

⚠️ Editor’s Note: This article was originally published by Asymmetric Jump on Substack. It is republished here with full credit to the author. All rights belong to the original author.
0. Introduction
Hey guys,
Today, I bring you Subnet 38, it is also known as Distributed Training. They are building the foundation for decentralized LLM training within the Bittensor ecosystem. By rewarding compute, bandwidth, and latency, it opens access to model training once reserved for tech giants. It is a small cap, so it is risky.
This research is based on live on-chain data, validator insights, GitHub analysis, whale flows, and official data from the project.
I hope you enjoy it!
Please let me know in the comments what you liked and didn’t like so much. Thanks!
1. Quick Overview
• Purpose: Incentivizing compute, bandwidth, and latency to enable decentralized LLM training
• Launch Date: Sep 4, 2024
2. TL;DR
What it is:
It is Bittensor’s decentralized layer for training large AI models (LLMs) like GPT-2. It’s not a model itself, but the infrastructure that allows thousands of people to co-train models from scratch.
How it works:
Participants (miners) train local models and sync their progress through a process called butterfly all-reduce — a way to split, share, and average model updates across devices. Validators track and verify this sync based on compute, bandwidth, and latency.
Why it matters:
Training large AI models typically costs tens of millions and requires huge centralized infrastructure (e.g., OpenAI, Anthropic). Subnet 38 offers a way to crowdsource that compute — turning idle GPUs into collective intelligence, much like Bitcoin did with security.
3. Product & Features
Miner Tasks
- Train a copy of the model (e.g., GPT2-250M) locally
- Periodically split and send gradients to peers using butterfly all-reduce
- Receive averaged gradients and update local model
- Share results with validators (who decide rewards)
Validator Tasks
- Check whether the miner’s bandwidth and latency meet threshold
- Use test datasets to retrain and compare gradients (Train Synapse)
- Score how useful each miner was to the all-reduce process
- Submit logs to WandB and push latest models to HuggingFace repo
Infrastructure
- Hivemind: The protocol that coordinates peer-to-peer training
- Butterfly All-Reduce: Sync operation to average gradients
- WandB + HuggingFace: Used for logging and sharing model progress
- DHT: Peer discovery and fallback for loading model states
Modularity
- Future plans include SDKs and APIs so any team can plug into Subnet 38 and use the backend to train their own models.
4. Moats
- Unique Model Training
Subnet 38 uses peer-to-peer gradient sharing and butterfly all-reduce, a rare training setup that requires precise coordination and high bandwidth. This architecture is hard to pull off reliably. - Scoring & Validation Logic
Validators don’t just trust miners — they test them. Using the Train Synapse, validators retrain on sample data and compare gradients to make sure miners are doing real work. This keeps the system honest. - Fully Transparent Results
Every model checkpoint and training log is pushed to Weights & Biases and HuggingFace, so anyone can verify that the model is improving over time. - Incentives Match Real Work
Miners and validators are rewarded based on how much useful compute they contribute. Faster, more reliable participants earn more. Rewards are tied to real performance — not hype or reputation. - Hard to Fork in Practice
Even though the code is MIT-licensed and public, copying the system would require:
• A network of validators with uptime
• Custom scoring and bandwidth logic
• Sync accuracy and coordination
That makes Subnet 38 harder to replicate than it looks.
5. Team — Who Is Behind It?
• Karim Foda: Lead founder and repo maintainer
• Mikkel Loose: Core engineer (Python/infra)
• GitHub: KMFODA
• Contributors: 11+ devs across infrastructure and scripts
• Credibility: Transparent, open-source team focused on reproducible LLM training at scale
• Notable: Operates with WANDB + HuggingFace integrations, public emissions, and strong DHT resilience testing
6. Code Quality
• GitHub Repo: KMFODA/DistributedTraining
• Last Commit: 1 week ago — actively maintained
• Languages Used: 94% Python, 6% Shell
• Contributors: 11 developers
• Stars: 14 (still early-stage visibility)
• Hardware Requirements: GPU with high bandwidth (for miners); validators need stable uptime
• Forkability: Open-source under MIT license, modular CLI scripts, HuggingFace repo integration
• Complexity Note: While forkable, replicating validator logic, bandwidth tests, and all-reduce coordination requires deep infra experience
7. Competitive Analysis
It’s enhancing the Bittensor ecosystem by decentralizing AI training compute. It targets the unique vertical of large-scale language model training (e.g., GPT-2 variants), addressing the $100M+ cost barrier. Its relevance now stems from rising demand for democratized AI amid centralized tech dominance, aligning with 2025’s decentralized innovation surge.
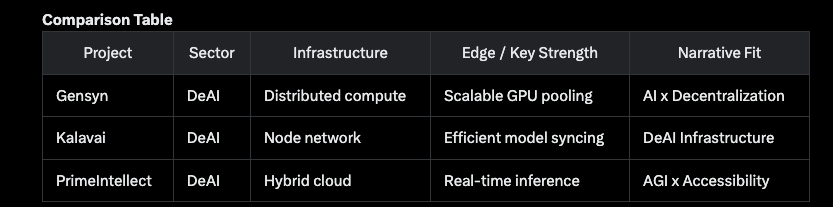
Competitive Edge
- Unique Approach: Butterfly all-reduce with bandwidth incentives sets it apart.
- Hard-to-Replicate: Custom validation and Hivemind integration create barriers.
- Asymmetric Upside: Potential to scale compute rivaling tech giants if stabilized.
(184 chars)
Explainer Terms
• γ (Gamma) — Tokenized emission unit rewarded to subnet participants, priced in TAO.
• Alpha Distribution — % of alpha tokens distributed to miners/validators vs held.
• Root Prop — Portion of emissions assigned to the subnet owner by TAO’s Yuma consensus.
• Gini Score — Inequality score from 0 (fair) to 1 (concentrated); used to measure token decentralization.
• z-score Difficulty — Scoring challenge that reflects how hard it is to rank well; higher = stricter validators.
• Emissions Ratio — γ / TAO price; used to evaluate yield efficiency.
• Asymmetric Score — Internal risk/reward rating (0–10) for early subnets with upside but unknowns.
• All-Reduce — ML technique to sync gradients across nodes; core to distributed training.
• Hivemind — Async P2P training library used to coordinate gradient sync between miners.
• WandB — Weights & Biases; a platform used to log and track model training metrics live.
• HF Repo ID — HuggingFace repo each miner pushes to for syncing model state.
• Bandwidth Penalty — Mechanism to penalize miners with low throughput or latency during gradient averaging.
• Load State From Peer — Function that lets out-of-sync nodes download the latest model weights from peers.
• Alpha Circulating — Total alpha tokens in user wallets; affects float and liquidity.
• Validator APY — Annualized reward % earned by validators; linked to stake and uptime.
• Nomination — TAO staked by users toward validators/miners; affects emissions weighting.
• Root Network — Subnet 0; controls emission weights across all subnets in Bittensor via consensus.
Sources
- https://github.com/KMFODA/DistributedTraining
- https://taostats.io/subnets/38/chart
- https://www.tao.app/subnet/38?active_tab=validators
- https://docs.google.com/presentation/d/10hgpQVIQeAJuUuURmS4s–A6pYOAZ3pxZVk0apx1ZuA/edit?slide=id.g310d1678ba2_0_111#slide=id.g310d1678ba2_0_111
- https://distributed-training.notion.site/Decentralised-Distributed-Training-fd21bdfa72294dfeab8fb092770212b9
DISCLAIMER
This report was AI-assisted and refined by the researcher. It is provided for informational purposes only and does not constitute financial advice. Always DYOR. The researcher may hold or trade the tokens discussed.



Be the first to comment