation:
a. 17% to 33% faster in certain configurations,
b. Lower effective memory usage at scale, and
c. Optimized execution through fused GPU kernels.
A Note on Infrastructure: The Role of Targon
While Quasar’s contribution is at the model level, its practical deployment at scale depends on reliable infrastructure.
This is where Targon (Bittensor Subnet 4) plays a supporting role. Developed by Manifold Labs, and collaboration with Intel®, Targon provides:
a. Verifiable and confidential compute environments,
b. Hardware-level attestation for execution integrity, and
c. The ability to run AI workloads on untrusted hardware without sacrificing trust.
In the context of Quasar, this matters because:
a. Long-context models require significant distributed compute,
b. Verification becomes critical as workloads scale, and
c. Trust assumptions must be minimized in decentralized environments.
Targon does not redefine attention or memory, but it enables systems like Quasar to operate reliably in open, distributed settings, particularly within ecosystems like Bittensor.
Hybrid Architectures: Why Quasar Complements, Not Replaces
Quasar performs best when integrated into hybrid attention systems. In practice:
a. A Quasar branch handles long-range dependencies,
b. A Gated Linear Attention branch captures local structure, and
c. A learned gating mechanism blends both outputs.
This reflects a broader design principle: Different scales of reasoning require different mechanisms, and the strongest systems combine them effectively.
What This Unlocks
By addressing the core limitations of attention, Quasar expands what AI systems can realistically achieve.
On New Capabilities
a. Processing extremely large contexts in a single pass,
b. Maintaining coherence across long interactions, and
c. Performing deeper, multi-step reasoning without fragmentation.
New Design Paradigms
a. Reduced dependence on retrieval-based workarounds,
b. More native long-context reasoning, and
c. Simpler architectures for complex tasks.
What Still Needs to Be Proven
Despite strong results, several questions remain:
a. Performance across broader real-world tasks,
b. Behavior at larger model scales, and
c. Long-term production stability.
These are not weaknesses, but areas where further validation is needed.
The Shift Toward Better Memory
For a long time, AI progress has been defined by scaling laws. Quasar Attention suggests that the next phase will be defined by memory
By introducing a continuous-time framework and a richer internal representation, Quasar does not just extend context windows, it removes the constraints that made them fragile in the first place.Infrastructure like Targon ensures that these systems can be deployed and trusted at scale, but the core breakthrough remains that the future of AI will not be limited by how much it can process, but by how well it can remember and reason over everything it has seen.
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment