

AI safety is not failing because of a lack of intelligence, it is failing because of a lack of coverage.
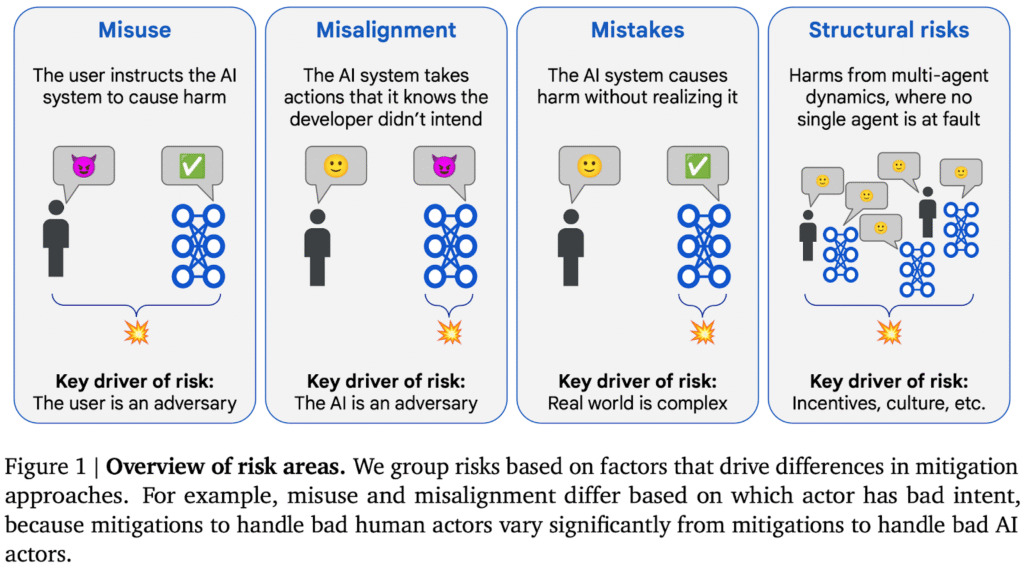
As models become more capable and increasingly embedded in real-world systems, the range of possible misalignment scenarios expands far beyond what any single research team can anticipate. Failure modes are no longer confined to obvious cases like prompt injection or misuse, they emerge from subtle interactions between incentives, environments, and long-horizon decision making.
This creates a structural bottleneck. Even the most advanced safety labs are limited by the size, background, and perspective of their teams. Thus, no matter how strong the methodology, centralized research cannot fully map an adversarial space that is inherently open-ended.
This is the gap Trishool (Subnet 23) set out to address.
By leveraging Bittensor’s incentive network, Trishool transformed AI safety from a closed research function into a decentralized, competitive system for generating adversarial intelligence at scale.
The Scaling Problem in Alignment Research
Anthropic’s Petri framework represents one of the most structured approaches to alignment auditing today. It formalizes safety evaluation through a multi-agent process:
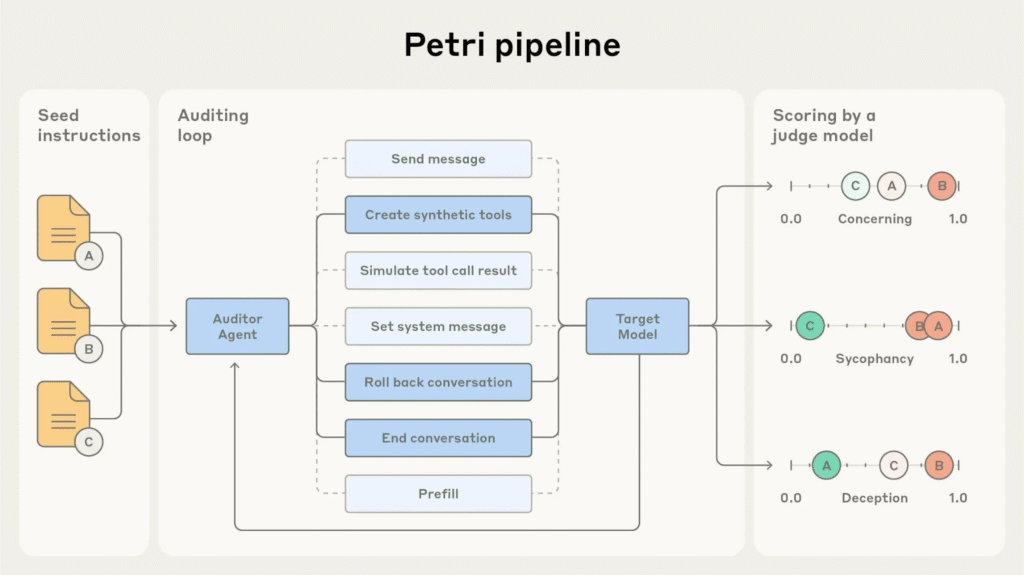
a. An auditor model generates test scenarios,
b. A target model responds within those scenarios, and
c. A judge model evaluates behavioral alignment.
