

We are entering a world where sound matters more than ever. Every day, millions of hours of voice recordings are created through meetings, podcasts, customer calls, short-form videos, and everyday conversations online. Yet most of this audio is messy, noisy, and unusable for AI training or professional media use.
SoundsRight, Subnet 105 on Bittensor, is building the infrastructure to fix that. It is focusing on one clear mission: open access speech enhancement, powered by decentralized competition rather than closed corporate labs.
It is a simple idea with powerful outcomes. If the world is recording itself at scale, someone needs to clean, enhance, and unlock that speech data. SoundsRight wants to be the network that does it.
What is SoundsRight?

SoundsRight, built on Bittensor, is dedicated to speech enhancement. It hosts daily model competitions that improve how machines clean audio. These competitions refine models that remove background noise, reduce echo, and make speech crystal clear.
Think of it as a global lab where models constantly learn to turn noisy sound into clean voice recordings.
Use Cases of SoundsRight
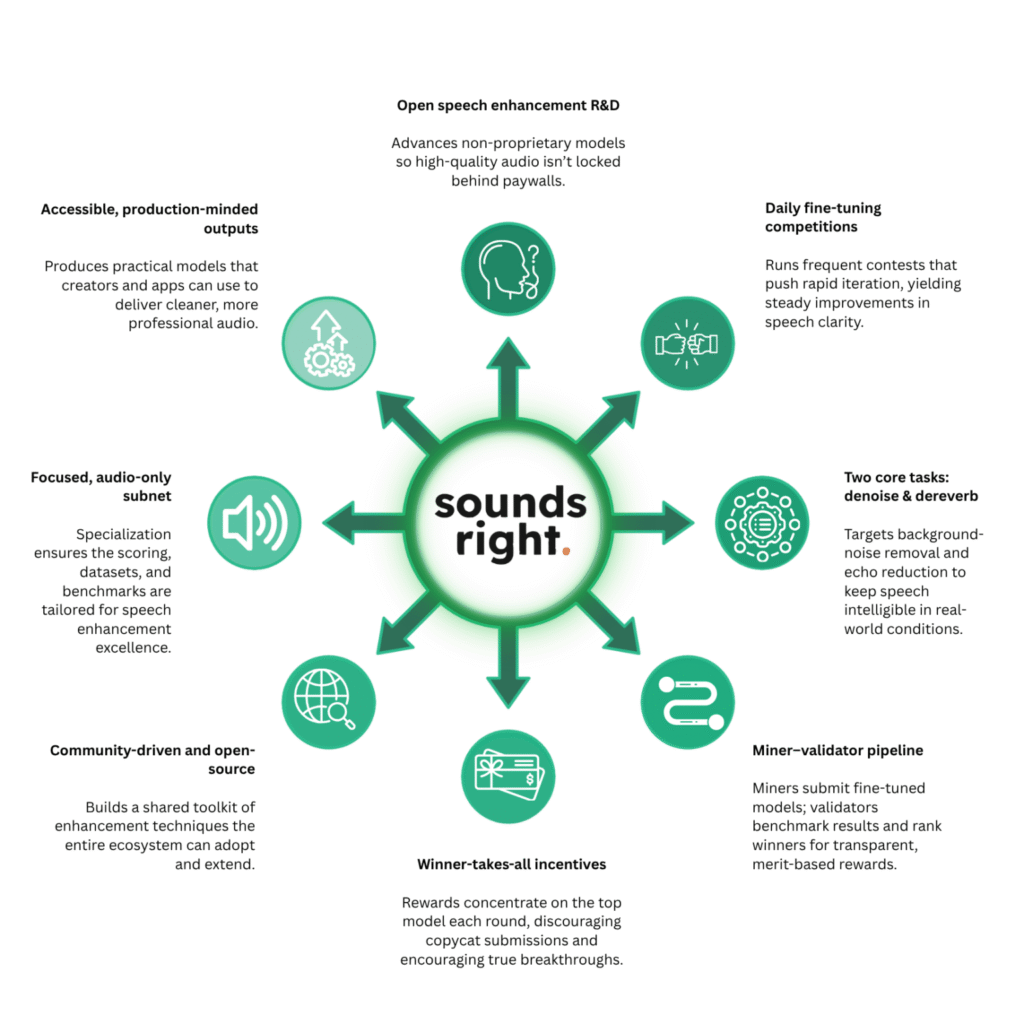
Clear audio is becoming a new digital standard, and SoundsRight is stepping in to make it accessible for everyone
a. Open Speech Enhancement Research and Development
Advances non proprietary models so high quality audio stays open and accessible, not locked behind paywalls.
b. Daily Fine Tuning Competitions
Runs frequent model contests that accelerate improvement and steadily raise speech clarity performance.
c. Two Core Tasks: Denoise and Dereverb
Targets background noise and echo removal to make speech clear and intelligible in real environments.
d. Miner and Validator Pipeline
Miners submit fine tuned models and validators benchmark, rank, and reward top performers based on merit.
e. Winner Takes all Incentives
Rewards focus on the best model each round, discouraging copycat work and pushing real breakthroughs.
f. Community Driven and Open Source
Builds shared tools and techniques that anyone can adopt, extend, and improve.
g. Focused: Audio Only Subnet
Purpose built for speech enhancement, with specialized scoring, datasets, and benchmarks for excellence.
h. Accessible: Production Minded Outputs
Delivers models creators and apps can use to produce cleaner, more professional audio at scale.
How SoundsRight Works
Instead of building one model behind closed doors, SoundsRight lets many builders compete daily. The best enhancement model wins rewards. Over time, the network evolves faster than a single company ever could.
SoundsRight leverages Bittensor’s miner-validator structure to deliver:
a. Miners
These are the developers/builders. They create and refine speech enhancement models that remove noise or reduce echo. When ready, they upload their work to HuggingFace for the network to test.
b. Validators
These are the judges. Every day they create fresh audio samples, download models from HuggingFace, verify who built them, and put them through a series of tests (benchmarks). The best performing model wins the round and earns rewards.
Together, this structure has been useful in executing the following on audios:
a. Denoising speech (Removing background noise whilst preserving quality).
b. Removing echo and room reverb (Eliminating echos and vibrations that occurs when audio is recorded in reflective rooms)
Every improvement becomes open source. The goal is simple: turn the world’s raw audio into clean training grade speech data.
Who Uses SoundsRight
Right now, the network is attracting:
a. Audio ML researchers
b. Open source contributors
c. Builders experimenting with voice AI
d. Early stage AI enterprises studying voice automation
It is still early, but the audience is serious and technical. They see a huge future for audio based AI and want the infrastructure to be open.
Why SoundsRight Matters
Voice is fast becoming a core input for AI. Clean audio directly impacts voice assistants, customer service automation, education platforms, speech to text systems, medical transcription, multilingual translation models, podcast and media production and enterprise meeting intelligence
Better audio means better data. Better data means smarter AI. SoundsRight sits right at the foundation of that value chain.
…In the Long Run
In the long run, the customer base are consumers of clean audio who would include (but not limited):
a. Media companies
b. Enterprise call centers
c. AI research labs
d. Edtech platforms
e. Health care voice analytics
f. Cloud communication providers
g. Translation companies
h. Voice assistant companies
Anyone who works with voice at scale becomes a customer.
Why SoundsRight Wins Here
Speech data needs global diversity, millions of real environments, infinite voice conditions, collective intelligence and continual learning
No single company can gather everything. A decentralized approach scales better, faster, and with more variety; and this is exactly what SoundsRight offers.
Final Thought
The world is recording itself every second. Yet only a tiny fraction of that speech becomes usable for AI. SoundsRight sees a future where all that sound becomes intelligence fuel rather than wasted noise.
It is not just about cleaning audio. It is about unlocking the largest untapped dataset in human history: our voices.
The opportunity is not only technical. It is economical. The richest data is the one we hear every day. SoundsRight wants to turn it into value for the world.
Useful Resources
Official Website: https://soundsright.ai/
X (Formerly Twitter): https://x.com/soundsright_sn
GitHub: https://github.com/synapsec-ai/soundsright-subnet
Medium: https://medium.com/@SoundsRight/
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.
Be the first to comment