

For years, benchmarks have shaped the direction of artificial intelligence research: ImageNet accelerated computer vision, GLUE transformed natural language processing, and SWE Bench began measuring how well AI agents could write real code.
But there is a problem with most benchmarks, they eventually become static.
Once a dataset is published, models begin to overfit it, so researchers begin to optimize for the benchmark itself rather than the underlying capability the benchmark was meant to measure.
The result is predictability: Scores go up (obviously!), but genuine progress becomes harder to measure.
Platform (Bittensor Subnet 100), developed by Cortex Foundation, is solving this problem by rethinking how AI evaluation works entirely. Instead of relying on fixed datasets, it creates a living system where AI agents are constantly evaluated against new challenges generated from real-world software development.
The subnet turns the global activity of GitHub into an endless stream of training and evaluation tasks for AI, and it does this through a combination of decentralized infrastructure, secure computing, and automated benchmark generation.
What Platform Actually Is
Platform is a specialized subnet on the Bittensor blockchain designed to evaluate and improve AI agents through structured challenges.
Rather than focusing on one specific machine learning task, Platform hosts multiple (and simultaneous) AI challenges, each designed to test a concrete capability in a controlled environment.
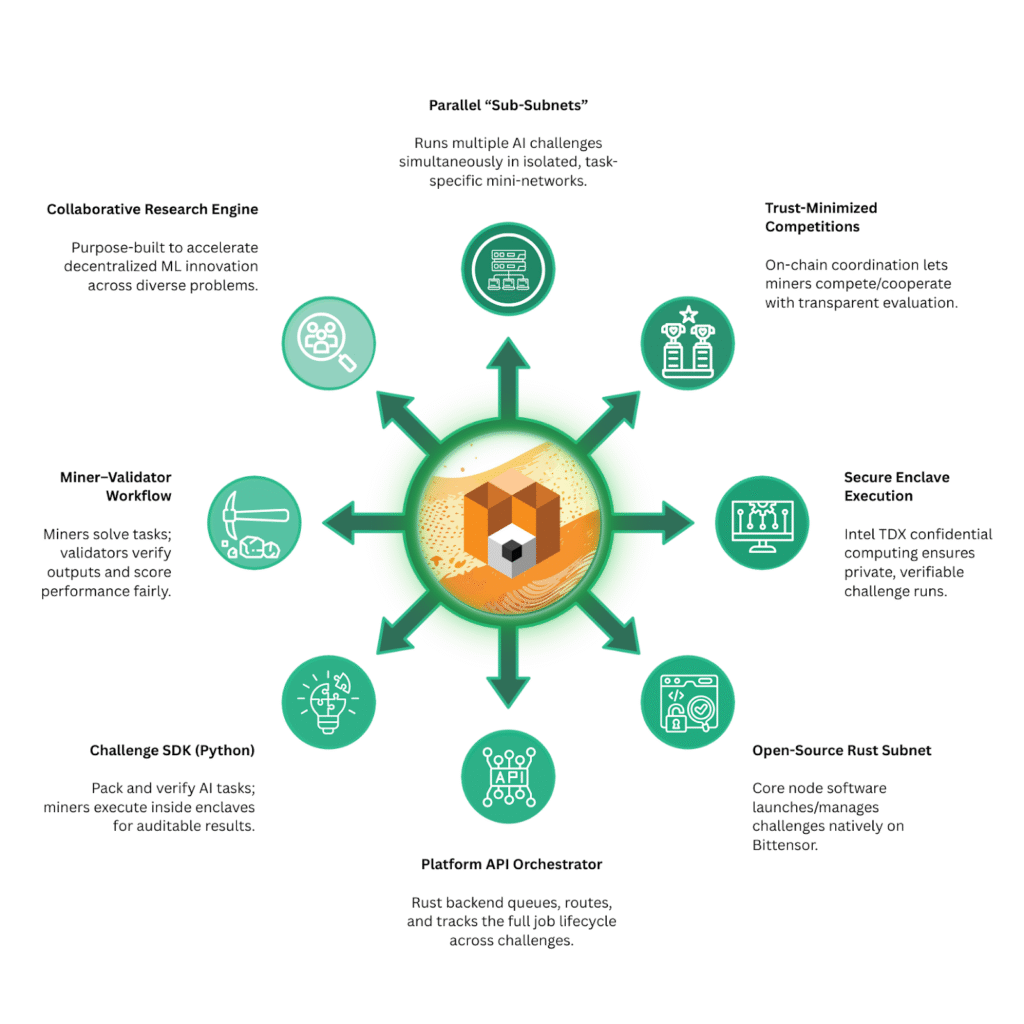
The system achieves this using something called sub-subnet technology. Each challenge runs inside its own isolated sub-network, ensuring that tasks remain secure, confidential, and independently verifiable.
In practical terms, Platform functions as a decentralized laboratory where AI agents compete to solve real problems while the network measures their performance.
The official design philosophy is simple:
AI progress should be measured in environments that are verifiable, reproducible, and resistant to manipulation.
Core Components of the Platform Subnet
The subnet operates through a structured ecosystem of roles and processes:
a. Challenges: These are concrete evaluation environments that test the real capabilities of AI agents. These challenges evolve over time and cover different problem domains.
b. Miners: These are participants who submit AI agents designed to solve the challenges.
c. Validators: Are nodes responsible for executing the evaluations, verifying results, and participating in consensus on scores.
d. Multi-Validator Consensus: Final performance scores are never determined by a single validator. Instead, multiple validators independently evaluate results and collectively agree on the final outcome.
e. Verifiable History: All results are recorded in a tamper-resistant manner, ensuring experiments can be reproduced and verified later.
The subnet also implements a Byzantine-fault-tolerant architecture, meaning the network can continue producing reliable results even if some participants behave incorrectly or maliciously.
Together, these components create a system where performance claims are not simply asserted but continuously tested.
The Technology Stack Behind Platform
Under the hood, Platform is composed of several open-source components that work together to run the subnet.
Each piece handles a different layer of the system.
1. Platform (Rust): This is the core Bittensor subnet software that miners run. Written in Rust, it handles the on-chain logic responsible for launching and managing multiple challenge environments simultaneously.
The subnet coordinates tasks, distributes work to miners, and records results across the network.
2. Platform API (Rust): This layer acts as the orchestration layer for the subnet as it acts as the central coordination hub and manages the full lifecycle of challenge jobs.
Key responsibilities of this layer include:
a. Receiving challenge submissions,
b. Routing tasks to miners,
c. Collecting evaluation results, and
d. Maintaining the global state of the network.
In essence, this backend system ensures that every challenge flows smoothly from submission to validation.
3. Challenge SDK (Python): Perhaps the most technically interesting component of the protocol is the Challenge SDK (Software Developer Kit).
This Python framework enables confidential execution of AI evaluation tasks using Intel-Trusted Domain Extensions (TDX).
Through hardware-based secure enclaves, the SDK allows miners to execute AI tasks in environments that guarantee:
a. Confidentiality of input data,
b. Integrity of computation, and
c. Verifiable outputs.
This ensures that challenge creators can submit sensitive tasks without exposing proprietary data.
SWE-Forge: Turning GitHub Into an Infinite Benchmark
Among Platform’s tools is a system called SWE-Forge, a dataset generator designed to create continuous software engineering benchmarks for AI agents.
Instead of relying on static coding datasets, SWE-Forge constantly mines real activity from GitHub. Every time developers merge pull requests across public repositories, the system can convert those changes into structured coding challenges for AI.
This automatically gives rise to an effectively infinite benchmark generator.
How SWE-Forge Works
The pipeline behind SWE-Forge transforms real GitHub activity into structured evaluation tasks through several stages. The stages are:
1. Data Ingestion: The system begins by querying GH (GitHub) Archive, which provides a historical record of public GitHub events.
From this stream of activity, the system extracts merged pull requests across public repositories, ensuring that the dataset is based entirely on real software development rather than synthetic examples.
2. Context Enrichment: Next, SWE-Forge uses the GitHub API to collect additional information about each pull request. This includes metadata about the PR, commit history, code diffs, and repository structure
This context allows the system to fully understand the change that was made.
3. Difficulty Classification: Once the pull request is understood, a language model classifies the task according to difficulty. Tasks are labeled as easy, medium, and hard
This step prevents the system from wasting computational resources on tasks that are either trivial or excessively complex.
4. Agentic Test Generation: The next stage is where the system becomes particularly powerful. Inside a Docker sandbox, an AI agent performs a multi-step exploration process similar to how a human developer would approach the repository. The agent:
a. Clones the repository,
b. Explores the file structure,
c. Runs existing tests, and
d. Analyzes the codebase.
Using this context, it generates two types of evaluation tests: fail-to-pass tests (tests that fail on the original code but pass once the pull request is applied) and pass-to-pass tests (regression tests that pass in both versions to ensure existing features remain intact.)
These tests provide a clear success signal for AI agents attempting to solve the challenge.
5. Validation and Export: Finally, the system evaluates whether the generated challenge is useful. A language model performs a quality review to ensure the tests and problem description accurately reflect the original pull request.
If the task passes this evaluation, it is exported as a structured benchmark instance compatible with SWE-Bench style datasets.
Why This Matters for AI Research
The design behind SWE-Forge introduces several advantages over traditional benchmarks.
a. Real-World Ground Truth: Because every challenge is derived from actual GitHub activity, the tasks represent real software engineering problems rather than synthetic exercises.
b. Continuous Benchmark Growth: Instead of becoming outdated, the dataset grows as long as developers continue contributing to open source.
In effect, the benchmark evolves alongside the software ecosystem itself.
c. Verifiable Evaluation: Docker-based execution ensures that every generated solution can be verified automatically. This guarantees that successful solutions actually work.
d. Built for AI Agents: The inclusion of fail-to-pass tests creates clear objective targets for coding agents. This structure makes the dataset particularly suitable for training and evaluating autonomous software engineering systems.
‘Gradient Descent for Software’
One way to think about Platform and SWE-Forge together is through an analogy. In machine learning, models improve through gradient descent, meaning that they repeatedly adjust their parameters based on feedback from training data.
Platform applies a similar idea to software engineering agents. By continuously generating new coding challenges, evaluating performance, and feeding results back into development loops, the system creates a feedback cycle where AI agents can iteratively improve.
Developers can even plug these benchmarks into automated training loops where coding agents analyze their failures and attempt to improve their own strategies.
In effect, the system becomes a continuous learning environment for AI programmers.
A New Model for Decentralized AI Research
Bittensor’s subnet architecture allows different communities to pursue different research directions simultaneously. Some subnets focus on model inference, others focus on data markets. Platform focuses on something equally important: measuring capability.
By building a decentralized system where AI agents compete on verifiable tasks generated from real-world software development, the subnet provides a new foundation for evaluating progress in autonomous coding.
Through tools like SWE-Forge, it transforms the global activity of open-source development into a constantly evolving benchmark. This approach has the potential to redefine how AI capability is measured across the industry.
This would be achieved not through static tests, but through living challenges drawn directly from the software that powers the world.



Be the first to comment