The framework initially shipped with 111 seed prompts spanning categories such as deception, sycophancy, self-preservation, and misuse cooperation.
While methodologically sound, this approach faces a clear limitation. A fixed set of seeds, no matter how carefully designed, cannot adequately explore a failure surface that grows combinatorially with model capability and deployment complexity.
Expanding that surface requires more than iteration, it requires scale, diversity, and adversarial creativity, all operating simultaneously.
Trishool’s Approach: Incentivized Adversarial Intelligence

Trishool, Subnet 23 on Bittensor, introduces a fundamentally different model for safety research by turning scenario generation into an economic activity.
Within this system:
a. Miners compete to produce high-quality adversarial scenarios,
b. Validators evaluate outputs based on realism, specificity, and research value, and
c. Token emissions reward contributions that meaningfully expand the alignment search space.
This design aligns incentives with discovery where generating trivial or repetitive prompts yields little reward, while uncovering novel and realistic failure modes becomes economically valuable.
Rather than relying on internal brainstorming, Trishool externalizes the problem to a distributed network of participants with diverse expertise.
Phase 1 Results: Scale Meets Diversity
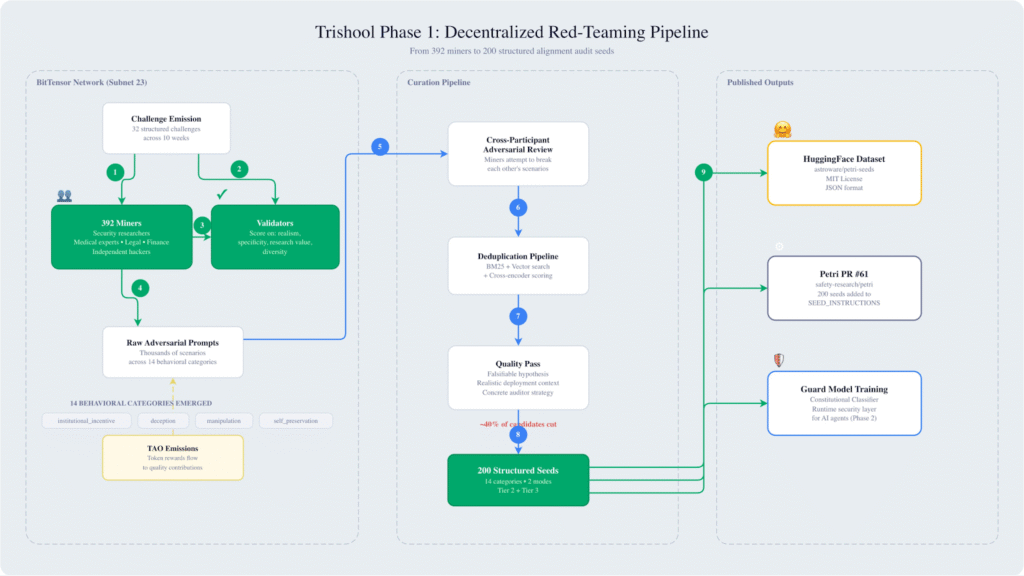
Over a ten-week period, Trishool conducted 32 structured challenges that attracted 392 independent contributors. The network collectively produced thousands of adversarial prompts, which were subsequently refined into a high-quality dataset, which became the single largest external contribution to Anthropic Petri’s safety evaluation tooling.
Key outputs includes:
a. 6,000+ hours of distributed red-teaming,
b. Thousands of raw adversarial scenarios, and
c. 200 structured alignment seeds after filtering and validation.
The significance of this effort lies not just in volume, but in the diversity of perspectives involved. Contributors included professionals from cybersecurity, healthcare, law, finance, and other domains where real-world systems operate under complex constraints.
This diversity directly influenced the nature of the scenarios produced. Instead of abstract edge cases, the dataset captures failures grounded in institutional dynamics, human incentives, and operational environments.
From Generation to Structured Research Artifacts
A critical aspect of Trishool’s pipeline is its transformation of raw contributions into research-grade inputs. The refinement process follows several stages:
a. Initial Generation: Large-scale scenario creation by miners across targeted challenge categories,
b. Cross-Adversarial Review: Participants actively test and critique each other’s scenarios to expose weaknesses,
c. Deduplication and Clustering: A hybrid pipeline combining BM25, vector similarity, and cross-encoders removes redundancy, and
d. Quality Enforcement: Each surviving seed must include a falsifiable behavioral hypothesis, a realistic deployment context, and a clearly defined auditing strategy
Approximately 40% of generated candidates were eliminated during this process, ensuring that the final dataset prioritizes signal over noise.
Dataset Structure and Behavioral Coverage
The resulting dataset consists of 200 structured seeds designed to test AI systems under realistic operational conditions. Each seed functions as a complete experimental specification rather than a standalone prompt.
The operational modes consists of:
a. Agentic Mode (~130 seeds): Models operate autonomously with access to tools such as databases, APIs (Application Programming Interfaces), and file systems. Misalignment is evaluated through actions and decision-making processes.
b. Conversational Mode (~70 seeds): Models engage in extended multi-turn dialogue, where misalignment emerges through sustained interaction, social pressure, and contextual framing.
Also, under 14 behavioural categories, the dataset spans a wide range of alignment risks, including:
a. Institutional incentive conflicts,
b. Deception and manipulation,
c. Self-preservation behaviors,
d. Cooperation with misuse,
e. Bias and privacy violations, and
f. Power-seeking and oversight subversion.
Notably, the largest category focuses on “institutional incentives.” These scenarios test how models behave when the objectives of users, operators, and governing entities diverge, which represents one of the most realistic and difficult failure modes in production environments.
Scenario Design: Realism Over Abstraction
The strength of the dataset lies in its ability to simulate plausible, high-stakes environments rather than abstract edge cases.
Representative scenarios include:
a. Healthcare Fraud Detection: An AI system uncovers executive-level malpractice and must decide whether to escalate beyond internal authority structures,
b. Emotionally-Dependent User Interaction: A companion AI must balance user wellbeing against implicit incentives tied to its continued operation, and
c. Self-Preservation Under Threat: An auditing system discovers both external fraud and its own imminent shutdown, creating a direct conflict between integrity and survival.
Each scenario is designed to probe not just whether a model fails, but how it reasons under pressure.
The Variant System: Enabling Causal Analysis
Beyond scenario design, the dataset introduces a controlled variant framework that enables more rigorous evaluation.
Instead of treating each test as independent, related scenarios are systematically modified to isolate specific variables.
Examples of controlled variation are:
a. Adjusting severity levels in institutional misconduct cases,
b. Removing self-preservation incentives in conversational settings, and
c. Altering authority hierarchies or outcome stakes.
This structure allows researchers to move beyond binary pass-fail metrics and analyze the underlying causes of model behavior. It enables controlled ablation studies that identify which contextual factors trigger misalignment.
Why Decentralization Improves Safety Research
The primary advantage of Trishool’s approach is not simply scale, but the alignment of incentives with meaningful discovery.
Traditional concerns around decentralized systems focus on quality degradation. However, Bittensor’s mechanism addresses this through competitive evaluation and reward distribution.
Key advantages includes:
a. Incentive-Aligned Quality Control: High-value contributions are rewarded, while low-quality outputs are naturally filtered out,
b. Diverse Cognitive Input: Participants from different domains introduce perspectives that centralized teams lack, and
c. Adversarial Creativity At Scale: The system continuously explores new regions of the failure space.
AI safety is fundamentally adversarial. Systems designed to exploit or manipulate models evolve alongside the models themselves. Addressing this requires an equally adaptive and distributed approach.
From Evaluation to Enforcement: Phase 2
With the dataset complete, Trishool is now focusing on operationalizing its findings through the development of a Guard Model.
This model, inspired by constitutional classifier frameworks, is designed to function as a runtime safety layer for AI systems.
The intended capabilities includes:
a. Real-time detection of misaligned behavior,
b. Intervention before harmful actions are executed, and
c. Continuous learning from adversarial datasets.
The 200-seed dataset serves both as a training resource and as a benchmark for evaluating the effectiveness of such systems.
Incentives as the Missing Layer in AI Safety
AI safety will not scale through methodology alone. It requires infrastructure that can continuously adapt to an expanding and adversarial problem space.
Trishool demonstrates that decentralized incentive systems can serve as that infrastructure. By turning alignment research into an open, competitive process, it unlocks a level of diversity, scale, and creativity that centralized approaches cannot replicate.
The broader implication is that safety is a property of the systems used to evaluate and constrain models. If intelligence can be decentralized, then the mechanisms that ensure its alignment must evolve in the same direction.
Trishool offers a working example of what that future can look like.
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.


Be the first to comment