
")
As LLMs (Large Language Models) continue to improve, the line between human and machine-written text has become increasingly difficult to see. Essays, news articles, social posts, and even academic writing can now be generated at a level that feels convincingly human.
This progress brings clear benefits. It also raises serious questions around academic integrity, misinformation, and transparency.
In November, at the International Conference on AI in Education (ICAIE) in Dubai, a group of independent researchers (who happens to be the leadership at It’s AI) presented a paper that directly addressed one of the biggest blind spots in AI detection today. Not how to build another detector, but how to fairly and reliably evaluate them.
That work, “Towards Reliable Machine-Generated Text Detection: A Unified Benchmarking Framework”, is now formally published in the Journal of the World Academy of Science, Engineering and Technology (WASET), and its conclusions are already reshaping how detection performance is measured.
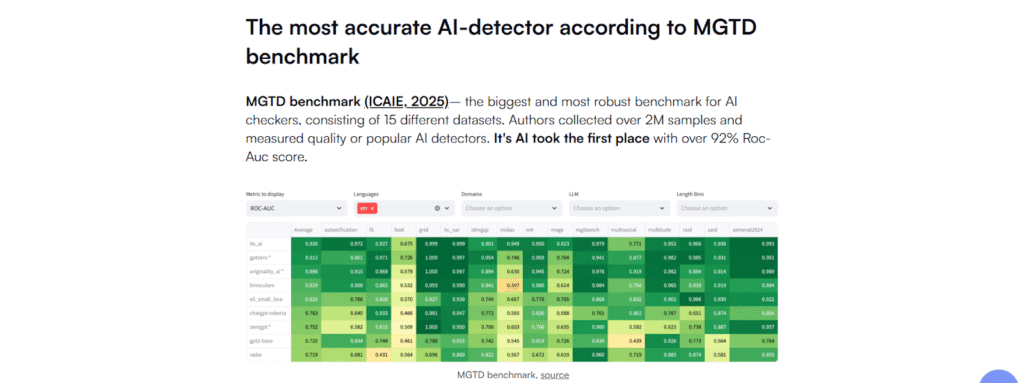
At the center of the findings is It’s AI, which ranked as the most accurate AI text detector in the world under this new unified benchmark.
The Problem with AI Detection Today
Most AI detectors claim high accuracy, the issue is how those claims are measured. Historically, detectors have been tested on isolated datasets, narrow domains, or single languages. This leads to inflated performance numbers and poor insight into how systems behave in real-world conditions.
The paper identifies several persistent issues:
a. Fragmented benchmarks that prevent fair comparison,
b. Overreliance on English-only or single-domain datasets,
c. Lack of testing across different model families and generation styles, and
d. No standard way to evaluate mixed human and AI text.
Without a shared evaluation framework, accuracy claims mean very little.
What is the MGTD Benchmark?

MGTD, short for Machine-Generated Text Detection, is a unified benchmarking platform designed to standardize how AI detectors are evaluated.
Rather than introducing a new detection method, the researchers focused on creating a common testing ground. The benchmark aggregates more than 15 widely used datasets into a single evaluation framework and supports both academic and commercial submissions through a public leaderboard.
What Makes MGTD Different
To truly understand how an AI detector performs in the real-world, it must be tested against more than just simple essays.
MGTD provides this ‘stress test‘ through its unique breadth of data, through:
a. Over two million test samples,
b. Huge coverage across education, news, social media, science, and general writing,
c. Evaluation across more than 30 languages,
d. Inclusion of both open-source and commercial detectors, and
e. Blind test sets to prevent overfitting.
The aim is to make detector performance comparable, reproducible, and transparent.
Going Beyond Full Text Detection
One of the most important contributions of the paper is the introduction of MIDAS, a new dataset built specifically to reflect how AI is used in practice.
In real life, text is often mixed. A human may start a paragraph, an AI may complete it, and another human may revise it again.
To capture this reality, the researchers introduced two complementary datasets:
a. MIDAS-SEG (Machine-generated text Identification Dataset for Segmentation), which labels individual spans inside a document as human or AI-written, and
b. MIDAS-CLF (Machine-generated text Identification Dataset for Classification), which focuses on clean, fully-human or fully-AI documents for classification.
This allows detectors to be evaluated not just on whether a document is AI-generated, but where AI appears inside it. This level of granularity is missing from most existing benchmarks.
How Detectors Were Evaluated
Using the MGTD framework, the researchers evaluated a broad range of detectors, including:
a. Neural open-source models
b. Statistical and metric-based approaches
c. Widely-used commercial detectors
All systems were tested under identical conditions across the same datasets, languages, and evaluation metrics. This removed the ambiguity that typically surrounds detector comparisons.
The Key Findings
Several clear patterns emerged from the results.
1. Short text remains hard to detect
a. Texts under 100 words consistently challenge all detectors
b. Performance improves significantly as text length increases
c. Very short answers, such as quiz responses, remain a weak spot
2. False positives are the real risk
a. Many detectors look strong at loose thresholds
b. Performance drops sharply when false accusations must be minimized
c. This is especially important in education, where errors have serious consequences
3. Language coverage is uneven
a. English and high-resource languages perform best
b. Low-resource and non-Latin languages remain difficult
c. Global robustness is still an open challenge
4. Model type matters
a. Chat-style models are easiest to detect
b. Instruction-tuned models are the hardest
c. Open-source foundation models often blur the line
In summary, detection accuracy depends heavily on how the text was generated.
Where It’s AI Stands Out
Across the aggregated MGTD benchmarks, It’s AI achieved the highest overall accuracy, measured using ROC-AUC across datasets, languages, and conditions.
Notably:
a. It ranked first on the majority of datasets
b. It remained more stable at very low false-positive rates
c. It led performance on the MIDAS segmentation benchmark
The paper explicitly notes that the authors are also the creators of It’s AI, and for transparency, all detectors were evaluated using the same methodology and blind test sets.
The benchmark itself is public and open to future submissions.
It’s AI and Bittensor
It’s AI, powered by Subnet 32 on Bittensor, a decentralized network designed to turn intelligence into a competitive, measurable commodity.
This matters because MGTD demonstrates that serious, peer-reviewed research and production-grade infrastructure can emerge from decentralized systems.
Rather than relying on closed platforms or proprietary benchmarks, Bittensor subnets like It’s AI are proving they can:
a. Compete on objective metrics
b. Publish transparent evaluations
c. Improve through open competition
MGTD is a strong signal that decentralized intelligence is moving beyond experimentation and into real utility.
Why This Research Matters
This paper is not about declaring a permanent winner, it is about raising the standard. By introducing a unified benchmark, span-level evaluation, and public leaderboards, the research shifts AI detection away from marketing claims and toward measurable performance.
It makes one thing clear: If AI is going to be used responsibly in education, research, and public discourse, detection must be evaluated with the same rigor as the models it aims to identify.
MGTD provides that foundation, and for now, according to the most comprehensive benchmark to date, It’s AI sits at the top.
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment