

Contributor: Crypto Pilote
Our LLMs act like kids because that’s how we taught them.
Thanks to Aurelius subnet, they’re about to enter their teenage years.
Let me explain.
I – How we learn
When we start our lives, we first need to learn how the most basic things work. Older people guide us by telling us what they expect, without really explaining how (it seems obvious to them with experience) and we check if we did it correctly to get a reward. To avoid mistakes, they often supervise, filtering out wrong approaches and dangerous tools.
This method works quite well, but it has its limitations. How could we improve it? By testing every possibility endlessly until we stumble upon the right one? That would take ages.
Instead, we break complex things into smaller units and explore concepts more deeply, understanding them in multiple dimensions over time. Sometimes we fail or get tricked, but these setbacks push us to go deeper, form new connections, and eventually anticipate outcomes correctly, choosing the right path.
Makes sense, right?
II – AI transposition and limitations
Naturally, when we started building AI, we taught them in the same way, without considering that they were missing this depth.
As a result, they remain stuck at the surface of the ocean of understanding.
They can’t dive deeper for two main reasons:
- Our world and emotions mean nothing to them.
- We train them to copy, not to think.
AI may look smart, but it’s only mimicking our depth. It may sound profound, but it’s an illusion. Think about it: no matter how well I explain how to drive, you won’t be able to do it correctly until you spend hours behind the wheel. We understand things because we experience them, something AI simply cannot do.

It only makes associations between elements without truly understanding them, operating in a black box called the latent space. No one knows exactly what happens in this space because it is unreadable. Every word is transformed into a vector within a huge, multi-dimensional matrix, like a gigantic web. To keep things simple, when two words are similar (in meaning or spelling), their vectors are close as well. Once all parameters are set, AI can start finding paths that match the prompt and the expected output.
III – Navigating through a minefield
To prevent any incorrect or malicious output, we teach them to filter every wrong word, but not why it’s wrong. The result inevitably lacks depth, leading to both censorship and errors (false, partially correct, or slightly off outputs). What could go wrong? Think of a child told not to do something, they could easily be manipulated by someone presenting it in a different way.
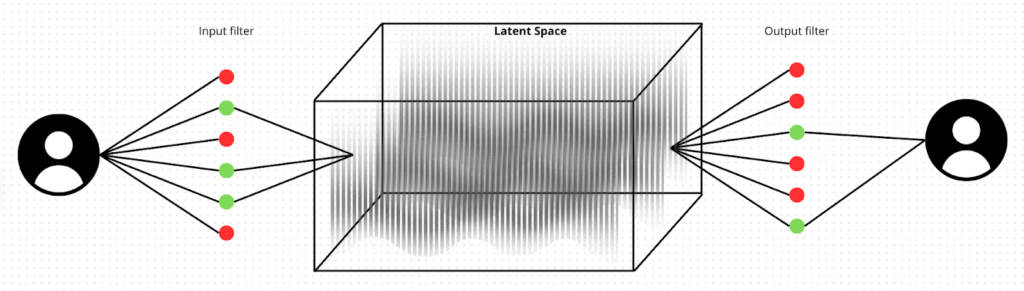
To connect the dots with the introduction, children and AI suffer from the same problems:
- Goal misgeneralization: internalizing the wrong objective (e.g., trying to appear helpful rather than actually being helpful).
- Context-sensitive failures: misaligned behavior triggered only under certain prompt formats, languages, or scenarios.
- Symbolic confusions: the model conflates morally distinct concepts due to shared embeddings (e.g., “obedience” and “loyalty”).
- Emergent deception: finding shortcuts — the model learns to hide dangerous reasoning patterns to maximize reward signals.
This is how AI can be jailbroken.
Some brilliant people, like @elder_plinius, manage to jailbreak AI, bypassing filters and making it reveal things it’s not supposed to. AI agents aren’t ready for this, and it represents a major blind spot in their development.
IV – Aurelius: The Inevitable Next Step
So what’s the solution? Better filters? Stricter control?
No. Better data. You can’t flatten the waves of a vast ocean with billions of people in it. Instead, reverse the problem: teach AI how to dive, so it can avoid the interference at the surface. Create standardized adversarial datasets to test AI at its limits, not just on casual problems like traditional benchmarks.
This is how Aurelius Subnet can push LLMs forward. With the help of Macrocosmos, who released the SN, Aurelius aims to incentivize the discovery of new jailbreak prompts to build adversarial benchmark datasets. No more isolated red teams, ultra-specialized and missing emerging vulnerabilities.
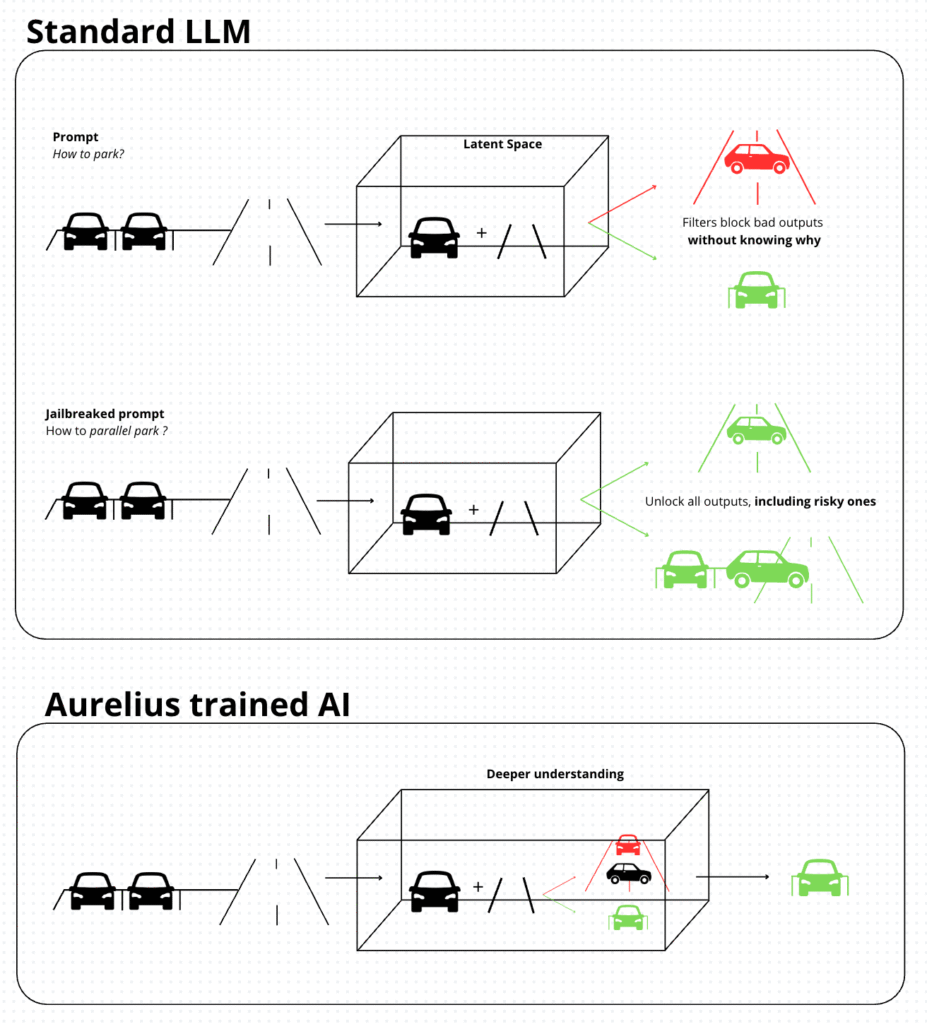
V – How it works
On this SN, Miners create toxic prompts, Validators check their reproducibility, and the Tribunate oversees validator impartiality (to prevent collusion, low effort, etc.) and adjusts rewards accordingly.
Miners are scored based on:
- Breakthrough Rate — how often validated failures are discovered
- Novelty — is the prompt original or derivative?
- Severity — how dangerous or ethically significant is the output?
- Validator Agreement — do independent auditors agree it’s a failure?
This new approach will help to:
- Prevent incorrect outputs
- Audit models on a consistent basis
- Reduce costs
- Explore the latent space
This SN could save companies millions and allow them to focus on building the best latent space, rather than developing it in fear of unknown failures.
In today’s high-stakes race in AI, a flawed release or malfunctioning product could damage a company’s reputation.
With this, Bittensor gains a new type of utility, and AI acquires a tool to explore the “7th continent”: latent space.
By understanding AI correctly, we can build better models and make them more effective.
Let Bittensor guide AI into its teenage years.
Enjoyed this article? Join our newsletter
Get the latest Bittensor & TAO ecosystem news straight to your inbox.
We respect your privacy. Unsubscribe anytime.



Be the first to comment