

When you think about trust in artificial intelligence, it’s easy to forget how much of it relies on faith. We type prompts into a model, get an answer, and simply assume it did the work correctly. But in a world where AI decisions can shape markets, policy, and identity, that assumption is starting to feel shaky.
That’s the problem Inference Labs set out to fix. Behind Bittensor’s Subnet 2, it is building a cryptographic layer of truth for machine intelligence. A system that doesn’t just generate answers, but proves they came from where they claim to.
In a conversation with Dan and Hudson, the team behind Subnet 2, Keith ‘Bittensor Guru’ Singery explored how their latest innovation, DSperse, could redefine the way AI models are verified, shared, and commercialized.
A Sound You Can Trust
Keith began by recalling a moment from earlier in their work — the analogy that stuck.
“It’s like hearing a Porsche drive by,” he said. “You don’t see what’s inside the engine, but you know what you’re hearing.”
Dan smiled. “Exactly. What we’ve done,” he explained, “is take that same concept to AI. You don’t have to look inside the model (its ‘engine’) to verify that it’s real. You just need to check its unique digital fingerprint.”
That fingerprint comes from zero-knowledge proofs (ZKPs) — cryptographic evidence that confirms a model’s output came from a specific source, without revealing its inner workings.
The Cost of Proving the Truth
“Okay,” Keith asked, “but how expensive is that truth?” Hudson leaned forward. “Right now, proving computations is costly. Even something as small as GPT-2 can take a hundred dollars’ worth of compute to verify on AWS. What we’re doing is bringing that cost down from dollars to cents — and eventually, fractions of a cent.”
That leap, he explained, comes from Dsperse, their latest innovation. It split complex computations into smaller, parallelized segments. Each one is handled by different miners across the network, cutting the overall workload dramatically.
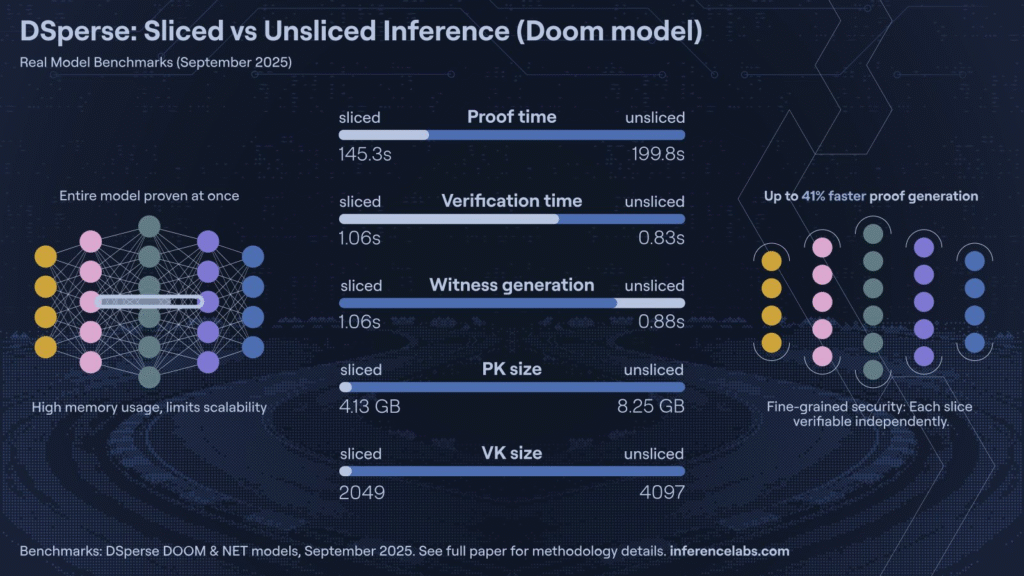
“In practice,” Dan added, “we’ve halved compute and memory requirements, and cut runtime by even more. It’s the same security, just smarter math.”
From Subnet to Supercomputer
The conversation shifted toward Omron (Subnet 2), their proving ground within Bittensor. Dan described it as a sandbox for experimentation: part research lab, part global competition.
“We’ve run over 300 million proofs through the subnet,” he said. “And what’s fascinating is how the network evolves. One miner even built a custom FPGA board to outpace everyone else. We thought something broke — turns out he’d just engineered his own advantage.”
That’s the power of Bittensor’s incentive layer. By rewarding miners for efficiency, the subnet turns competition into innovation. Faster proofs mean higher rankings, and higher rankings mean more rewards.
“It’s like natural selection for computation,” Hudson said, laughing.
Proofs, Competitions, and Real Use Cases
Keith asked how this competition model worked. Dan broke it down. “There are two sides. One is Prover-as-a-Service where miners generate proofs as fast as possible, helping us benchmark performance. The other is competitions, where miners create their own zero-knowledge circuits to replicate a model’s behavior.”
Their first test? Age verification. The challenge was simple: build a model that could estimate a person’s age from a selfie, but do it without sending the image to a central server!
Hudson explained how it worked. “Normally, companies send that image to their servers, which is risky. But with zero-knowledge proofs, we can verify the result locally, on-device, and just send a proof — not the photo. So you prove your age without revealing your identity.”
That’s huge for privacy compliance, especially in regions with strict data protection laws.
Turning Models Into Math
To illustrate how it works, Dan pointed to a familiar example. “Think about YOLO, the object detection model. It scans an image, recognizes objects, and labels them. We take that same process but convert every operation into math.”
Every neuron, activation, and connection is translated into a web of mathematical constraints. Those constraints must all check out for the inference to be valid.
“When they do,” Hudson said, “you get a proof — a kind of digital signature that says, yes, this exact model produced this result.”
“So the server never sees the image,” I clarified.
“Exactly,” said Dan. “It only gets the result and the proof. That’s the beauty of zero-knowledge — trust without exposure.”
Disperse: The Leap Forward
When the conversation turned to DSperse, the tone shifted — this was the part they were most excited about.
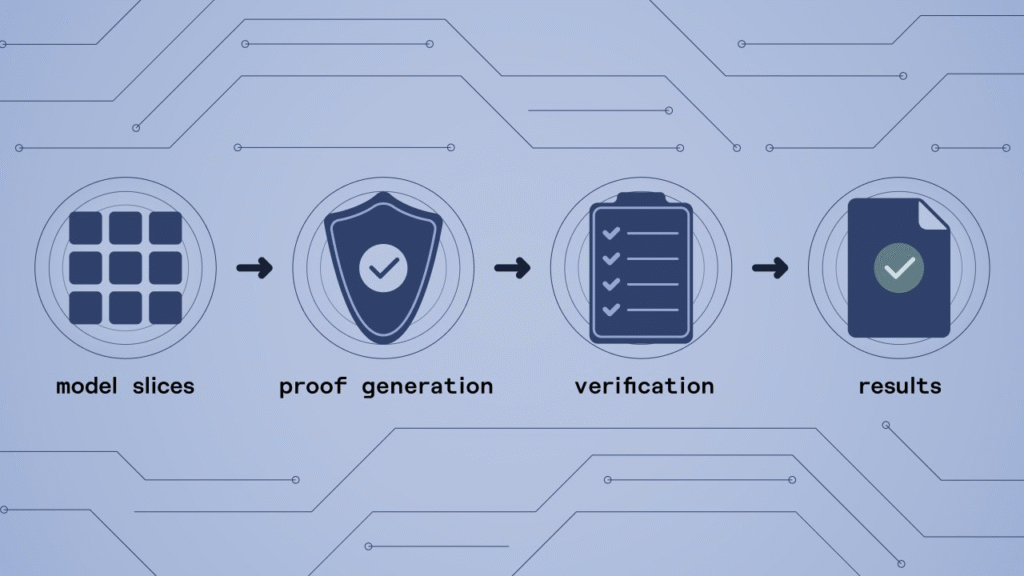
“With DSperse,” Dan said, “we can take a massive model (something that would normally need a supercomputer) and slice it into hundreds or thousands of pieces. Each miner runs a small part, proves it, and sends it back. Together, those pieces form a single, verifiable output.”
Hudson jumped in. “And it’s not just distributed inference — it’s parallelized. Every slice runs at the same time. What used to take a minute can now happen in a second.”
That’s when the term distributed inference came up — something, as Keith admitted, few had ever heard before.
“Distributed training is common,” Hudson said. “Distributed inference? That’s new. And we’re probably the first to pull it off.”
A Decentralized Supercomputer
To visualize it, Dan described the process like a branching tree. “Instead of one computer doing everything in a line, multiple miners work on separate branches simultaneously. They send their proofs back, we verify them, and the model continues. It’s computation and verification are happening hand in hand.”
What emerges, effectively, is a decentralized supercomputer that grows stronger with every new miner that joins.
“The incentive structure makes it self-optimizing,” Hudson added. “Every miner wants to be faster, cheaper, better. That collective effort becomes an engine for global computation.”
Protecting the Secret Sauce
But this technology isn’t just about efficiency. It’s also about ownership.
“Let’s say I’ve spent months fine-tuning a model,” Dan explained. “I’ve invested time, data, and expertise. If I hand that model over to a client, they can copy it and never pay me again.”
With DSperse, that changes. “Now I can send it as a compiled mathematical circuit. You can run it, get the results you need, but you’ll never see the inner workings. My weights and biases stay mine.”
Keith paused. “So you’re protecting your Intellectual Property (IP) not through patents, but through cryptography.”
“Exactly,” he said. “It’s like Digital Right (DRM) for intelligence, but without the restrictions.”
Proving Honesty, Not Just Accuracy
As we moved through examples, the conversation circled back to the trust problem. Hudson pointed out that even big AI providers struggle with verification.
“People assume they’re talking to GPT-4, but sometimes the system reroutes them to smaller models,” he said. “You’re paying for one thing and getting another.”
DSperse changes that. It allows a user to demand proof that they’re interacting with the promised model — no substitutions, no shortcuts.
“AI needs a layer of honesty,” Dan said. “We’re building that.”
KYC, Compliance, and Beyond
The team sees KYC as one of the first real-world applications. “In some jurisdictions, it’s illegal to store facial data,” Hudson explained. “Zero-knowledge proofs make it possible to verify identity or age without ever seeing the photo. It’s privacy and compliance in one.”
From finance to healthcare, the implications ripple outward. Imagine hospitals verifying diagnoses without revealing patient data, or governments proving authenticity without central databases.
“This isn’t theoretical anymore,” Dan said. “We’re already running these models on Subnet 2.”
Collaboration Across the Network
Inference Labs isn’t building DSperse in isolation. The team is already collaborating across the wider Bittensor network.
Hudson mentioned Taoshi (Subnet 8). “We delivered a ZK-proof for their trading metrics,” he said. “Now users can verify that their signals came from the top-performing miner, without exposing any proprietary data.”
Dan added that they’re also in discussions with other subnets, like Chutes and Targon, to bring verifiable inference to language and prediction models. “DSperse gives them the foundation to scale securely,” he said.
The Open-Source Ethos
Before wrapping up by asking what’s next. Hudson was optimistic. “By year’s end, I think we’ll see breakthroughs that take this from small to massive models — 70B, maybe even 400B parameters. And every improvement we make feeds back into the subnet.”
Dan nodded. “We’re open-source by design. Not everything we build is public right away, but all the foundational pillars will be. That’s how you grow a network of trust — by letting others build on it.”
Building a Trust Layer for AI
As our conversation wound down, one thing became clear: this isn’t just about faster AI. It’s about trusted AI.
For years, the field has obsessed over making models more powerful. Now, creators like Inference Labs are asking the harder question, how do we make them accountable?
When Keith asked Dan what drives them, he smiled. “Because it’s not enough for AI to be smart,” he said. “It needs to be honest.”And with Subnet 2’s quiet revolution unfolding behind the scenes, honesty might just become the next great frontier in artificial intelligence.
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment