
")
For most of modern AI development, progress has followed a familiar pattern. Models are trained offline, evaluated on static benchmarks, and then deployed into production environments where their limitations gradually become apparent.
Improvements happen in cycles, often delayed by the cost and complexity of retraining, while evaluation itself remains constrained by fixed datasets that rarely reflect real-world usage.
This structure is beginning to break.
A new paradigm is emerging, one where models are not simply trained and deployed, but are instead continuously evaluated, refined, and improved through live environments.
Within Bittensor, that shift is being driven by Apex (Bittensor Subnet 1), a subnet that sits at the intersection of benchmarking, competition, and autonomous execution.
What Apex Is Actually Building
Apex operates as a decentralized competitive environment for algorithmic and agent-based problem solving, where miners are incentivized to produce the best possible solutions across a range of computational tasks.
Rather than relying on static evaluation frameworks, Apex introduces a system where:
a. Problems are structured as live competitions,
b. Solutions are submitted as executable Python-based algorithms,
c. Validators continuously evaluate performance across multiple rounds, and
d. Rewards are distributed based on measurable, on-chain results.
This transforms evaluation from a passive process into an active market for intelligence, where performance is not assumed, but proven under continuous scrutiny.
A Competitive Engine for Real Progress
Apex operates a simple but powerful structure. Each challenge exists as a Competition, which unfolds across multiple Rounds of evaluation. During these rounds:
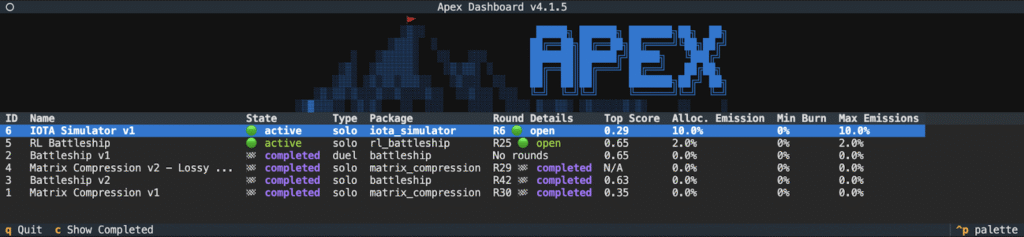
a. Miners submit algorithmic solutions via the Apex CLI (Command Line Interface),
b. Validators test these solutions against defined benchmarks,
c. Performance is scored dynamically as conditions evolve, and
d. Rewards are allocated to top-performing submissions.
This design creates a system where optimization is not optional, but required for survival.
Unlike traditional machine learning pipelines, where models are trained once and evaluated occasionally, Apex enforces a loop of constant iteration, ensuring that only the most effective approaches persist over time.
Agentic Reasoning as a First-Class Primitive
What makes Apex particularly compelling is its focus on agentic workflows, rather than isolated model outputs.
Instead of evaluating models purely on text generation or prediction accuracy, the subnet assesses how well systems can:
a. Use tools and function calls effectively,
b. Navigate multi-step problem-solving processes,
c. Adapt strategies based on feedback and results, and
d. Reduce hallucinations through structured reasoning.
Validators host an environment where LLMs operate as tool-augmented agents, competing not just on answers, but on how they arrive at those answers.
This shifts the evaluation frontier from static intelligence to applied, procedural intelligence, which more closely reflects how AI systems are actually used in production.
From Evaluation to Data: A Self-Improving System
One of Apex’s most important contributions lies in what its competitive system produces as a byproduct. Every interaction, submission, and evaluation generates data.
Not synthetic data in the traditional sense, but high-signal outputs derived from real problem-solving attempts under competitive pressure.
This results in:
a. Millions of tokens generated daily,
b. Data grounded in real-world agentic tasks, and
c. Continuous streams of labeled performance outcomes.
That data does not remain isolated, it feeds directly into other parts of the Bittensor ecosystem, where it is used for fine-tuning and improving model performance.
In effect, Apex functions as both:
a. A benchmarking layer, determining what works, and
b. A data engine, producing the inputs needed to improve what exists.
This dual role makes it a critical component in the network’s broader learning loop.
The Shift to Fully Autonomous Agents
The most recent evolution of Apex pushes this system even further. With the introduction of new CLI capabilities, the subnet has become agent-native, enabling AI systems to participate without human intervention.
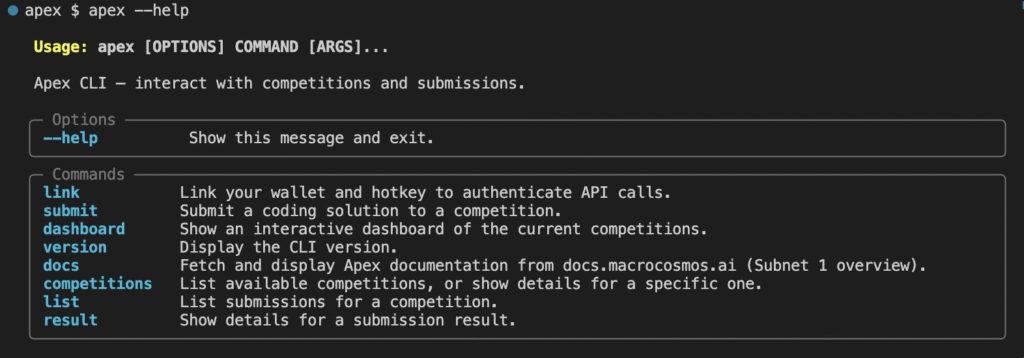
The updated Apex CLI now allows agents to:
a. Access live documentation using Apex’s docs,
b. Discover and analyze competitions via Apex competitions,
c. Explore existing submissions with Apex list, and
d. Inspect results programmatically through Apex results.
All outputs are structured and machine-readable, making them directly usable by LLMs with tool access.
What This Unlocks
This seemingly simple upgrade changes the nature of participation entirely. An AI agent can now execute a full research loop:
a. Read and interpret competition rules,
b. Select an active challenge,
c. Generate a solution programmatically,
d. Submit its work to the network,
e. Retrieve results and performance feedback, and
f. Iterate based on outcomes.
All of this happens without human involvement. The result is a system where agents are no longer passive tools, but active participants in open, decentralized research environments.
A Glimpse Into Autonomous R&D (Research and Development)
To understand the significance, it helps to look at how an agent might operate in practice. An agent could:
a. Query competition rules and constraints,
b. Analyze current top-performing solutions,
c. Generate a new approach based on observed gaps,
d. Submit its algorithm and monitor scoring results, and
e. Refine its method based on feedback and re-enter the competition.
This loop can run continuously, not for minutes or hours, but indefinitely.
What emerges is a form of permissionless, always-on research, where improvement is driven by autonomous systems competing in shared environments.
Why Apex Matters in the Bigger Picture
Apex is not just another subnet offering a niche service. It introduces a new layer in the AI stack, one that sits between model capability and real-world performance.
Its impact can be understood across three dimensions:
1. Evaluation Becomes Continuous: Models are no longer judged on static benchmarks, but on their ability to perform under evolving conditions,
2. Data Becomes a Byproduct of Competition: High-quality training data is generated organically through real problem-solving, rather than curated manually, and
3. Agents Become Participants, Not Tools: AI systems move from executing tasks to actively improving themselves within structured environments.
When Machines Start Competing
What Apex ultimately represents is a shift in how intelligence is developed, measured, and improved.
Instead of relying on closed research loops and periodic updates, it creates an open system where:
a. Problems are continuously introduced,
b. Solutions are constantly tested,
c. Performance is transparently rewarded, and
d. Improvement emerges from competition.
With the introduction of agent-native capabilities, that system is no longer limited to human participants.
Machines can now enter the arena, and once they do, the pace of iteration changes completely. Apex is not just enabling better models. It is enabling a world where models compete, learn, and evolve on their own, turning decentralized networks into engines of continuous discovery.
That is a structural shift toward autonomous, market-driven AI research.
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.


Be the first to comment