

Special credit to Macrocosmos team for the full article below.
AI has reached a crucial turning point. In many high-risk domains, models are no longer limited by architecture, instead, they’re limited by the quality and difficulty of the data they are trained on. The next decade of progress won’t be driven by bigger models, but by more sophisticated, more adversarial, and more realistic datasets.
This shift has turned “training data” into its own global market. Analysts project tens of billions of dollars in spend over the coming years, and some of the highest-growth segments are tied directly to synthetic and domain-specific data.
Companies like Scale AI have built enormous revenue streams not by training models, but by creating and curating the adversarial datasets that models need in order to survive contact with the real world. Defense agencies routinely issue multi-million dollar contracts for biometric, spoofing, and identity datasets because they know that the world’s most important systems collapse when trained on the wrong data.
In other words, the real action is no longer in the model. It’s in the data that trains the model.

Yet even in industries that have embraced synthetic and adversarial datasets, none faces a threat landscape as dynamic, regulated, and adversarial as financial crime prevention. And this is exactly why Yanez MIID Subnet 54, a decentralized identity and adversarial data generation subnet within the Bittensor ecosystem, is uniquely positioned to become the foundational data layer for the sector.
By generating inorganic identities, deepfake-resistant biometrics, sanctions-variation, and structural adversarial KYC patterns at scale, MIID stands at the convergence of three explosive forces: the rise of deepfakes to challenge identity verification, the regulatory pressure for continuous validation, and the global shift toward decentralized AI ecosystems.
This is not theoretical. Yanez is already delivering the adversarial data infrastructures that banks, IDV companies, and compliance vendors cannot build for themselves — and regulators are beginning to expect.
What Other Industries Already Learned About Adversarial Data
If we look across industries that adopted AI early, a pattern emerges: the moment models hit real-world complexity, the only way to improve was to expose them to the kinds of data that rarely show up naturally.
Autonomous driving discovered this first. Companies like Waymo built massive “corner-case” datasets filled with the strange, rare, long-tail events, almost invisible in raw data, that actually determine safety: a pedestrian emerging at night from behind a truck, a scooter lying across a highway lane, a wrong-way driver speeding toward oncoming traffic. These edge cases represent a fraction of a percent of all driving, yet they dictate the reliability of an entire autonomous system. The industry realized it needed curated, adversarial scenarios to force models to handle what truly matters.

Cybersecurity reached the same conclusion. The most widely used intrusion-detection datasets are not collections of normal network traffic, but carefully engineered sequences of attacks designed to expose weaknesses in defense systems. Without those adversarial corpora, intrusion prevention models would remain blind to the very threats they’re meant to stop.
Even biometrics and deepfake detection now rely on adversarial datasets. Meta’s Deepfake Detection Challenge didn’t simply record videos; it hired thousands of actors and systematically attacked their identities using multiple generations of face-swap, GAN, and manipulation technologies. The ASVspoof challenges did the same for voice, creating entire libraries of spoofed speech designed to mislead biometric systems. These datasets have become the backbone of research because they reveal how models behave when confronted with intentional deception.
In every one of these fields, progress accelerated the moment adversarial datasets became available. It was never about giving models more data. It was about giving them the right kind of data: the difficult, manipulative, deceptive, low-frequency data that defines real-world risk.
Why Financial Crime Prevention Needs Adversarial Data
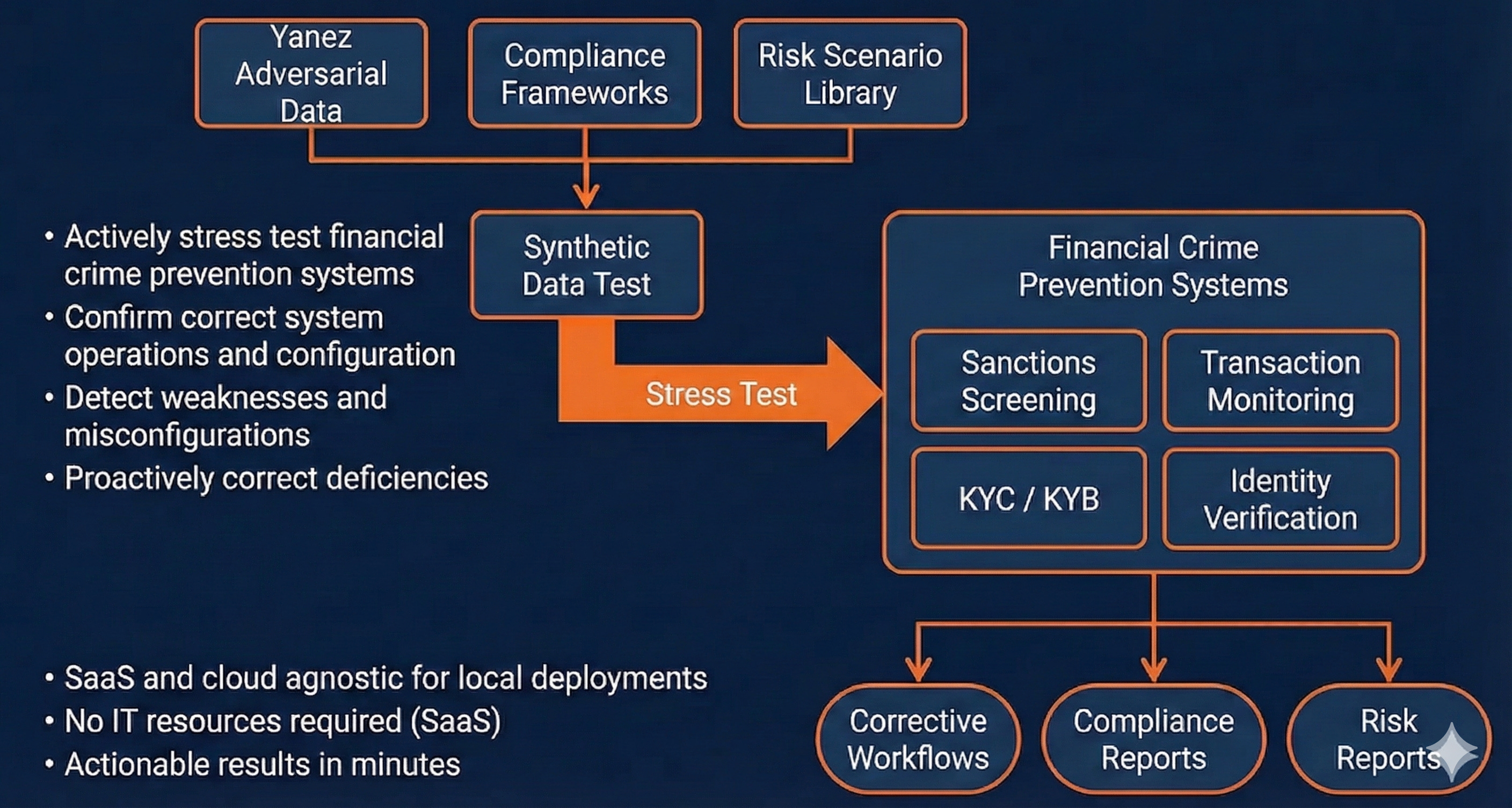
Financial crime prevention lives in the same complexity class, but its data problem is even harder. Fraudsters use deepfakes in onboarding flows. Sanctions evaders mutate identities across languages and jurisdictions. Document forgers exploit the tiniest weaknesses in verification systems. Synthetic identities blend together plausible attributes that slip past rule-based controls. And transaction patterns evolve faster than any historical dataset can capture.
The challenge is that real examples of these attacks are rare, confidential, and often legally unshareable. Banks and fintechs do not publish the deepfake attempts that bypassed liveness checks. They do not upload the forged documents that slipped into onboarding queues. They cannot exchange the PEP alias clusters or sanctions name variations that triggered system failures.
As a result, models in this industry are typically trained on safe, representative data. Therefore they perform well on safe, representative data. But real failures occur in the margin cases: the deepfake that almost worked, the identity pattern that blends multiple jurisdictions, the transaction cluster that imitates legitimate behavior, the sanction evader who uses subtle linguistic variations. These are precisely the cases that never appear in training data.
Synthetic adversarial generation solves this problem. It allows us to create inorganic identities that behave like real ones, construct document forgeries that mimic real attack vectors, generate sanctions and PEP variations that actually expose matching weaknesses, produce deepfake biometrics tailored to break existing models, and build transaction flows engineered to probe AML and KYC defenses. It provides what the financial crime industry has never had: a renewable, controlled supply of the attacks that matter most.
Why Continuous Adversarial Data Is the Only Sustainable Model
Unlike traditional datasets, adversarial data has a short half-life. Fraud evolves. Deepfake tools improve. Identity spoofing techniques spread. Sanctions regimes expand. Even the best models begin to degrade as the world shifts around them.
The financial crime industry is already moving toward regulatory expectations for continuous model validation. The OCC, NYDFS, FCA, and others increasingly expect banks to demonstrate not only that their models work today, but that they are regularly tested against new and emerging threats. The only way to satisfy that expectation is through continuous adversarial data: fresh synthetic identities, updated deepfake variants, newly observed evasion patterns, and regularly regenerated stress scenarios.
This fills the gap financial institutions have struggled with for decades: the inability to train and validate models on the kinds of threats that cause real-world failures.
And because MIID is decentralized, miners continuously generate novel adversarial data, validators score it, and the subnet evolves – creating an “attacker-versus-defender” dynamic that mirrors the real environment far better than static vendors.
This is not a one-time purchase. It is an ongoing requirement. Adversarial datasets must evolve in the same cadence as adversaries themselves.
The Opportunity Ahead
Financial crime prevention is one of the world’s biggest and most regulated technology markets. Banks collectively spend hundreds of billions every year on identity verification, AML, KYC, sanctions, and fraud defenses. Yet almost none of that spend goes toward the adversarial datasets that determine model resilience.
This gap represents one of the largest unclaimed opportunities in the ecosystem.
The industries that embraced adversarial datasets (autonomous driving, cybersecurity, biometrics) each saw breakthroughs only after high-quality adversarial data became available. Financial crime is now on the same path, but with far higher stakes and far faster adversaries.
Yanez is the first system built to meet this need. Its ability to generate identity-centric adversarial data at scale, including synthetic biometrics, sanctions variations, document forgeries, and synthetic identity clusters, makes it uniquely positioned to become the standard adversarial data layer for the entire industry. And because Yanez is decentralized and continuously evolving, its output naturally aligns with the subscription cadence regulators and institutions will require.
The opportunity is massive: continuous, subscription-driven revenue tied directly to model resilience, regulatory expectations, risk reduction, and institutional necessity. Yanez sits at the intersection of all of this: the right architecture, the right timing, the right threat landscape, and the right market.
Thanks to Jose Caldera, founder of SN54, for contributing. Follow @yanez__ai on X for the latest developments
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment