

For years, the final stage of AI training has remained quietly centralized. After a model is pre trained, the most important work still lies ahead. This final phase, known as post training, is where models learn to reason better, follow instructions more reliably, and perform well on complex tasks like mathematics, coding, and logic. Reinforcement learning plays a crucial role here.
But reinforcement learning has a problem. It is expensive, operationally complex, and almost entirely controlled by a small group of well capitalized organizations.
Grail (Subnet 81) proposes a different future. With the release of its flagship project named Grail v0, decentralized reinforcement learning moves from theory to reality.
For the first time, open, incentivized reinforcement learning is running live on a decentralized network, powered by the Bittensor infrastructure.
This is not ‘a’ concept demo. It is a working system.
What is Grail?

Bittensor Subnet 81, Grail, is a decentralized AI training network where a global community collaborates to train large language models using shared compute. Miners contribute hardware, train models through Bittensor, and earn rewards based on the quality of values provided.
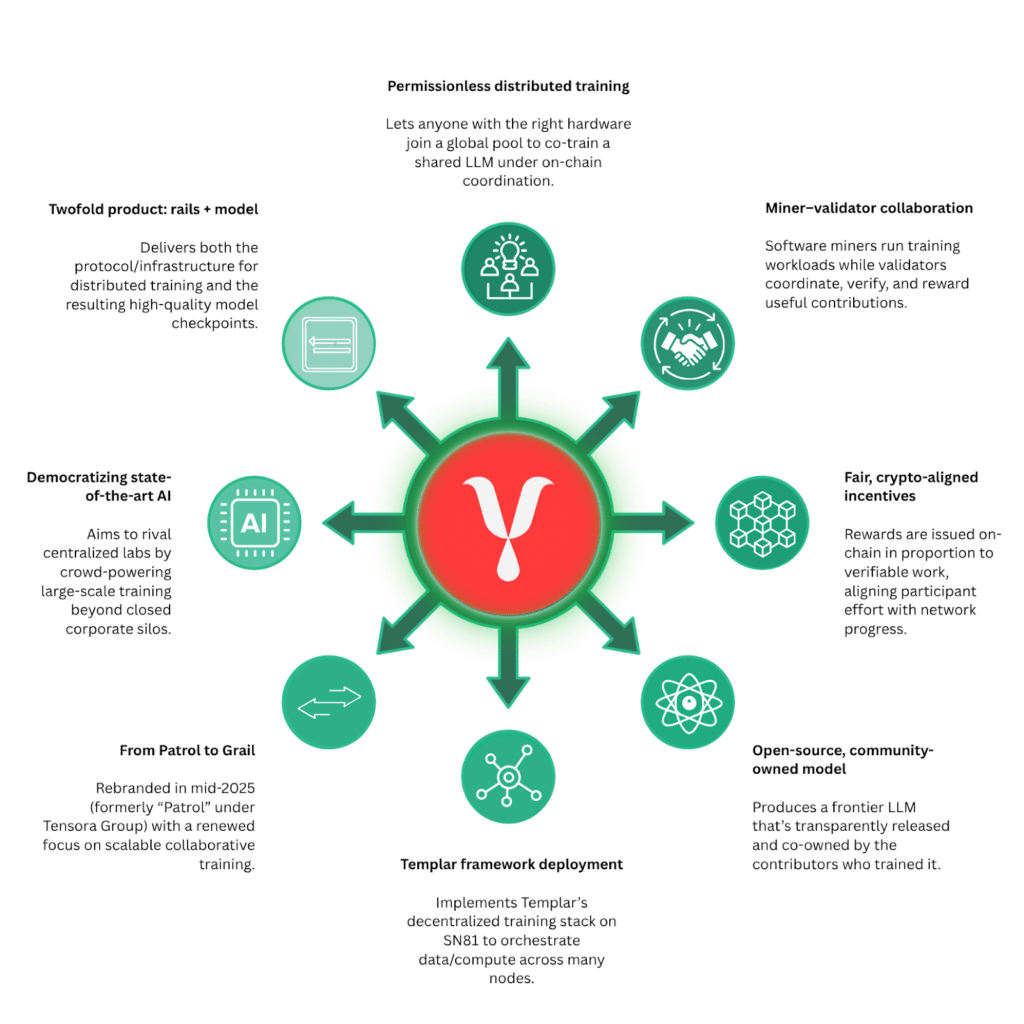
Grail’s goal is to make large scale model training permissionless, incentive aligned, and community owned. By doing this, it aims to bring advanced AI development out of closed labs and into open networks anyone can participate in.
Why Reinforcement Learning Has Been Out of Reach
Reinforcement learning is one of the most powerful tools in modern AI development, but it comes with steep requirements.
Most teams face several barriers, such as:
a. High compute costs tied to continuous model interaction,
b. Complex coordination between data generation, verification, and training,
c. Heavy reliance on centralized infrastructure and trusted operators, and
d. Significant upfront capital requirements.
For many open-source teams and independent developers, this makes high quality post training effectively inaccessible.
Grail v0 was built to remove those constraints.
What Grail v0 Introduces
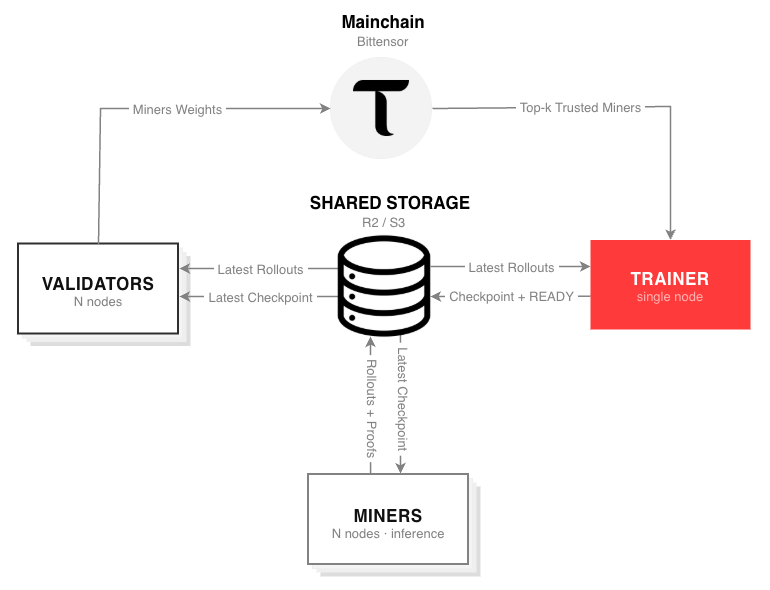
Grail v0 decentralizes reinforcement learning by breaking the process into clearly defined roles, each incentivized and verified on-chain.
The system operates through three core participants:
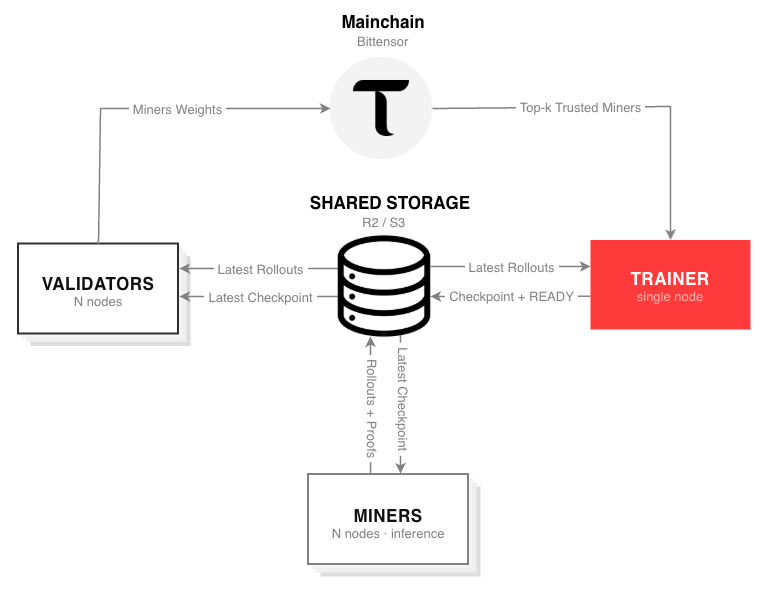
a. Miners generate training examples, known as rollouts. These examples show how a model attempts to solve a task and explain its reasoning step by step.
b. Validators ensure integrity. They verify that rollouts were generated by the correct model and not by smaller or manipulated substitutes. This system is put in place to prevent cheating and preserve training quality.
c. Trainers collect verified rollouts and use them to improve the model through reinforcement learning updates.
This separation of responsibilities allows the network to scale while maintaining trustless coordination.
The Key Innovation Behind Grail v0
At the heart of the system is a new verification mechanism known as grail proofs.
Grail proofs are cryptographic guarantees that ensure rollouts genuinely come from the intended model. They are lightweight, requiring only a few bytes per token, yet secure against forgery.
This matters because it removes one of the biggest risks in decentralized training: dishonest participation.
With grail proofs, accuracy is enforced by design, not by trust.
Real World Results, Not Promises
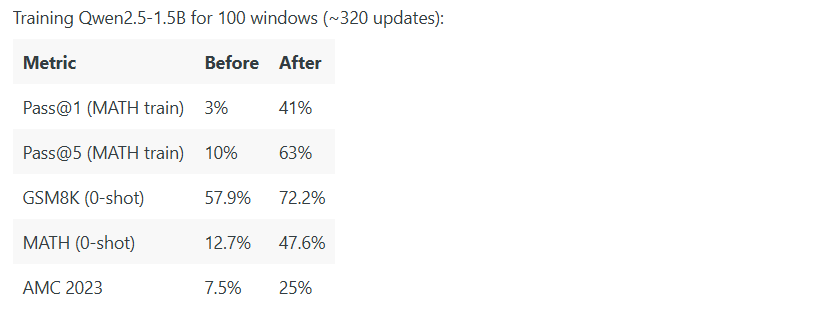
Grail v0 has already demonstrated real performance. It was instrumental in training Qwen2.5-1.5B model on mathematical reasoning tasks using the decentralized Grail’s pipeline. The results matched those of traditional centralized reinforcement learning frameworks such as TRL.
In practical terms, this shows that decentralized reinforcement learning can compete on quality, not just ideology.
Why This Matters for the Bittensor Ecosystem
Grail v0 validates a broader architectural vision for decentralized AI. Different subnets can now specialize and collaborate:
a. A model can be pre trained on one subnet, such as Templar,
b. It can then be post trained using reinforcement learning on Grail, and
c. Additional refinement can flow through other specialized subnets like Gradients or Affine.
This creates a modular, composable training pipeline with no central coordinator. Intelligence production becomes collaborative, permissionless, and competitive.
What This Means for the Broader AI Community
Beyond Bittensor, Grail v0 carries wider implications. With it:
a. Reinforcement learning no longer needs to be opaque or proprietary,
b. Every rollout, proof, and training update is publicly observable,
c. Developers can access high quality post training without massive capital, and
d. Innovation shifts from infrastructure ownership to model quality.
In short, the economics of AI post training begin to open up.
What Comes Next for Grail
Grail v0 is an early milestone, not the finish line. With this, several improvements are already underway:
a. Faster training through reduced communication overhead,
b. Support for larger models beyond 1.5B parameters in pipeline,
c. Improved incentive design to reward higher quality contributions, and
d. Deeper transparency with fully auditable training pipelines.
Each step moves decentralized reinforcement learning closer to production scale adoption.
An Open Invitation to Build
Grail v0 is fully open source; The code, training logs, and verification proofs are all public and reproducible. Developers can inspect the system, monitor live training, and build on top of it without permission.
The long-term goal is simple but ambitious: to make high quality AI post training available to anyone, anywhere, through an open network.
Centralization was never inevitable and with Grail v0, decentralized reinforcement learning is no longer theoretical. It is live, verifiable, and already working.
The future of AI development may be more open than many expected.
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



{kind=link}
Be the first to comment