

Artificial intelligence has long been trained in massive data centers, behind closed doors, powered by specialized hardware and deep technical expertise.
That model is now being challenged right on Bittensor ecosystem.
Train at Home, built by Macrocosmos under its Iota (Subnet 9), has officially been opened to the public. What began as a carefully controlled beta, rolled out in waves to test scalability and architecture, is now live for anyone with compatible machines (specifically Macs) and a stable internet connection.
The result is something ambitious: a distributed global training network powered by consumer hardware and coordinated through Bittensor.
What Train at Home Actually is
Train at Home is a distributed AI pre-training architecture that allows individuals to contribute compute from their personal machines to collectively train large scale models.
Instead of relying solely on data centers, it aggregates contributions from everyday users. Each participant’s machine trains part of the same model, coordinated across the network.
Key characteristics:
a. Designed for consumer-grade hardware,
b. Zero requirement for ML (Machine Language) knowledge,
c. Integrated with Bittensor rewards, and
d. Focused on collaborative pre-training.
Participants are not running “toy” workloads; they are contributing to live AI model development and, depending on the quality of their contributions, earning rewards from the Bittensor protocol.
Learn more about Train at Home here.
What Has Already Been Achieved
The most recent completed training run demonstrates what consumer hardware can accomplish collectively. The last run overview of the model is:
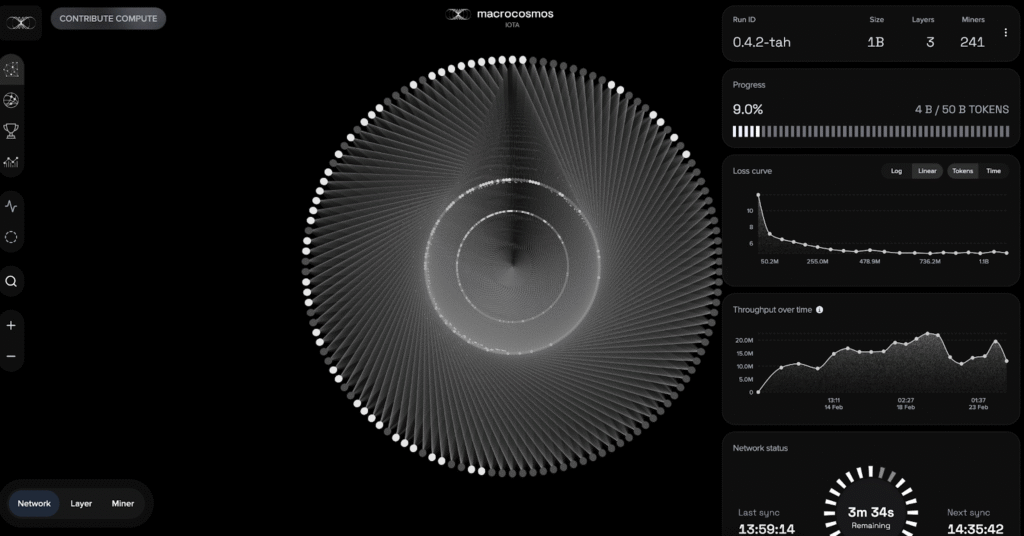
a. Model Size: 1.5 billion parameters,
b. Total Training Time: 13 days,
c. Unique Participants: 815,
d. Tokens Processed: 4.5 billion, and
e. Lowest Loss Achieved: 4.719
All of this was achieved on consumer-grade machines. That scale, coordinated across hundreds of devices, signals a meaningful shift in how distributed training can operate.
The Move to Version 0.4.3
With growth comes complexity. As participation increased, so did:
a. Machine unreliability,
b. Heterogeneous hardware conditions, and
c. Network variability.
To address this, the team launched a new run under version 0.4.3 with a major experimental feature: Optimizer State Sharing Protocol.
What Optimizer State Sharing Does
What this Optimizer State Sharing does is that it eliminates unnecessary warm-up alignment periods, improves miner utility, reduces training noise, and accelerates convergence.
Previously, new miners required time for their local optimizers to align with layer groups, but this new protocol shares optimizer states across participants, smoothing that process.
This run is experimental: Uploading optimizer states involves large files, and as such, bandwidth limitations may create friction.
The team plans to evaluate results through A/B testing and iterate accordingly.
Upcoming Improvements
The roadmap reflects continued ambition:
a. Multi-pool runs to increase miner capacity,
b. Peer-to-peer communication to reduce latency,
c. Dynamic network topology for throughput optimization, and
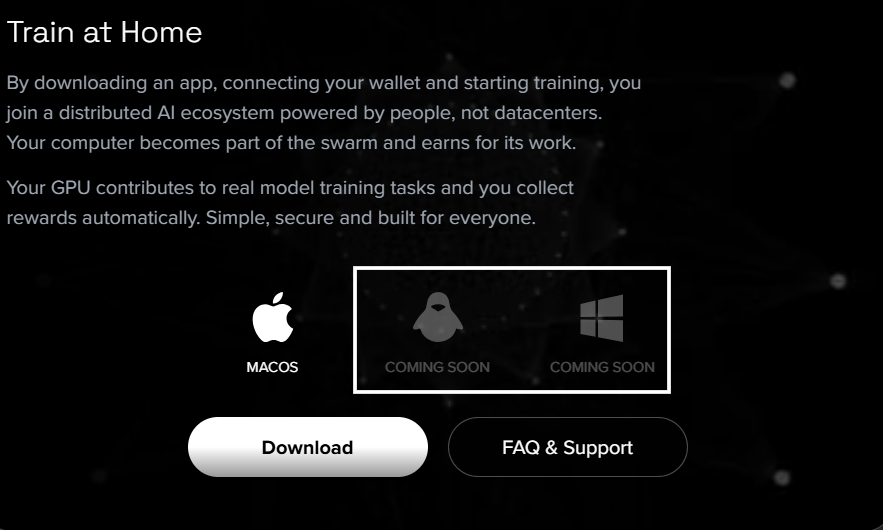
d. Linux support, followed by Windows.
A Different Vision for AI Infrastructure
Train at Home represents a philosophical and technical shift, it reframes AI training from a centralized industrial process into a collaborative global effort.
Instead of compute being concentrated in a handful of facilities, it is distributed across thousands of personal machines.
The implications extend beyond hardware:
a. Broader participation,
b. Incentive-aligned collaboration,
c. Reduced dependency on centralized providers, and
d. Economic integration via Bittensor rewards.
The ecosystem expands outward, it does not “just” grow vertically.
The New Era of Mac-Mining
AI has often been described as the defining technology of the decade, yet, participation in building it has remained exclusive.
Train at Home opens that door.
Anyone with a compatible machine (MacBooks for now) can join a live distributed training swarm: No ML (Machine Language) knowledge/background is required, no need for specialized hardware; just compute, coordination, and contribution.
It is still early, as the system is still evolving. But the architecture is live, the models are training, and hundreds of participants are already contributing.
If distributed AI is going to scale globally, it will not happen solely in data centers; it will happen in homes.
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment